
AI Goes Godlike! Unedited, Single-Take 60-Second ‘Tom and Jerry’ Clip Draws Millions of Views Online!
In the past two days, the AI short film of *Tom and Jerry* jointly produced by institutions such as the University of California, Berkeley, Stanford University, and NVIDIA has gone viral.

The “Tom and Jerry” short film series consists of five episodes, each with a brand-new story. You can view the corresponding story synopses and complete prompts on the project homepage.

Project Homepage: https://test-time-training.github.io/video-dit/
How about it? If not informed in advance, can you tell that they are generated by AI?
According to Gashon Hussein, another co-first author of the paper, in order to achieve realistic animation effects, they utilized the TTT (Test-time Training) layer to enhance the pre-trained Transformer and performed fine-tuning, thereby generating a one-minute “Tom and Jerry” short film with strong coherence in both time and space.
It is particularly noteworthy that all videos are directly generated by the model in one go, with no secondary editing, splicing, or post-processing involved.

Gashon Hussein further explained the technical principles behind it.
The TTT layer is a specialized RNN layer, where each hidden state represents a machine learning model. Additionally, updates within these layers are accomplished using gradient descent. In this paper, the TTT layer is integrated into a pre-trained Diffusion Transformer, and subsequently, the model is fine-tuned on long videos using text annotations. Moreover, to manage computational complexity, self-attention is restricted to local segments, while the TTT layer efficiently handles global context with linear complexity.
In addition, to efficiently implement the TTT-MLP kernel, this paper develops an “On-chip Tensor Parallel” algorithm, which specifically includes the following two steps:
- Partition the weights of the hidden state model among the GPU Streaming Multiprocessors (SMs);
- Utilize the Hopper GPU’s DSMEM feature to perform efficient AllReduce operations across SMs, significantly reducing data transfer between global memory (HBM) and shared memory (SMEM), and ensuring that large amounts of hidden states can be effectively accessed within SMEM.
Figure 3 below shows an overview of the method. On the (left), the architecture modified in this paper adds a TTT layer with a learnable gate after each attention layer. On the (right), the overall pipeline creates an input sequence composed of 3-second segments. This structure allows the local application of self-attention layers on the segments and the global application of TTT layers across the entire sequence.
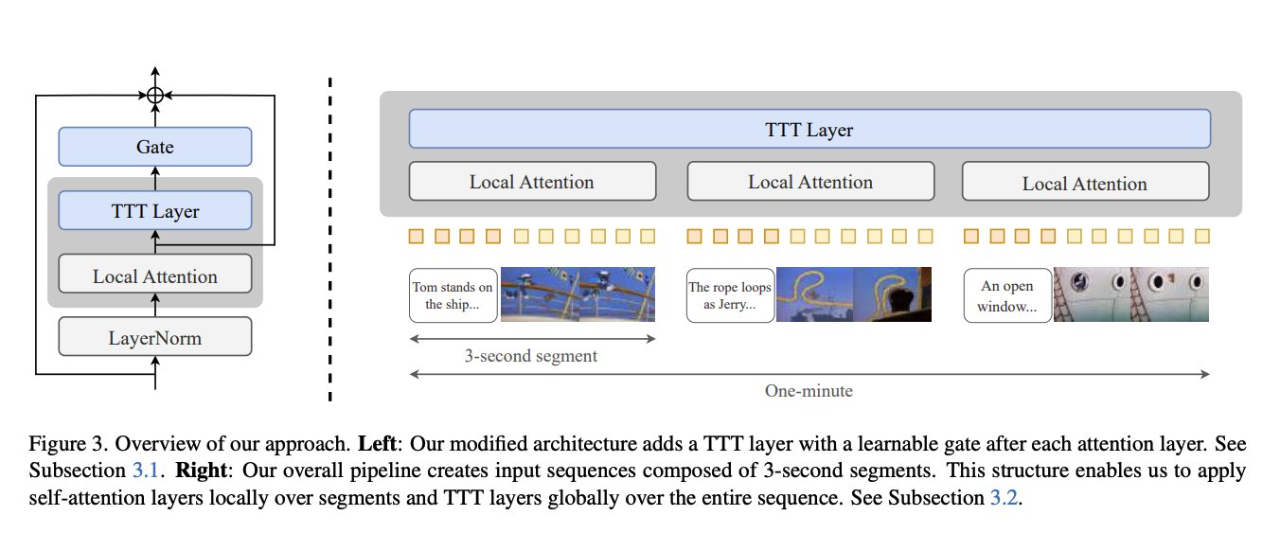
The specific implementation process is as follows:
In this study, the researchers started with a pre-trained DiT (CogVideo-X 5B) model, which could only generate a 3-second short video at 16 frames per second (or a 6-second short video at 8 frames per second). They then added TTT layers initialized from scratch and fine-tuned the model to generate one-minute videos from text storyboards. To keep the cost manageable, the self-attention layers were restricted to 3-second segments. With only preliminary system optimizations, the training process required approximately 50 hours on 256 H100 GPUs.
This research has drawn gasps and praise from a host of netizens in the comments section.
Research details
In the paper “One-Minute Video Generation with Test-Time Training,” researchers from institutions such as NVIDIA and Stanford introduced additional technical details behind the generation of the “Tom and Jerry” short video.

