There are three major ways to reduce or even eliminate the “AI flavor” in AI-generated writing. I’ll discuss them in order of importance/priority. Master these three categories of techniques, and your ability in AI writing and controllability will definitely surpass that of most ordinary people.
Choose a better or more suitable model
Some people might think this is just stating the obvious, but that’s not the case. For most people who don’t know much about large language models, they aren’t clear about the differences in writing abilities among the most well-known ones. Moreover, these differences don’t just lie in basic writing capabilities. There are also significant distinctions in how well they follow instructions and their overall controllability.
Whether the written article has an “AI flavor” also depends greatly on the model’s own capabilities and scale, which are even the most critical factors. This is because the model’s capabilities determine the upper limit of its performance and also define the extent to which it can optimize and eliminate the “AI flavor.”
Therefore, the most widely applicable and prudent method is to choose a large model with the strongest comprehensive capabilities. However, if the content you are writing has a very clear tendency, then selecting a model that best matches your writing content is also a good choice.
If you’re unsure about the differences in writing capabilities among well-known large models, here are some of my top recommendations. Since I can’t conduct very rigorous tests, the ranking is relatively subjective, but it still has strong reference value. You can use it as a guide for testing. (The following rankings are based on models I am quite familiar with and reflect their performance under default, unadjusted parameters. Models I am not familiar with are not included in this ranking.)
First Tier: Gemini-2.0-Flash-Thinking-Exp-01-21, Claude 3.7, Grok 3 (ranked in order)
Second Tier: Deepseek R1, Deepseek V3, ChatGPT 4o (ranked in order)
The above echelon division is an evaluation that takes into account factors such as writing ability and controllability. It is highly subjective but has a certain reference value.
The writing ability of large models is indeed a very mysterious thing, even more so than their reasoning ability.
This is because reasoning ability can often be assessed through objective tests. In terms of mathematical and logical skills, it’s clear-cut: either the model has it or it doesn’t.
However, evaluating the writing ability of large models is much harder due to its strong subjectivity. That said, there are indeed noticeable differences in writing capabilities among different large models. A general trend is that the larger the model, the better its writing ability.
Writing is a highly generalized task that requires not only basic language expression but also a broad knowledge base, a rich repository of associative materials, and a nuanced emotional sensitivity. Often, the “AI-like” feel in AI-generated articles stems from those very subtle aspects, such as the rhythm of the writing and the expression of psychology and emotions. These details are precisely where AI struggles to fully replicate human writing.
The above rankings and tier recommendations are only a general evaluation of the writing capabilities of large models. Regarding which specific types of writing each large model is better suited for, I will provide more detailed analyses and suggestions after conducting further in-depth evaluations.
Parameter adjustment
In large language model writing applications, parameter tuning is the second most important consideration after model selection. The same model may exhibit vastly different writing abilities and styles under different parameter settings.
Of course, all of this still presupposes the performance of the model itself. Parameter tuning cannot exceed the model’s inherent capabilities, but it can optimize the output results as much as possible within the scope of its performance, reducing any “AI-like” flavor or making the output closer to the style you desire.
1. Principle of Parameter Adjustment
The explanations of several parameters are as follows (the following is a technical explanation, which may seem a bit stiff. Those who want to understand it in a more straightforward way can skip to the table later).
- Temperature: Controls the randomness of the model’s output. A higher value (e.g., 1.5) makes the model more likely to choose lower-probability words, generating text that is more creative but potentially more chaotic; a lower value (e.g., 0.2) makes the model prefer higher-probability words, resulting in more deterministic and conservative output.
- Top-p: This method samples from the set of words whose cumulative probability reaches p, rather than fixedly selecting the top k highest-probability words.
- Top-k: This method restricts sampling to only the top k candidate words with the highest probabilities during each generation, ignoring other lower-probability words.
- Frequency Penalty: Controls the penalty applied by the model to repeated words, reducing the probability of repeated words during generation. The higher the value, the less likely the model is to repeat the same word.
