NodeRAG – An open-source intelligent retrieval and generation system based on heterogeneous graphs
What is NodeRAG?
NodeRAG is a Retrieval-Augmented Generation (RAG) system based on a heterogeneous graph. By constructing a heterogeneous graph with multiple types of nodes, it integrates document information with insights generated by language models, enabling multi-hop retrieval and fine-grained information extraction. NodeRAG’s heterogeneous graph includes entities, relationships, semantic units, and other node types, allowing for context-aware retrieval that significantly improves accuracy and efficiency. It supports incremental updates, dynamically adapting to data changes, and uses optimized algorithms to boost retrieval speed and performance.

Key Features of NodeRAG
-
Multi-hop Information Retrieval:
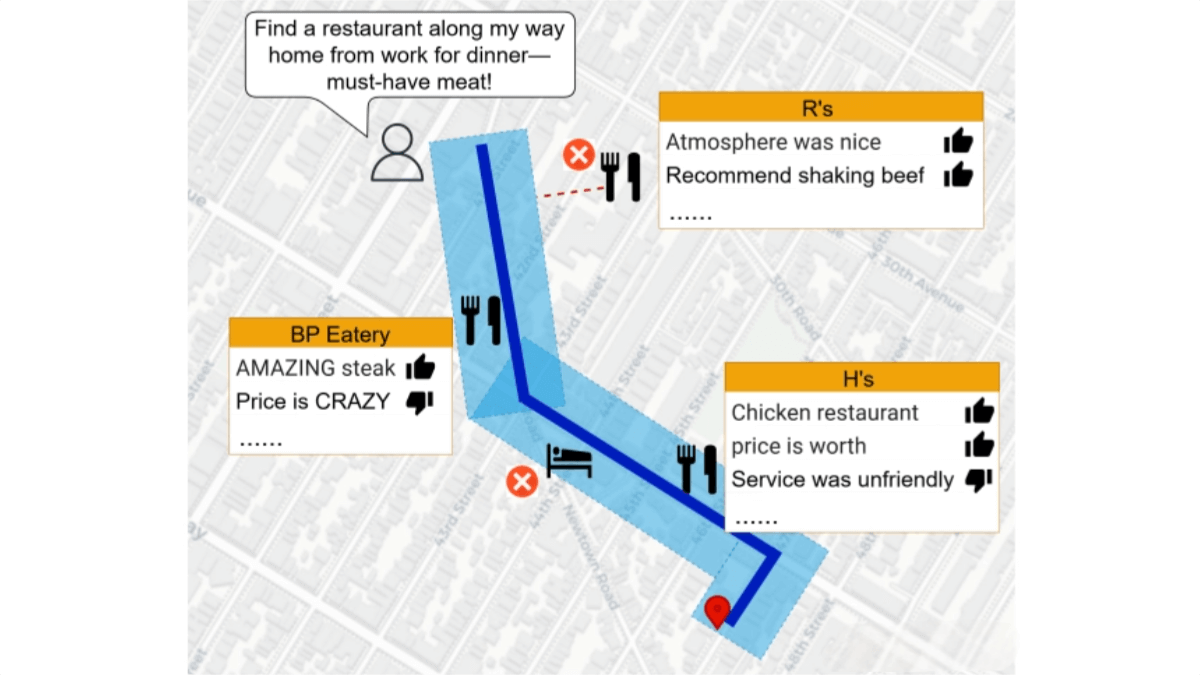
NodeRAG supports multi-hop information retrieval through its heterogeneous graph structure. It can extract and integrate information from multiple nodes to handle complex query tasks. For example, in multi-document question answering, NodeRAG can retrieve related information scattered across different documents to generate accurate answers. -
Fine-grained Information Extraction:
With various node types (such as entities, relationships, semantic units), NodeRAG enables fine-grained classification and organization of information. This allows for more precise retrieval and extraction, improving the interpretability of results. -
Incremental Update Support:
NodeRAG supports incremental updates to the heterogeneous graph, allowing new nodes and edges to be dynamically added or modified. This makes it suitable for fast-changing data environments—e.g., in the news domain, new events can be integrated into the graph without rebuilding the entire structure. -
Optimized Performance and Efficiency:
NodeRAG is optimized for retrieval speed and storage efficiency. Using efficient indexing and querying algorithms, it performs fast information retrieval on large datasets while reducing storage costs. -
Visualization and User Interface:
NodeRAG provides a user-friendly visual interface and a complete web UI, allowing users to explore and manage the heterogeneous graph through graphical interaction. -
Context-aware Generation:
The generation module in NodeRAG leverages contextual information from the graph to produce more accurate and coherent text outputs. By combining retrieved information with language model capabilities, it generates high-quality content such as news summaries and Q&A responses. -
Flexible Deployment and Scalability:
NodeRAG can be installed via Conda and PyPI, making local web UI deployment simple. Its architecture is designed for flexibility and scalability, supporting multiple languages and domains including news, finance, and healthcare.