- Title of the thesis:One-Minute Video Generation with Test-Time Training
- Paper address:https://arxiv.org/pdf/2504.05298
The fundamental challenge behind the limitations of previous video generation technology lies in long context. This is because the cost of the self-attention layer in Transformers increases quadratically as the context length grows. This challenge is particularly prominent when generating dynamic videos, as the context of dynamic videos cannot be easily compressed by tokenizers. Using a standard tokenizer, a one-minute video requires over 300,000 context tokens. Based on self-attention, generating a one-minute video takes 11 times longer than generating 20 clips of three seconds each, and the training time also increases by 12 times.
To address this challenge, recent research on video generation has explored RNN layers as an effective alternative to self-attention, given that the cost of RNN layers grows linearly with the context length. Modern RNN layers, particularly variants of linear attention such as Mamba and DeltaNet, have achieved impressive results in natural language tasks. However, we have yet to see long videos generated by RNNs that feature complex narratives or dynamic actions.
The researchers of this paper believe that the videos generated by these RNN layers have relatively low complexity because their hidden states have poor expressiveness. RNN layers can only store past tokens into a fixed-size hidden state, while for linear attention variants such as Mamba and DeltaNet, the hidden state can only be a matrix. Compressing hundreds or even thousands of vectors into a matrix with only thousands of elements is in itself a challenge. Therefore, these RNN layers struggle to remember the deep relationships between distant tokens.
Therefore, researchers attempted to use another type of RNN layer, where the hidden state itself can also be a neural network. Specifically, they used two layers of MLP, which have twice as many hidden units as the linear (matrix) hidden states in the linear attention variants and possess richer non-linearity. Even on test sequences, the hidden states of the neural network are updated during training. These new layers are referred to as Test-Time Training layers (TTT).

The local attention mechanism maintains consistency between Tom’s color and Jerry’s mouse hole, and distorts Tom’s body.

TTT-MLP demonstrates strong characteristics and temporal consistency throughout the entire video duration.
The researchers curated a text-to-video dataset based on approximately 7 hours of the *Tom and Jerry* animated series, accompanied by human-annotated storyboards. They intentionally limited the scope to this specific domain to enable rapid research iteration. As a proof of concept, the dataset emphasizes long-form stories with complex, multi-scene settings and dynamic motion, areas where previous models still require improvement. In contrast, less emphasis was placed on visual and physical realism, as previous models have already made significant progress in these aspects. The researchers believe that, although this work focuses on improving long-context capabilities in this specific domain, the findings can also be transferred to general video generation.
Generate quality assessment
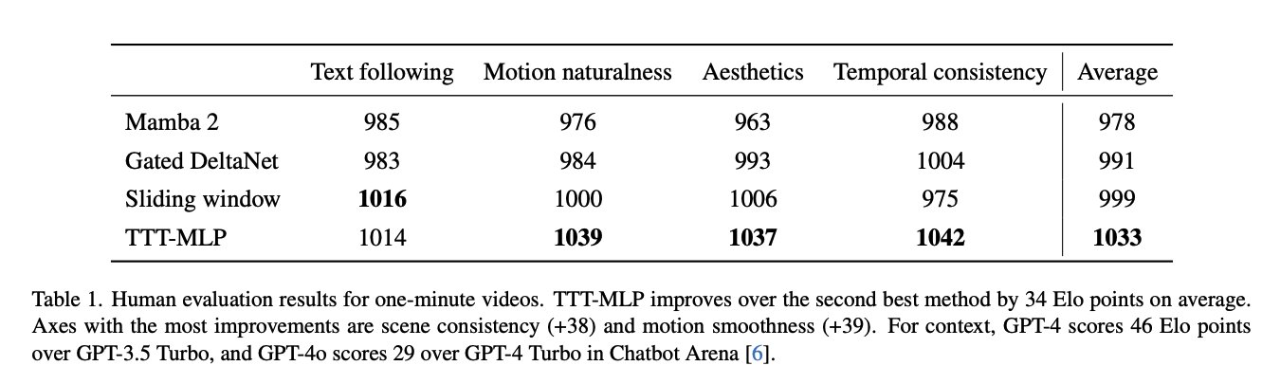
In the evaluation, compared with powerful baselines such as Mamba 2, Gated DeltaNet, and sliding window attention layers, the videos generated by the TTT layer are more coherent and capable of narrating complex dynamic stories.

In LMSys Chatbot Arena, GPT-4o is 29 Elo points higher than GPT-4 Turbo.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...