Phi – 4 – reasoning – The Phi – 4 reasoning model series launched by Microsoft
What is Phi-4-reasoning?
Phi-4-reasoning is a 14-billion-parameter reasoning model developed by Microsoft, specifically designed for complex reasoning tasks. It is trained through Supervised Fine-Tuning (SFT) using high-quality reasoning demonstration data generated by OpenAI’s o3-mini model. The model is capable of generating detailed reasoning chains and efficiently utilizing computational resources during inference.
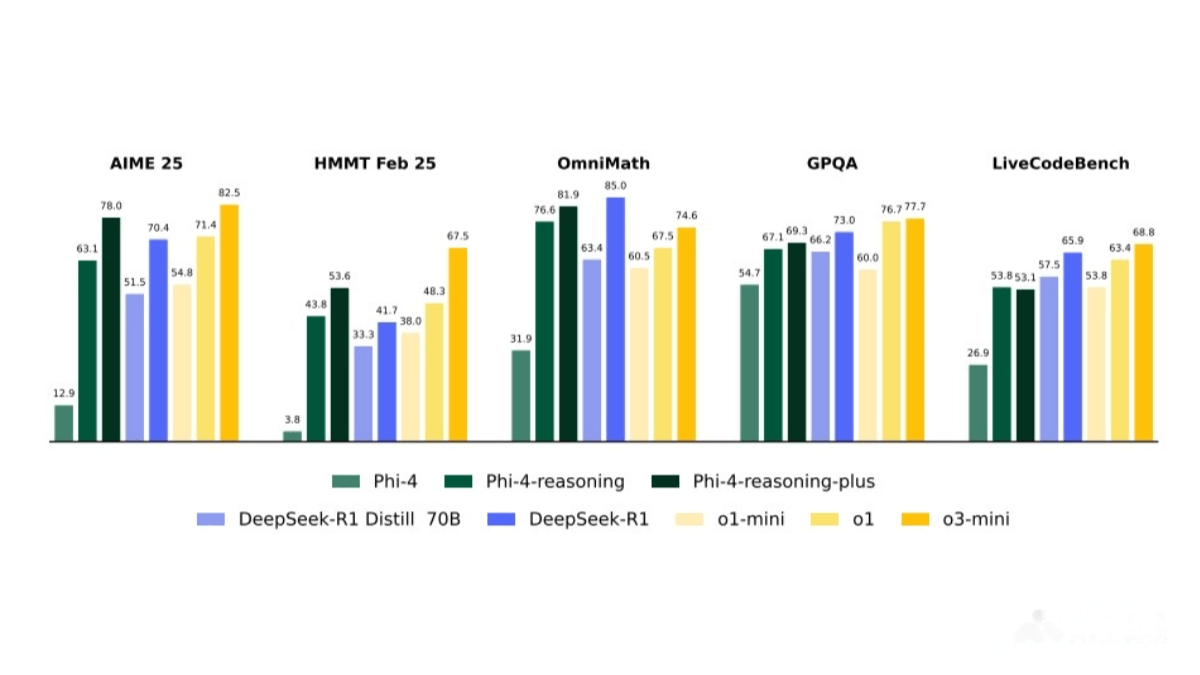
Phi-4-reasoning achieves outstanding performance across various benchmarks, outperforming larger models such as DeepSeek-R1-Distill-Llama-70B. It excels in mathematical reasoning, scientific problem-solving, programming, and algorithmic tasks.
Phi-4-reasoning-plus is an enhanced version further optimized through reinforcement learning, offering even stronger reasoning abilities.
Phi-4-mini-reasoning is a compact 3.8-billion-parameter version designed for resource-constrained environments like mobile devices and edge computing. It is fine-tuned using synthetic data generated by the DeepSeek-R1 model.
Key Features of Phi-4-reasoning
-
Powerful Complex Reasoning: Capable of handling tasks that require multi-step decomposition and internal reflection. It excels in mathematical reasoning, scientific problem-solving, programming, and algorithmic tasks.
-
Detailed Reasoning Chains: Trained via SFT, the model generates step-by-step reasoning chains that enhance accuracy and efficiency during inference.
-
Efficient Use of Computational Resources: Through inference-time scaling, the model dynamically allocates more resources during reasoning, further improving performance.
-
Educational and Tutoring Applications: Capable of solving diverse math problems from middle school to PhD-level, making it suitable for embedded tutoring in education and low-latency applications.
-
Lightweight Deployment: The Phi-4-mini-reasoning model is designed for deployment in environments with limited resources, such as mobile and edge devices.
-
Cross-Domain Adaptability: Beyond math and science, Phi-4-reasoning also performs well in general-purpose tasks like long-context QA, instruction following, coding, knowledge, and language understanding.
Technical Principles of Phi-4-reasoning
-
Supervised Fine-Tuning (SFT): Built on the Phi-4 model, the training introduces two placeholder tokens for “think” and “end-think” to support additional reasoning tokens, extending the maximum token length from 16K to 32K. The training data includes synthetic long-chain reasoning traces and high-quality answers across domains like math, coding, and safety. Over roughly 16K training steps, the model learns to use the “think” tokens, enhancing its reasoning ability.
-
Reinforcement Learning (RL): Phi-4-reasoning-plus is an RL-enhanced version that further improves reasoning, particularly in math. It uses a seed dataset of 72,401 math problems. The reward function is designed to encourage correctness, penalize bad behaviors like repetition and excessive length, and reward proper formatting.
-
Data Methodology: The training data emphasizes carefully curated high-quality examples, including creatively designed synthetic data and filtered organic data. The seed dataset is compiled from various web resources, filtered using LLMs, and prioritized for prompts that require complex, multi-step reasoning. Comprehensive decontamination ensures no overlap with common reasoning benchmarks.
Project Links
-
Hugging Face Model Hub: https://huggingface.co/collections/microsoft/phi-4
-
arXiv Paper: https://arxiv.org/pdf/2504.21318
Application Scenarios of Phi-4-reasoning
-
Education and Research: Both Phi-4-reasoning and Phi-4-mini-reasoning are well-suited for educational use, capable of solving a wide range of math and science problems from middle school to PhD level.
-
Complex Business Decision Support: Phi-4-reasoning-plus, enhanced with reinforcement learning, is suitable for critical business decision-making systems that require high accuracy. It can handle multi-step tasks and provide precise solutions.
-
Programming and Algorithmic Problem-Solving: The model performs exceptionally well in programming and algorithm tasks, generating detailed reasoning chains and solutions, making it ideal for coding assistance and algorithm optimization in development environments.
-
Lightweight Deployment and Mobile Devices: Phi-4-mini-reasoning is designed for deployment on devices with limited computational resources, such as mobile phones and edge computing platforms.
-
Core Engine for Agentic Applications: The Phi-4-reasoning model family can serve as the core engine for agentic applications, capable of handling complex and multifaceted tasks.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts



No comments yet...