Algorithms are not the most important. For AI, “unlocking” new data sources is the key to achieving the next paradigm breakthrough.
As is well known, artificial intelligence has made incredible progress over the past fifteen years, especially in the last five years.
Let’s take a look at the “Four Great Inventions” of artificial intelligence: Deep Neural Networks → Transformer Language Models → RLHF → Reasoning. These basically summarize everything that has happened in the field of AI.
We have deep neural networks (mainly image recognition systems), followed by text classifiers, then chatbots, and now we have reasoning models. Progress within the field has been continuous — although paradigm-shifting breakthroughs are not common, we firmly believe that we can move forward through slow yet steady development.
Thought-provoking questions arise: What will the next major breakthrough be? And what will it depend on?
Jack Morris, a Ph.D. student at Cornell University (Technology Campus), has put forward a novel view: From 2012 to the present, the fundamental breakthroughs in AI have not come from brand-new algorithmic innovations, but from the new data sources we can utilize and better ways of leveraging data.

Therefore, he believes that the next paradigm shift in artificial intelligence may rely on video data (especially YouTube) and real-world data (robots
Let’s take a look at how the author analyzed it:
In fact, some researchers have recently proposed the “Moore’s Law of Artificial Intelligence,” which posits that the ability of computers to perform certain tasks (here referring to certain types of coding tasks) will grow exponentially over time.
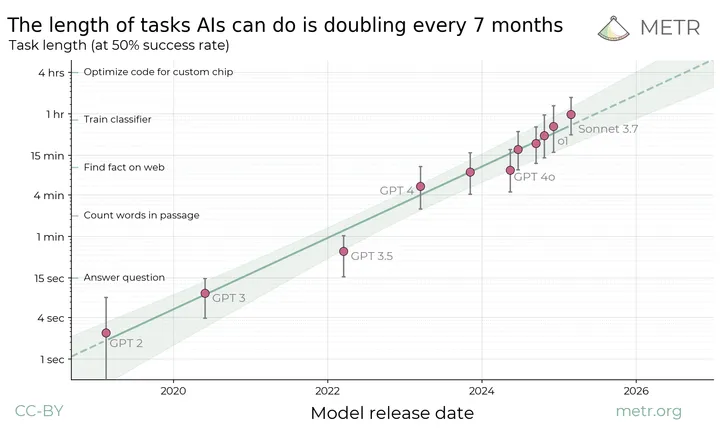
“Artificial Intelligence Moore’s Law”. (Incidentally, anyone who thinks that an autonomous intelligent agent can operate without human intervention for one hour by April 2025 is deluding themselves.)
Although for various reasons I don’t agree with this statement, I can’t deny the progressive trend of artificial intelligence. Every year, our smarter, faster, and cheaper, and this trend shows no sign of ending yet.
Most people believe that this continuous progress stems from the steady supply of ideas from the research community, mainly in academia (particularly at MIT, Stanford University, and Carnegie Mellon University) and industry (mainly Meta, Google, and a few Chinese labs). At the same time, there is also a lot of research being conducted elsewhere that we may never get to know about.
Significant progress has indeed been made in research, especially in the system aspect. This is particularly reflected in how to reduce model costs. Here are a few noteworthy examples:
- In 2022, researchers at Stanford University proposed FlashAttention, which is a method to better utilize memory in language models and has been used almost everywhere.
- In 2023, researchers at Google developed speculative decoding, which is now used by all model providers to accelerate inference (it was also developed by DeepMind, seemingly at the same time).
- In 2024, a group of internet enthusiasts developed Muon, which seems to be a better optimizer than SGD or Adam and could potentially become the way to train language models in the future.
- In 2025, DeepSeek released DeepSeek-R1, an open-source model whose reasoning ability is comparable to that of similar closed-source models from artificial intelligence laboratories (especially Google and OpenAI).
People are constantly exploring, and reality is really cool: Everyone is participating in decentralized global scientific research, and the research findings will be publicly shared on arXiv, academic conferences, and social media.
If we are conducting so many important studies, why do some people think that progress is slowing down? What causes people to complain is that the two latest large models, Grok 3 and GPT-4.5, have only made minor improvements on the previous versions. A particularly prominent example is that in the latest Mathematical Olympiad exam, language models only scored 5%, indicating that recent claims about reporting system capabilities may have been exaggerated.
The “Four Great Inventions” of Artificial Intelligence
If we attempt to record those “significant” breakthroughs, those true paradigm shifts, they seem to be occurring at different rates.
1. Deep Neural Networks: Deep neural networks began to take off after the AlexNet model won the image recognition competition in 2012.
2. Transformer + Large Language Models: In 2017, Google proposed the Transformer in “Attention Is All You Need,” which led to the emergence of BERT (Google, 2018) and the original GPT (OpenAI, 2018).
3. RLHF (Reinforcement Learning with Human Feedback): As far as I know, it was first introduced in OpenAI’s 2022 InstructGPT paper.
