Aero – 1 – Audio – A lightweight audio model launched by LMMs – Lab
What is Aero-1-Audio?
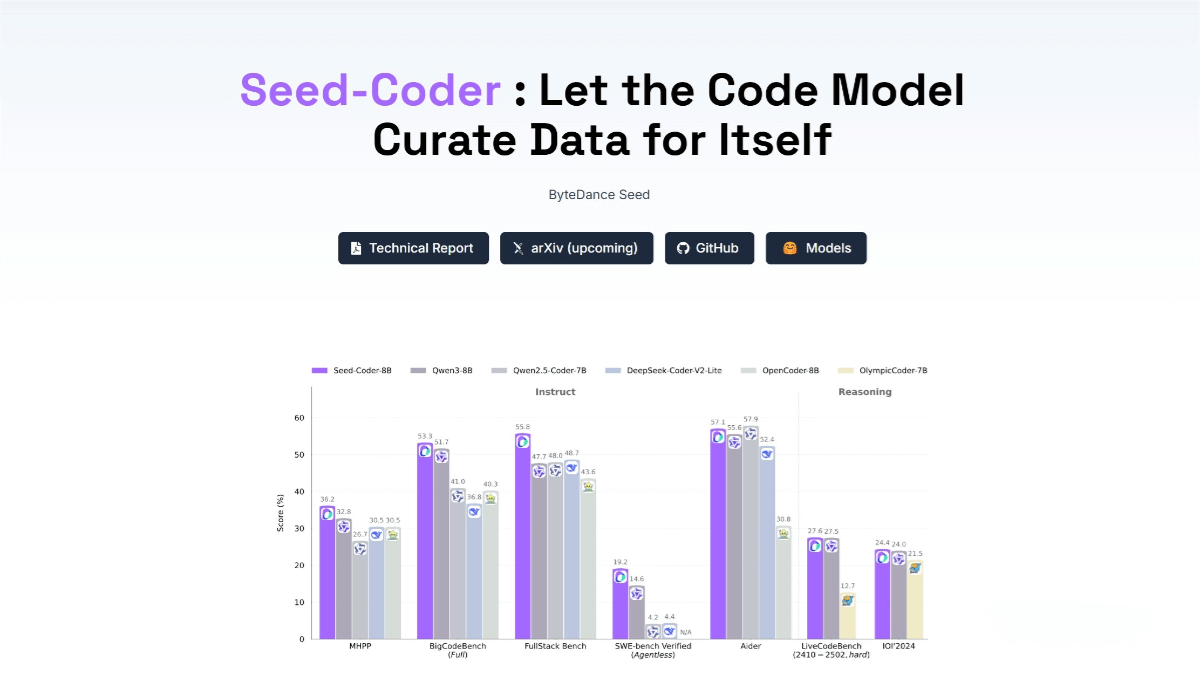
Aero-1-Audio is a lightweight audio model developed by LMMs-Lab, built upon Qwen-2.5-1.5B with only 150 million parameters. It is specifically designed for long-form audio processing, supporting continuous audio input of up to 15 minutes without segmentation, while maintaining contextual coherence. Aero-1-Audio demonstrates excellent performance in Automatic Speech Recognition (ASR) tasks, offering high accuracy and strong capabilities in complex audio analysis and instruction-driven tasks.

Key Features of Aero-1-Audio
-
Long Audio Processing: Capable of processing continuous audio up to 15 minutes without segmentation, preserving contextual coherence. Ideal for handling lengthy spoken content.
-
Automatic Speech Recognition (ASR): Excels in converting speech to text with high accuracy. Suitable for real-time transcription, meeting minutes, and lecture recordings.
-
Complex Audio Analysis: Supports analysis of various audio types including speech, sound effects, and music. It understands semantics and emotions in audio, making it useful for classification and analytical tasks.
-
Instruction-Driven Tasks: Capable of performing audio processing based on specific instructions, such as extracting targeted information or executing defined actions. This is particularly applicable to intelligent voice assistants.
Technical Principles of Aero-1-Audio
-
Lightweight Design & High Performance: With only 150 million parameters, Aero-1-Audio maintains a small model size but achieves outstanding performance across multiple audio benchmarks, outperforming larger models like Whisper and Qwen-2-Audio.
-
Efficient Training Method: Trained on a relatively small dataset of approximately 5 billion tokens (equivalent to 50,000 hours of audio), Aero-1-Audio uses high-quality filtered data and optimized training strategies. It can be trained in a single day using just 16 H100 GPUs.
-
Dynamic Batching & Sequence Packing: Implements token-length-based dynamic batching to group samples within predefined token length thresholds, significantly improving computational resource efficiency. Using sequence packing and Liger kernel fusion, the model’s FLOP utilization improved from 0.03 to 0.34, enhancing training efficiency.
-
Multitask Capabilities: Aero-1-Audio excels not only in ASR but also in audio analysis and understanding, instruction-following, and audio scene comprehension. It achieves the lowest Word Error Rates (WER) on datasets like AMI, LibriSpeech, and SPGISpeech.
Project Repository
-
HuggingFace Model Hub: https://huggingface.co/lmms-lab/Aero-1-Audio
Application Scenarios of Aero-1-Audio
-
Voice Assistants: Enables intelligent assistants with efficient speech recognition and understanding capabilities.
-
Real-time Transcription: Rapidly transcribes speech content to text, suitable for meetings, lectures, and more.
-
Archival Understanding: Adds semantic tags to audio archives, enabling semantic search.
-
Auditory Module: Equips AI agents with long speech understanding capabilities, supporting multi-turn dialogues.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts



No comments yet...