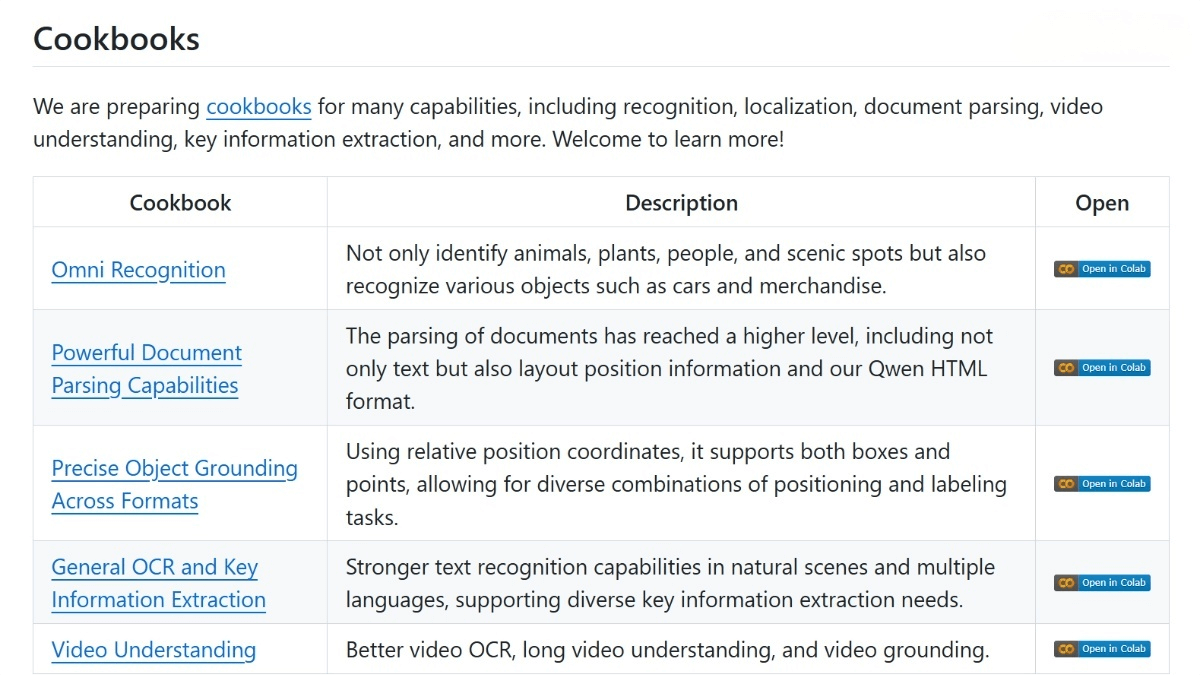
Pixel Reasoner – A visual language model launched jointly by the University of Waterloo, the Hong Kong University of Science and Technology and other universities
What is Pixel Reasoner?
Pixel Reasoner is a visual language model (VLM) developed by institutions including the University of Waterloo, Hong Kong University of Science and Technology, and the University of Science and Technology of China. It enhances understanding and reasoning over visual information through pixel-space reasoning. The model can directly manipulate visual inputs, such as zooming in on image regions or selecting video frames, capturing finer visual details. Pixel Reasoner employs a two-stage training approach: instruction tuning to familiarize the model with visual operations, and curiosity-driven reinforcement learning to encourage exploration of pixel-space reasoning. It achieves outstanding performance on multiple visual reasoning benchmarks, significantly improving results in visually intensive tasks.
![]()
Key Features of Pixel Reasoner
-
Direct Visual Operations:
Enables direct manipulation of visual inputs (images and videos), such as zooming in on specific image regions or selecting particular video frames, to capture fine-grained visual details. -
Enhanced Visual Understanding:
Recognizes and interprets small objects, subtle spatial relationships, embedded small text, and minor motions in videos. -
Multimodal Reasoning:
Handles complex visual-language tasks comprehensively, including visual question answering (VQA) and video understanding. -
Adaptive Reasoning:
Dynamically decides whether to employ visual operations based on the task, optimizing reasoning performance across various visual tasks.
Technical Principles of Pixel Reasoner
-
Instruction Tuning:
-
Seed Data Collection: Utilizes richly annotated image and video datasets such as SA1B, FineWeb, and STARQA.
-
Reference Visual Clues Localization: Identifies relevant visual cues (e.g., bounding boxes, frame indices) via dataset annotations or GPT-4o-generated labels.
-
Synthetic Expert Trajectories: Crafts reasoning paths using templates, ensuring the model correctly uses visual operations—starting with overall analysis, then triggering targeted visual operations for detailed extraction, and finally combining details to produce answers.
-
Training: Applies supervised fine-tuning (SFT) to teach the model visual operations, including insertion of incorrect operations followed by self-correction trajectories to enhance robustness.
-
-
Curiosity-Driven Reinforcement Learning:
-
Designs a reward function combining curiosity incentives and efficiency penalties to motivate exploration of pixel-space reasoning.
-
Employs reinforcement learning (RL) with near-policy updates every 512 queries to improve behavior and policy.
-
During training, the model learns when to apply pixel-space reasoning and self-corrects when visual operations fail.
-
Project Links
-
Official Website: https://tiger-ai-lab.github.io/Pixel-Reasoner/
-
GitHub Repository: https://github.com/TIGER-AI-Lab/Pixel-Reasoner
-
HuggingFace Model Collection: https://huggingface.co/collections/TIGER-Lab/pixel-reasoner
-
arXiv Paper: https://arxiv.org/pdf/2505.15966
-
Online Demo: https://huggingface.co/spaces/TIGER-Lab/Pixel-Reasoner
Application Scenarios for Pixel Reasoner
-
Researchers and Developers:
For training and optimizing models, especially in tasks like visual question answering and video analysis, improving model accuracy and performance. -
Educators:
Assisting teaching through intuitive visual demonstrations and explanations, helping students better grasp complex concepts. -
Industrial Quality Inspectors:
Automating visual inspection to quickly identify product defects, enhancing quality control efficiency and accuracy. -
Content Creators:
Enabling more precise visual content analysis and editing to improve the quality and appeal of creative works.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts




No comments yet...