- Presence Penalty: Controls the overall penalty applied by the model to words that have already appeared, reducing the probability of previously seen words reappearing, regardless of how many times they have occurred.
A more intuitive explanation is as follows:
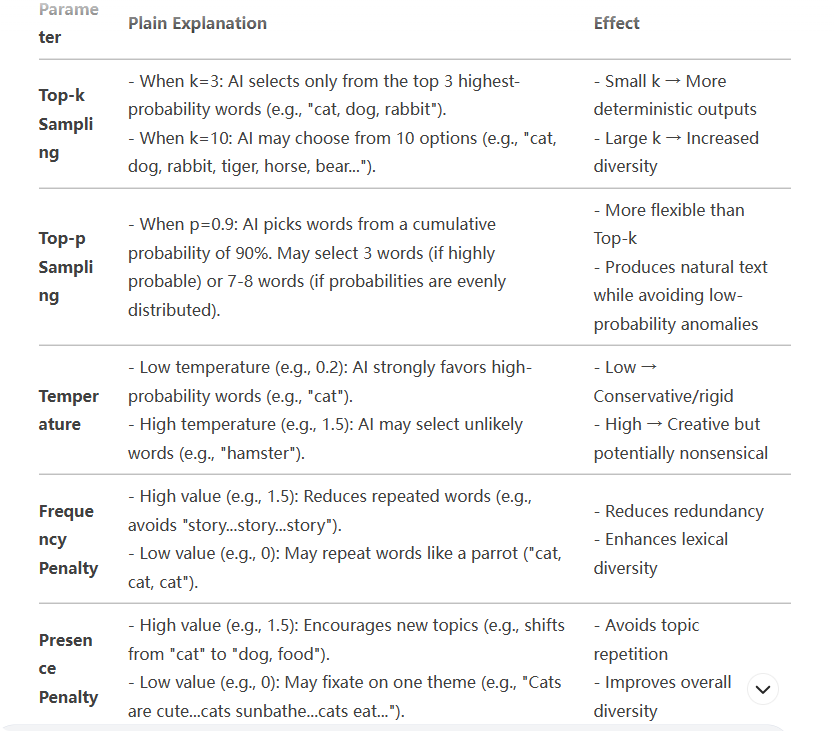
Among these parameters, the most important and common ones are “Temperature” and “Top-p sampling”. They have a significant impact on the diversity, writing style, and tone of the generated text.
The overall adjustment methods for the two most commonly used parameters, Temperature and Top-P, are:
- Temperature: The randomness of the text generated by the model. The larger the value, the more diverse, creative, and random the response content will be; set to 0 to answer based on facts.
- Top-P: The smaller the value, the more monotonous and easier to understand the AI-generated content will be; the larger the value, the broader the vocabulary range of the AI’s response, making it more diverse.
2. Usage
The first type of method is to use model aggregation writing tools.
Generally speaking, the web version and APP version provided by most large model manufacturers do not allow direct adjustment of the above parameters. If you want to adjust these parameters, you can either use the API provided by the large model manufacturer or visit some special model trial web pages.
All we need to do is log in to the official websites of these large models, register an account, deposit some money, and obtain our own API interface. Then, simply fill in the API into the designated locations of these tools. No knowledge of coding is required at all.
The second type of method is through the trial operation window provided by the cloud service provider.
Generally speaking, however, this writing tool only supports the adjustment of these two parameters. If you want to adjust other more complex parameters, there are two methods: One is to call the large model’s API through code and modify these parameters in the calling code. The other method is to use the trial operation window provided by some large model aggregation cloud service providers. In these windows, you can also adjust more complex output parameters, thereby achieving more precise control over the text style to obtain results that better meet your needs. The former method of modifying these parameters by calling the API through code will not be introduced here, as those who understand it will naturally grasp it without the need for further explanation.
Another way, which is quite convenient, is to use some large models and aggregate the trial operation windows provided by cloud service providers to adjust parameters. For example, as shown in the figure below, the model trial window provided by SiliconFlow allows you to adjust more complex parameters such as Frequency Penalty.
