
If you don’t understand the principle of RAG, you will always be just a document porter.
Let’s talk about RAG today! If you’ve already mastered the principles of RAG, please help me check if what I’m about to explain aligns with your understanding. Recently, low-code platforms like Coze and Dify have made RAG features increasingly accessible. However, to truly master it, understanding the underlying process is key—no more being a document copier! Today, I’ll walk you through the RAG system step by step and explain in the easiest way possible how it makes large language models (LLMs) smarter and more thoughtful.
RAG System: The Secret Weapon of Intelligent Q&A
What is a RAG system? Simply put, it’s like a super-capable “knowledge butler”: on one hand, it digs out the “essentials” you need from a vast amount of external materials; on the other hand, it uses the “language magic” of large language models to organize these essentials into clear and natural responses. The charm of RAG lies in its “retrieval + generation” combination—like a dynamic duo—that transforms intelligent Q&A from cold, mechanical replies into warm and reliable conversational experiences. Next, let’s open the “magic book” of RAG and take a closer look at how it works step by step.
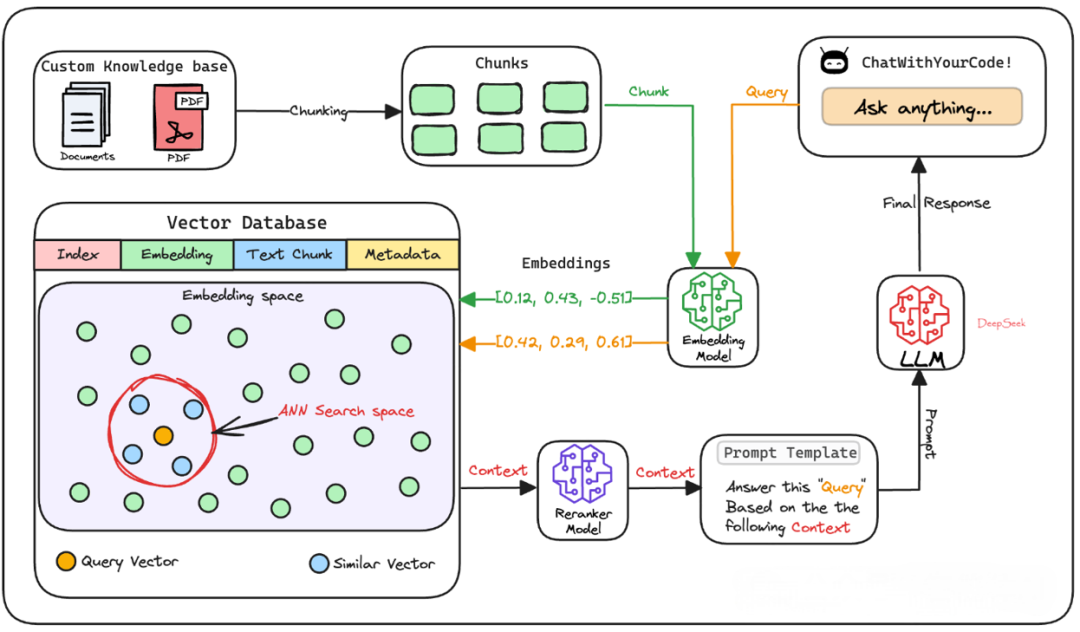
The core link of the RAG system
Simply put, a RAG system is a combination of “retrieval + generation.” It can dig out useful information from vast amounts of external knowledge and, leveraging the linguistic talent of large language models, organize this information into clear and natural responses. Imagine it as a knowledgeable and eloquent friend who can not only find the content you need but also present it in the most comfortable way for you to understand.
Next, let’s break down the working process of the RAG system and see how each step is connected.
1. Text blocking: Divide a big book into small pages.
Suppose you have a super thick book filled with knowledge, but it’s too troublesome to search for information by flipping through the entire book every time. Therefore, the first step is to break this book into small chunks of pages, which is “text chunking”.
Why do we do this? There are three reasons:
• The document is too large to process easily. Some materials may be hundreds of pages long. If we directly throw them in for analysis, our computers won’t be able to handle it.
• The model has a length limit. Just as we need to eat one bite at a time, an embedding model can only process a limited amount of text at a time.
• It’s convenient to find the key points. If an entire book only has one tag, it will be very difficult to accurately find relevant content when searching.
Therefore, text chunking is like “slicing” knowledge to make the subsequent steps go more smoothly.
2. Generate embeddings: Put a “label” on each page of the book
After dividing the text into blocks, we need to attach a special “label” to each text block. This label is actually a string of numbers called an “embedding vector”. The tool for generating this vector is the embedding model, which can condense the meaning of the text into numerical form.
For example, this is like assigning a unique “fingerprint” to each page of a book. Through this fingerprint, we can quickly determine what the page is about. Later, when searching for information, we can quickly match it using these fingerprints.
3. Vector Database Storage: Build a “Memory Warehouse”
With these digital fingerprints, we need to find a place to store them, which is where vector databases come into play. You can think of it as the “memory warehouse” of the RAG system, filled with the fingerprints and original content of all text blocks.
This warehouse is more than just a storage locker. It can also receive new materials at any time to keep knowledge updated. In the future, when users ask questions, the system will dig out the most relevant “memories” from here to answer them. The vector database not only stores digital fingerprints but also retains the original text and some additional information for easy retrieval.
4. User enters the query: Time to ask questions!
Alright, the preparatory work is done. Now it’s the user’s turn. The user enters a question, such as “What is a RAG system?” —— This officially kicks off the query phase.
5. Query Vectorization: Questions also Need a “Fingerprint”
To find the answer, we need to turn the user’s question into a digital fingerprint as well. We’ll use the same embedding model, so that the question and the text blocks in the database can have a “common language” and match with each other.
6. Retrieve similar blocks: Dig out the most relevant materials
Next, the system will take the fingerprint of the question and find the “most similar” text block in the vector database.
Specifically, it will pick out K most similar blocks (K is a pre-set number). The answers to the questions are very likely hidden in these blocks. This step usually uses a method called “Approximate Nearest Neighbor Search”, which is as fast as lightning.
7. Result Re-sorting (Optional): Make a further selection carefully.
Sometimes, in order to make the answers more reliable, the system will re-rank the retrieved text blocks. This is like picking out the most appropriate ones from a pile of answers. Usually, a more powerful model (such as a cross-encoder) is used for scoring and ranking. However, not all RAG systems do this. Many only use the similarity results from the previous step.
8. Generate the final response: The answer is freshly out.
Finally, hand over the selected text blocks to the large language model. The model will combine the user’s question with this information according to a template, generating an answer that is both accurate and natural. The whole process is like a chef cooking: the ingredients are the retrieved knowledge, the heat is the language proficiency of the large language model, and what is finally served on the table is a delicious answer.
Summary
After going through these 8 steps, does the full picture of the RAG system become much clearer now? It perfectly combines external knowledge with the capabilities of large language models through text chunking, embedding generation, vector storage, and retrieval generation. And what’s the result? Users can not only get answers but also receive more comprehensive and thoughtful information.
The three trump cards of RAG:
• Knowledge Freshness: Update the database at any time, ensuring the answers are always up-to-date.
• Reliable Answers: The retrieval mechanism ensures no nonsense.
• Extremely Versatile Uses: Intelligent customer service, learning assistant, applicable everywhere!
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...