4. Reasoning: In 2024, OpenAI released o1, followed by DeepSeek’s release of R1.
Actually, these four things (Deep Neural Networks → Transformer Language Models → RLHF → Reasoning) pretty much sum up everything that has happened in the AI field: we had Deep Neural Networks (mainly image recognition systems), then text classifiers, then chatbots, and now we have reasoning models (whatever those may be).
Assuming one wishes to achieve a fifth such breakthrough, studying the four existing cases might be helpful.
What new research ideas have led to these breakthrough events? It is not absurd that the fundamental mechanisms underlying all these breakthroughs already existed in the 1990s or even earlier. We are applying relatively simple neural network architectures to perform supervised learning (1 and 2) or reinforcement learning (3 and 4).
Supervised learning with cross-entropy, which is the main approach for pre-training language models, originates from Claude Shannon’s work in the940s. Reinforcement learning, on the other hand, is the primary method for fine-tuning language models through Reinforcement Learning from Human Feedback (RLHF) and inference training, and it emerged slightly later. Its origins can be traced back to the introduction of the policy gradient method in 1992 (these ideas were already present in the first edition of the *Reinforcement Learning* textbook by Sutton & Barto, published in 1998).
If the idea isn’t new, then what is?
These “major breakthroughs” can be said to be new applications of things we have known for some time. First of all, this means that the “next major breakthrough” may not come from a brand-new idea, but rather the re-emergence of something we have already known for some time.
But there is one part missing here —— each of these four breakthroughs has enabled us to learn from new data sources:
1. AlexNet and its subsequent work unlocked ImageNet, a large-scale image database with classification labels, driving progress in computer vision over the past fifteen years.
2. Transformer unlocked training on the “internet,” as well as the race to download, classify, and parse all text on the web (which now seems largely complete).
3. RLHF enables learn from human labels that indicate what constitutes “good text” (primarily a matter of feel).
4. Reasoning seems to allow us to learn from “validators,” such as calculators and compilers, which can evaluate the output of language models.
Remind myself that each of these milestones marks the first large-scale use of their respective data sources (ImageNet, the web, humans, validators). Each milestone is followed by a flurry of activity: researchers compete (a) to extract the remaining useful data from any available source and (b) to better utilize existing data through new techniques, making our systems more efficient and less demanding of data.
We expect to see this trend emerge in reasoning models in 2025 and 2026, as researchers are racing to find, classify, and verify everything that can be verified.

Researchers created ImageNet (the largest public image dataset at that time), and the advancement of artificial intelligence may have been inevitable.
How important is a new idea?
In these scenarios, it is worth noting that our actual technological innovations may not lead to significant differences. Let us examine the counterfactuals. If we had not invented AlexNet, perhaps another architecture capable of handling ImageNet would have emerged. If we had never discovered the Transformer, maybe we would have adopted LSTMs or SSMs, or found entirely new ways to learn from the vast amount of useful training data available on the internet.
This is consistent with the theory held by some people that “nothing matters except data.” Some researchers have observed that among all the training techniques, modeling tricks, and hyperparameter tunings we do, changing the data overall makes the biggest difference.
An interesting example is that some researchers are dedicated to developing a new BERT-like model using architectures other than the Transformer. They spent about a year adjusting the architecture in hundreds of different ways and managed to create a different type of model (a state-space model or SSM), which, when trained on the same data, performs roughly as well as the original Transformer.
The profoundness of this discovery lies in its equivalence, as it implies an upper limit to what we can potentially learn from a given dataset. All the training tricks and model upgrades in the world cannot bypass this cold, hard fact: there is only so much that can be learned from a given dataset.
Perhaps indifference to new ideas is what we should learn from “Bitter Lessons”. If data is the only thing that matters, why are 95% of people researching new methods?
Where will the next paradigm shift come from? Could it be YouTube?
The obvious conclusion is that our next paradigm shift will not come from improvements in reinforcement learning or a novel type of neural network, but rather when we unlock data sources that have not been previously accessed or fully utilized.
An obvious source of information that many people are making efforts to utilize is video. According to a random website on the Internet, about 500 hours of video are uploaded to YouTube every minute. This is an absurd amount of data, far more than the text available on the entire Internet. It could also be a richer source of information because videos contain not only words but also the tones behind them and rich information about the physical and cultural aspects that cannot be obtained from text.
It can be said with certainty that once our model becomes efficient enough, or our computers become powerful enough, Google will start training models on YouTube. After all, they own this platform; it would be foolish not to leverage this data for their own benefit.
The last contender for the next “paradigm” of AI is some kind of embodied data collection system — or, in layman’s terms, robots. Currently, we are unable to collect and process information from cameras and sensors in a way that is suitable for training large models on GPUs. If we can build smarter sensors or expand our computers to the point where they can easily handle the massive influx of data from robots, we might be able to use this data in meaningful ways.
It’s hard to say whether YouTube, robots, or something else will be the next big thing in AI. We currently seem to be deeply rooted in the language model camp, but it also seems that we will soon run out of language data.
But if we want to make progress in AI, perhaps we should stop looking for new ideas and start looking for new data!
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...