The third type of method is through prompt words.
The third way to modify these parameters is to directly communicate with the model through prompt words. For example, you can first ask a question and then add in parentheses after the question (set Temperature to **, set Top-P to **). This can also play a certain role in adjusting these two parameters to some extent.
Although from the perspective of API calls, these two parameters have not actually changed, large language models are different from the rigid machine languages of the past. To some extent, they can understand the meanings of these two parameters you mentioned and proactively make certain adjustments through their own intelligence. Therefore, although this effect is not as precise as directly adjusting the parameters, it can still achieve a similar result.
Moreover, this method of adjusting parameters through verbal communication is easier for machines to understand and more intuitive, especially compared to vague instructions like “make the language more plain” or “make the language more elegant.”
For example, when you find that the output style of the model is overly exaggerated, instead of saying “Please make the style more plain,” it is better to directly say “Reduce the temperature from 1 to 0.8.” If the result is still unsatisfactory after the adjustment, you can further specify, “Please adjust the temperature from 0.8 to 0.5.” This way, you can provide the model with more accurate and actionable tuning instructions, making it more effective to adjust the style.
Of course, it’s important to remember that whether you directly modify these parameters or indirectly adjust them through prompts, it cannot replace the influence of appropriate prompts on the writing style. This is because the range of these parameters cannot cover all the content that language can express. When adjusting the style through language to guide the model, we can express the effects we truly want in a more diverse and richer way.
Usage instructions / Remove the AI flavor with reference to the article
I mentioned just now that for large language models, prompt words can often play a role similar to fine-tuning parameters, and can even bring about a broader range of stylistic changes than parameter tuning. For example, you can use prompt words to make the articles generated by the AI more beautiful, more imaginative, or more straightforward, etc. By continuously adjusting the prompt words, the generated articles can be progressively improved and ultimately aligned with the direction you desire.
However, prompt words also have significant limitations. If a large language model itself generates text of insufficient quality, lacks a “human touch,” or has limited capabilities, then no matter how many times you use prompt words, it can only produce text that is closer to the style you want but still carries an “AI flavor,” and it can never truly eliminate the “AI flavor.”
In addition, due to the relatively imprecise prompt words, it is impossible to precisely control the generated article. Therefore, compared with directly adjusting parameters, there are also some other limitations.
Besides using prompt words, directly providing an AI with a sample essay as a reference is also a good method. In this case, the sample essay serves as a lengthy prompt word, which can more intuitively guide the AI to generate content that matches your expected style.
Summary:
From the current capabilities of large language models, it is impossible, at least for now or in the near future, to completely eliminate the “AI tone” and achieve a level where it is indistinguishable from human-written articles in blind tests. Especially when human articles deliberately showcase personality and liveliness, AI-generated writing often appears stiff and rigid by comparison.
The main reason lies in the fact that humans are highly subjective and self-aware individuals. Each person has their own unique characteristics, and they can also deliberately make their writing full of randomness and uniqueness. In essence, a large language model is a text generation machine based on probability. No matter what requirements you put forward or what parameters you modify, it is still just an average probabilistic outcome lacking in personality and contingency.
For AI writing to truly surpass the best and top-notch humans, I personally believe it will be more challenging than in the field of mathematical logic. Perhaps by the end of this year or early next year, with the help of reinforcement learning, large language models might outperform all humans in the programming domain, and even defeat all human competitors in Olympiad problems. However, for large language models to surpass all humans in the writing field, I personally think it will be even more difficult, and such a prospect seems unlikely for quite a long time to come.
However, the reason why my interest in AI writing has surged in the past one or two months is that several newly released large models have significantly improved their writing capabilities compared to previous ones. I feel that AI writing has reached a critical point—a potential tipping point for exploring commercial applications. Perhaps it won’t truly match the level of human writers in the next few years, but it doesn’t necessarily need to. As long as it can surpass the abilities of most ordinary people and truly eliminate the “AI feel” to achieve commercialization, it will have its own unique value.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts



No comments yet...