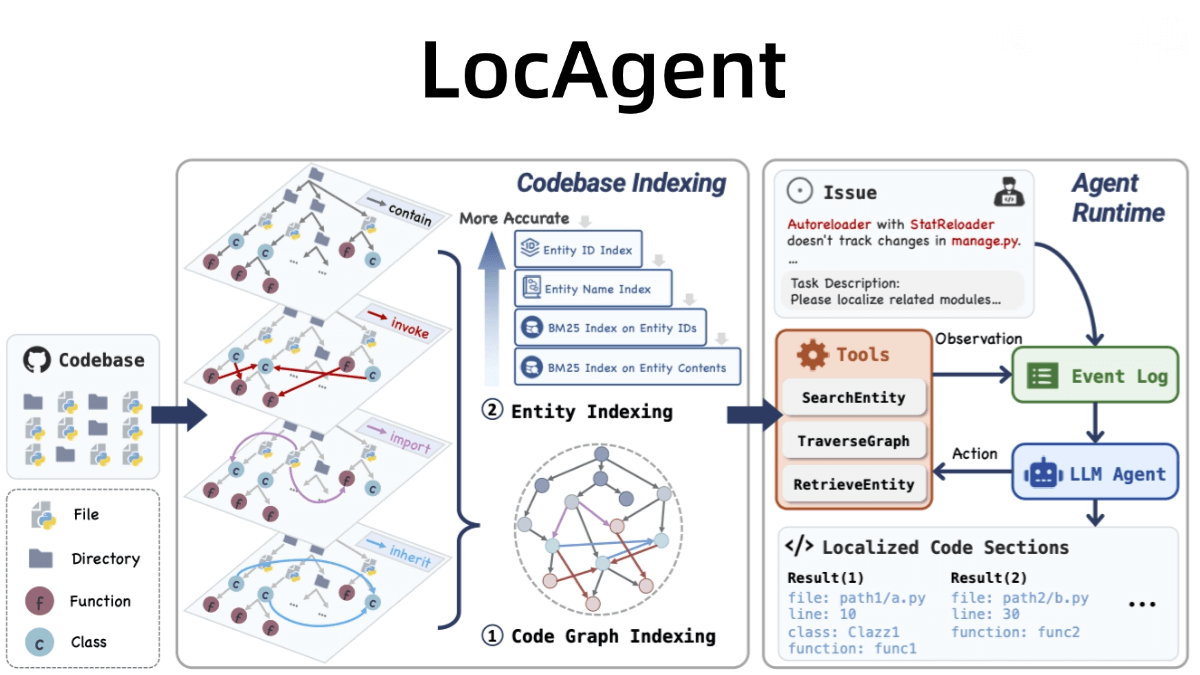
GLM-4-32B – The new generation foundational model open-sourced by Zhipu
What is GLM-4-32B?
GLM-4-32B is a new generation foundational model open-sourced by Zhipu. Its parameter version is GLM-4-32B-0414. GLM-4-32B has been pre-trained on 15T high-quality data, enhancing its capabilities in code generation, reasoning, and engineering tasks. It supports real-time code display and execution in languages such as HTML, CSS, JS, and SVG. The model’s performance is on par with larger mainstream models like GPT-4o and DeepSeek-V3-0324 (671B). Meanwhile, it follows the MIT License, being fully open-source with no restrictions on commercial use. Users can also experience the powerful features of the model for free on the Z.ai platform.

The main functions of GLM – 4 – 32B
- Powerful Language Generation Capability: Supports the generation of natural and fluent text, accommodating various language styles and scenarios such as dialogue, writing, translation, etc.
- Code Generation and Optimization: Supports the generation of code in languages such as HTML, CSS, JavaScript, and SVG, and enables real-time display of code execution results during conversations, facilitating user modifications and adjustments.
- Reasoning and Logical Tasks: Excels in tasks involving mathematics, logical reasoning, and handling complex reasoning problems.
- Multimodal Support: Supports the generation and parsing of various content formats, such as HTML pages and SVG graphics, to meet diverse application scenarios.
The Technical Principles of GLM-4-32B
- Large-scale Pre-training: The model is pre-trained on 15T of high-quality data with 32 billion parameters, covering diverse data types such as text, code, and reasoning data, providing a broad knowledge foundation for the model.
- Reinforcement Learning Optimization: Building on pre-training, the model’s performance is further optimized using reinforcement learning techniques, with in-depth enhancements in instruction following, code generation, and reasoning tasks.
- Rejection Sampling and Alignment: Low-quality generation results are filtered out using rejection sampling technology, combined with human preference alignment, ensuring that the model’s outputs align with human language habits and logical thinking.
- Efficient Inference Framework: Optimized for inference speed and efficiency, leveraging techniques such as quantization and speculative sampling to reduce GPU memory usage and improve inference speed, achieving an ultra-fast response rate of 200 tokens per second.
- Multi-task Learning: The model learns multiple tasks simultaneously during training, including language generation, code generation, and reasoning, enabling broad generalization capabilities and adaptability.
Project address of GLM-4-32B
- GitHub Repository: https://github.com/THUDM/GLM-4/
- Hugging Face Model Hub: https://huggingface.co/THUDM/GLM-4-32B
Application Scenarios of GLM-4-32B
- Intelligent Programming: Generate and optimize code, supporting multiple programming languages to assist developers in quickly completing programming tasks.
- Content Creation: Generate multimodal content such as text, web pages, SVG graphics, etc., to aid creative writing and design.
- Intelligent Office: Automatically generate reports, scripts, and automate tasks to improve work efficiency.
- Education and Learning: Provide programming examples and knowledge answers to assist teaching and learning.
- Business Applications: Used in intelligent customer service, data analysis, and supporting enterprise decision-making and service optimization.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...