Llama 4 – Meta’s open-source multimodal AI model series, reclaiming the throne of open-source.
What is Llama 4?
Llama 4 is an open-source multimodal AI model series by Meta. It adopts a Mixture of Experts (MoE) architecture for the first time, delivering higher computational efficiency during both training and inference. Currently, Llama 4 has two versions: Scout and Maverick.
Scout features 17 billion active parameters, 16 “expert” models, and a total of 109 billion parameters. It supports a context length of 10 million tokens, can process videos over 20 hours long, and is capable of running on a single H100 GPU. Its performance surpasses models such as Gemma 3.
Maverick has 17 billion active parameters, 128 “expert” models, and a total of 400 billion parameters. It excels in accurate image understanding and creative writing, making it suitable for general-purpose assistants and chat applications. It ranks second on the large model LMSYS leaderboard.
Llama 4 Behemoth is a preview version currently under training. It boasts 2 trillion parameters and demonstrates excellent performance on STEM benchmark tests.
Llama 4 has been pre-trained on 200 languages and supports open-source fine-tuning. Its training data exceeds 30 trillion tokens.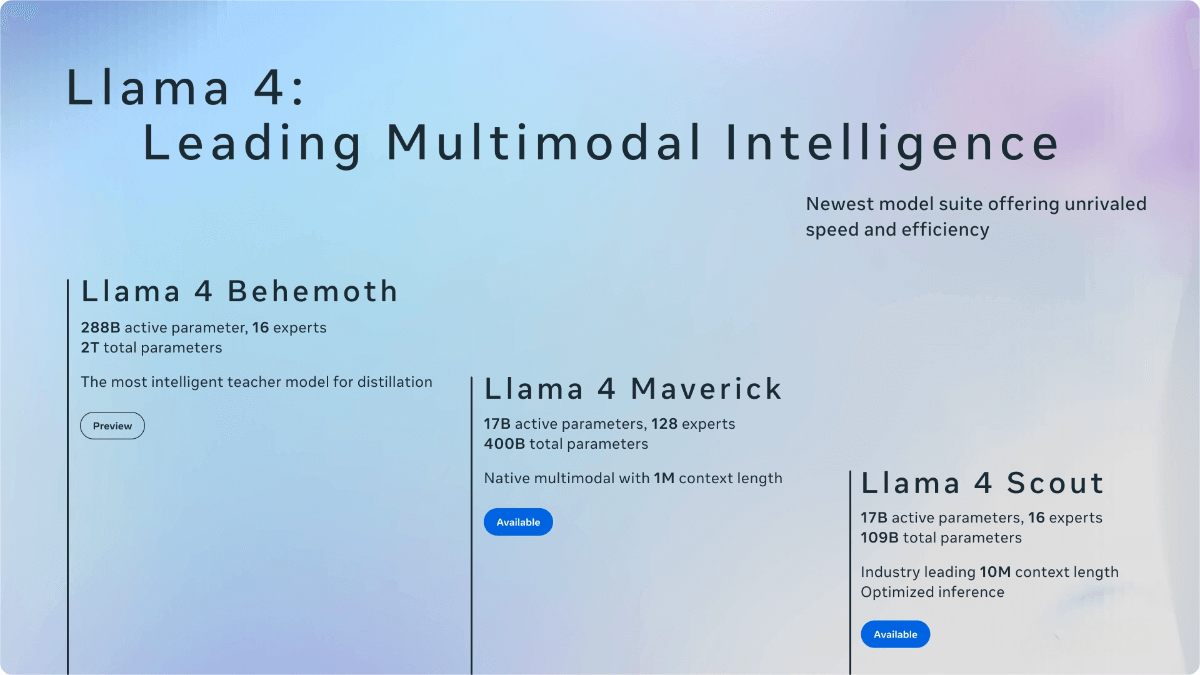
The main functions of Llama 4
- Powerful Language Understanding and Generation Ability: Trained on a vast amount of text data, it demonstrates precise language understanding. It can generate coherent and logical text, making it suitable for creative writing, article drafting, conversational interaction, and more. For example, when creating stories, it can generate rich and vivid content based on given themes and plot clues. In conversational scenarios, it can understand user intentions and provide appropriate responses.
- Multimodal Processing Ability: Trained on image data, it possesses image understanding capabilities, enabling it to recognize objects, scenes, colors, and other elements within images. It can also describe and analyze image content. The Scout version supports a context window of up to 10 million tokens, allowing it to process tens of millions of words of text. This makes it ideal for tasks such as summarizing long documents or reasoning over large codebases.
