Breakthrough! The inference ability of this 14B model is on par with that of o3-mini.
Recently, a brand-new open-source code reasoning model called DeepCoder-14B-Preview, jointly launched by UC Berkeley and Together AI, has attracted widespread attention in the tech community. This model, with only 14B parameters, is capable of matching the performance of OpenAI’s o3-mini in code reasoning. Most importantly, the model is fully open-source, allowing anyone to use it for free. This means that everyone can easily run this model in their own environment and enjoy its powerful reasoning capabilities.
In the field of deep learning, open source is not just about sharing technology; it is a revolution of ideas. This time, the throne of OpenAI seems to have been quietly seized. The release of DeepCoder-14B-Preview has led many industry insiders to exclaim: “This is truly a victory for open source.”
Breakthroughs in Reinforcement Learning
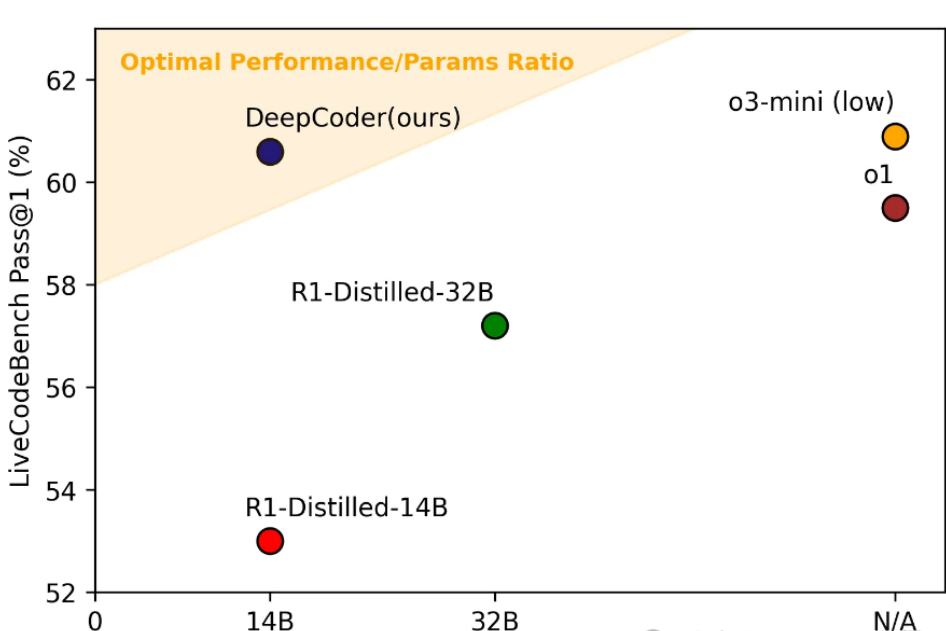
DeepCoder-14B-Preview utilizes distributed reinforcement learning (RL) technology and is fine-tuned from the Deepseek-R1-Distilled-Qwen-14B model. In the LiveCodeBench benchmark test, it achieves a single-pass accuracy (Pass@1) of up to 60.6%, representing an improvement of 8% compared to previous models. This breakthrough fully demonstrates the immense potential of reinforcement learning in the field of code reasoning.
It is worth mentioning that the training process of DeepCoder was not accomplished overnight. It was trained on 24K verified programming problems and underwent intensive training for 2.5 weeks using 32 H100 GPUs. All datasets, code, and training logs have been open-sourced, providing a valuable learning and exploration opportunity for technology enthusiasts and researchers.
High-quality datasets ensure training stability
To ensure the stability and accuracy of model training, the research team at DeepCoder spent a significant amount of time screening and cleaning the dataset. During early experiments, the team found that many existing datasets were either too simplistic or contained noise in the data, which failed to provide effective learning signals for the model. To address this, the team compiled a high-quality dataset that underwent rigorous screening, incorporating multiple sources including TACO Verified, PrimeIntellect SYNTHETIC-1, and LiveCodeBench.
Every question in the datasets undergoes programmatic verification to ensure that the reward mechanism for model training is reliable. To avoid data duplication, the team also performed deduplication on multiple datasets, ensuring that each question is independent, effectively preventing repeated training and interference. This rigorous filtering process provides strong support for DeepCoder’s reasoning capabilities.
Super-long context reasoning ability
During the training process of the model, the expansion of context length is one of the key factors that enables DeepCoder to break through performance bottlenecks. Traditional code reasoning models are often limited by context length, resulting in suboptimal performance when handling longer code segments. However, DeepCoder overcomes this limitation by introducing an ultra-long filtering technique, allowing the model to perform stable inference even with a context length of up to 64K.
This technology enables DeepCoder to maintain high accuracy and reasoning capabilities even when dealing with complex problems. In the evaluation of LiveCodeBench, the model achieved an accuracy rate of 60.6% in the 64K context, performing excellently and surpassing many similar models.
Open-source system optimization to improve training speed.
In addition to the powerful model itself, the optimization of DeepCoder’s open-source system is also a significant factor contributing to its rapid training. To improve training efficiency, the team has open-sourced verl-pipe, a post-training system based on verl. It incorporates multiple system-level optimizations, enabling a 2x increase in training speed. For models that require lengthy training periods, the optimized system is undoubtedly a tremendous boost.
In addition, the team has introduced a highly innovative technology: One-Off Pipelining. This technology enables the full pipelining of the sampling and training processes, effectively reducing waiting time during training. Especially in programming tasks, where calculating rewards requires a large number of unit tests, One-Off Pipelining allows the reward calculation to be interleaved with the training process, further improving training efficiency.
The significance of open source
The release of DeepCoder-14B-Preview represents not just a technological breakthrough, but also highlights the power of the open-source culture. In the fields of artificial intelligence and deep learning, the release of open-source models can greatly advance technological progress, providing tools and inspiration for more developers and researchers. Open-source lowers the barrier to technology, encouraging global developers to participate and collaborate, creating even more powerful tools and platforms.
In the future, with the release of more open-source projects like DeepCoder, technological innovation will become more open and accessible. For programmers and developers, being able to freely use these open-source tools will not only improve their work efficiency but also promote the progress of the entire industry.
Summary
The release of DeepCoder-14B-Preview is undoubtedly a major highlight in the AI field. This fully open-source model has not only made significant technological advancements with its 14B parameters and long-context reasoning capabilities but has also, under the promotion of open-source culture, provided valuable resources for developers worldwide. As the technology continues to iterate and optimize, we can look forward to more innovations emerging in the open-source community, bringing both opportunities and challenges for programmers.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...