Technical Principles of NodeRAG
-
Heterogeneous Graph Design:
At the core of NodeRAG is a heterogeneous graph structure that incorporates multiple types of nodes—entities, relationships, semantic units, attributes, high-level elements, overviews, and text nodes—to comprehensively represent the knowledge in a corpus. Each node type serves a specific role and function, forming a powerful and flexible graph structure. -
Graph Construction Process:
The graph is constructed in three main steps:-
Graph Decomposition: Large language models decompose text blocks into basic nodes such as semantic units, entities, and relationships to form the initial graph structure.
-
Graph Enhancement: The graph is enriched through node importance evaluation (e.g., K-core decomposition, betweenness centrality) and community detection (e.g., Leiden algorithm), adding high-level elements and attribute nodes.
-
Graph Enrichment: Original text blocks are inserted selectively. Data is organized into a multi-layer graph using the Hierarchical Navigable Small World (HNSW) algorithm to efficiently retrieve semantically similar nodes.
-
-
Graph Search Mechanism:
NodeRAG adopts a dual-search mechanism and shallow Personalized PageRank (PPR) algorithm for efficient retrieval:-
Dual Search Mechanism: Combines exact matches on title nodes with vector similarity search on rich-information nodes to identify entry points in the graph.
-
Shallow PPR Algorithm: Simulates a biased random walk starting from entry points to identify related nodes. Early stopping strategies are used to keep relevance localized.
-
-
Incremental Update Mechanism:
NodeRAG supports incremental graph updates. When new documents are added, the system can intelligently integrate the new information into the existing graph without rebuilding the entire knowledge structure. -
Optimized Sparse Personalized PageRank:
NodeRAG implements an optimized sparse PPR algorithm using SciPy’s sparse matrix capabilities to efficiently handle large-scale graph structures. This enables high-performance node importance computation for precise retrieval.
Project Repository
-
GitHub Repository:
https://github.com/Terry-Xu-666/NodeRAG
Application Scenarios
-
Academic Research:
Researchers can use NodeRAG to organize literature and build paper relationship graphs. By importing academic datasets, the system can extract keywords, authors, citations, etc., and generate knowledge graphs. -
Enterprise Knowledge Management:
Companies can manage internal documents and build knowledge bases using NodeRAG. By importing technical documents, project reports, etc., the system generates document relationship graphs to help employees quickly locate needed information and improve knowledge sharing efficiency. -
QA Systems for Complex Domains:
In professional fields like medicine, law, or finance, NodeRAG’s heterogeneous graph structure can accurately capture domain-specific concepts and relationships to provide precise question-answering support. -
Personalized Recommendation Systems:
NodeRAG’s graph can model user preferences, product features, sentiment in reviews, and more. It captures the complex relationships between them to deliver more accurate recommendations. -
Data Analysis and Visualization:
Analysts can use NodeRAG to analyze complex datasets such as social networks or customer relationship data. Its graph visualizations reveal hidden patterns, making it suitable for market analysis, risk assessment, or recommendation system development.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts

No comments yet...