- Efficient Reasoning and Computational Ability: Adopting a Mixture of Experts (MoE) architecture, the model divides itself into multiple “expert” sub-models, each specialized in specific tasks. This design improves efficiency during training and when answering user queries, reducing model service costs and latency while enhancing reasoning speed.
- Multilingual Processing Ability: Pre-trained on 200 languages, it can process and generate text in multiple languages. It supports cross-language communication and tasks such as language translation, analysis, and generation of different languages, helping users overcome language barriers.
The Technical Principles of Llama 4
- Mixed Expert (MoE) Architecture: Llama 4 is the first model in the Llama series to adopt the MoE architecture. In MoE models, individual tokens only activate a small subset of the total parameters. For example, among the 400 billion total parameters of the Llama 4 Maverick model, 17 billion are active parameters. To improve inference efficiency, Meta has alternated between dense layers and MoE layers. The MoE layer utilizes 128 routing experts and one shared expert. Each token is sent to the shared expert and also to one of the 128 routing experts. In this way, only a portion of the parameters are activated during model execution, enhancing inference efficiency and reducing the cost and latency of model serving.
- Original Multimodal Design: Llama 4 is a native multimodal model that employs early fusion technology, seamlessly integrating text and visual tokens into a unified model framework. It can be pre-trained using vast amounts of unlabeled text, image, and video data. Meta has upgraded Llama 4’s vision encoder, which is based on MetaCLIP. During training, the encoder is trained separately from a frozen Llama model, enabling better adjustment of the encoder to better adapt to large language models (LLMs).
- Model Hyperparameter Optimization: Meta has developed a new training method called MetaP, which can more reliably set key model hyperparameters, such as the learning rate and initialization scale for each layer. These hyperparameters can be well adapted to different batch sizes, model widths, depths, and amounts of training tokens.
- Efficient Model Training: FP8 precision is adopted, ensuring high model FLOPs utilization without sacrificing quality. For instance, when pre-training the Llama 4 Behemoth model with FP8 precision and 32K GPUs, a performance of 390 TFLOPs per GPU was achieved. The training data contains over 30 trillion tokens, covering text, image, and video datasets. The model is further trained using the “mid-training” approach, expanding long contexts with specialized datasets to enhance core capabilities. This unlocks a leading 100 million input context length for Llama 4 Scout.
- Post-training Process Optimization: The training process follows the sequence of lightweight supervised fine-tuning (SFT) > online reinforcement learning (RL) > lightweight direct preference optimization (DPO). To address the potential issue of SFT and DPO overly constraining the model, Meta uses the Llama model as an evaluator, removing over 50% of the data labeled as “easy” and performing lightweight SFT on the remaining more difficult data. In the multimodal online RL stage, more challenging prompts are carefully selected, and a continuous online RL strategy is implemented, alternating between model training and data filtering to retain prompts of medium to high difficulty. Finally, lightweight DPO is performed to balance the model’s intelligence and conversational ability.
The project address of Llama 4
- Project official website: https://ai.meta.com/blog/llama-4
- Hugging Face Model Hub: https://huggingface.co/collections/meta-llama/llama-4
Application scenarios of Llama 4
- Dialogue System: Llama 4 can be used to build intelligent chatbots, such as Maverick, which is suitable for general AI assistants and chat applications. It can understand user questions, generate natural and fluent responses, and provide information, answer questions, have casual conversations, etc.
- Text Generation: Capable of creative writing, such as creating stories, poems, scripts, etc. It can be used for drafting news reports, product descriptions, copywriting, and other tasks, generating high-quality text based on given themes and requirements.
- Code Generation and Assistance: It can help developers generate code, producing corresponding code snippets or complete programs based on functional descriptions. It also provides auxiliary features such as code explanation, comment generation, and code style checking to improve development efficiency.
- Code Understanding and Analysis: Scout can perform reasoning based on large-scale codebases, assisting developers in understanding the logic and functionality of complex codebases. It can be used for tasks such as code review and vulnerability detection.
- Image Understanding and Description: Maverick excels in precise image understanding, capable of identifying elements within images such as objects, scenes, and colors. It can describe and analyze image content; for example, given a photo, it can describe the content and determine the possible shooting location.
- Information Retrieval and Recommendation: Combining its language understanding and generation capabilities, it can be used in information retrieval systems to understand user query intentions and provide more accurate search results. It can also deliver personalized recommendations based on user interests and behaviors.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...