Muyan-TTS: An Open-Source High-Fidelity TTS Model Tailored for Podcasts
🧠 What is Muyan-TTS?
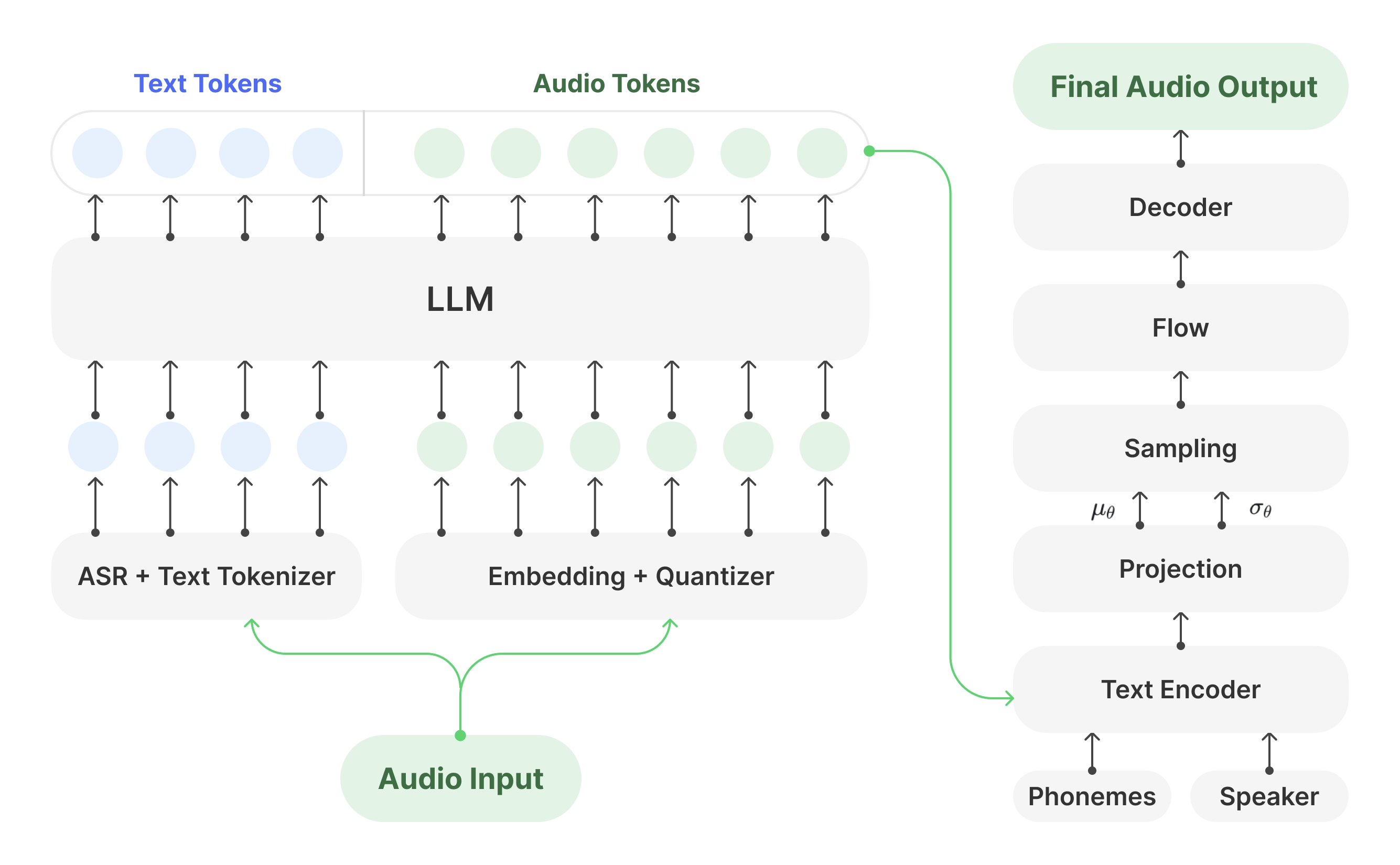
Muyan-TTS is a trainable, open-source TTS model built for podcast scenarios. Pretrained on over 100,000 hours of podcast audio data, it supports zero-shot speech synthesis, enabling it to generate high-quality speech without requiring additional fine-tuning. It also supports speaker adaptation, which allows users to mimic a target speaker’s voice using just a few minutes of audio.
🚀 Key Features
-
Zero-Shot Speech Synthesis: Generate natural, fluid speech instantly without further training, ideal for rapid podcast content creation.
-
Speaker Adaptation: Mimic any speaker’s voice using only a small amount of sample audio, enabling personalized voice generation.
-
High-Quality Audio Output: Trained on a massive dataset of real podcast recordings, resulting in highly realistic and intelligible voice synthesis.
-
End-to-End Framework: Offers a complete pipeline including data preprocessing, model training, and inference for ease of deployment.
-
Optimized Inference Speed: Includes a performance-enhanced inference engine for fast and efficient voice generation.
⚙️ Technical Architecture
Muyan-TTS is powered by several advanced technologies:
-
Large-Scale Pretraining: Leveraging over 100,000 hours of podcast data, the model is highly attuned to the nuances of human speech and various audio conditions.
-
Speaker Embedding Mechanism: Enables personalized voice synthesis by capturing speaker characteristics in compact embeddings.
-
Efficient Inference Framework: Designed to deliver high-quality audio with low latency, ideal for real-time and batch TTS applications.
🔗 Project Links
-
GitHub Repository: https://github.com/MYZY-AI/Muyan-TTS
-
Technical Report (arXiv): https://arxiv.org/abs/2504.19146
💡 Use Cases
-
Podcast Content Creation: Automate the production of podcast audio, saving time and resources while maintaining quality.
-
Personalized Voice Assistants: Adapt to user-specific voices for more personalized interactions.
-
Audiobook Generation: Easily create fluent and expressive audiobooks.
-
Multilingual TTS Applications: Supports multilingual speech synthesis for global content delivery.
-
Education & Training: Generate custom voice content for e-learning, tutorials, and digital training.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts



No comments yet...