
X – Fusion – A multimodal fusion framework jointly launched by the University of California and institutions such as Adobe
What is X-Fusion?
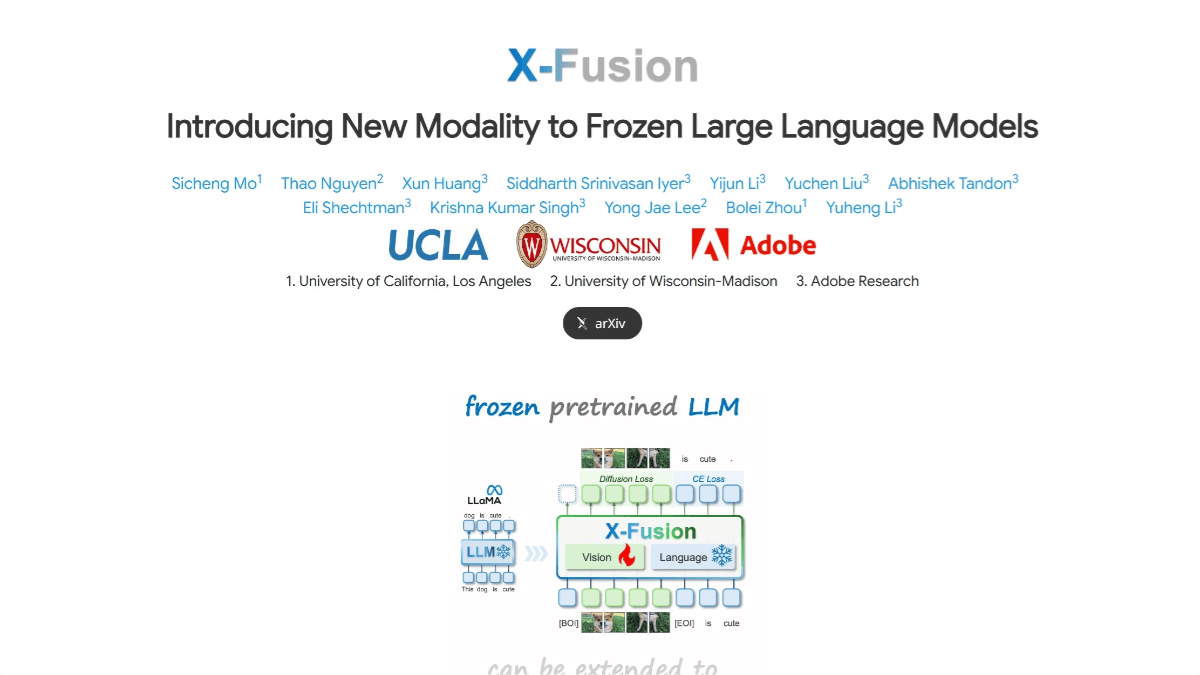
X-Fusion is a multimodal fusion framework jointly proposed by UCLA, the University of Wisconsin-Madison, and Adobe Research. It extends pre-trained large language models (LLMs) to multimodal tasks while preserving their language capabilities. The framework adopts a dual-tower architecture, freezing the parameters of the language model while introducing separate weights for the visual modality to handle visual information. X-Fusion aligns textual and visual features at the input, intermediate, and output levels, enabling efficient multimodal fusion.
Key Features of X-Fusion
-
Multimodal Task Extension: Capable of handling a variety of multimodal tasks such as image-to-text (e.g., image captioning) and text-to-image (e.g., image generation).
-
Performance Optimization: Enhances overall performance by reducing noise in image data; understanding task-specific data also significantly improves the quality of generative tasks.
-
Multi-task Training: Supports simultaneous training of multiple vision-language tasks (e.g., image editing, localization, visual question answering) without needing task-specific weights.
-
Pre-trained Model Transfer: Allows the capabilities of pre-trained diffusion models to be transferred into the visual tower, further improving image generation quality.
Technical Principles of X-Fusion
-
Dual-Tower Architecture: X-Fusion uses a dual-tower architecture, freezing the language model parameters and introducing new weights for the visual modality. It enables separate processing of language and visual inputs, with feature alignment at the intermediate layers to achieve effective multimodal understanding and generation.
-
Modality-Specific Weights: The language and vision towers process text and visual inputs independently. The language tower retains pre-trained parameters, while the vision tower incorporates new weights to handle visual information. This separation ensures language capabilities are preserved while enhancing visual understanding.
-
Feature Alignment and Fusion: X-Fusion performs feature alignment and fusion at the input, intermediate, and output levels. This multi-level alignment allows the model to better integrate language and visual information, improving performance on multimodal tasks.
-
Optimized Training Strategies: The framework explores how noise levels and data ratios affect performance during training. Experiments show that reducing image data noise significantly boosts overall performance, and understanding-based data benefits generative tasks.
Project Links
-
Project Website: https://sichengmo.github.io/XFusion/
-
arXiv Paper: https://arxiv.org/pdf/2504.20996
Application Scenarios of X-Fusion
-
Autonomous Driving: By fusing data from cameras, LiDAR, and other sensors, X-Fusion enables more comprehensive environmental perception, enhancing the safety and reliability of autonomous vehicles.
-
Robot Navigation: Assists robots in accurately localizing and planning paths in complex environments, strengthening autonomous navigation capabilities.
-
Human-Computer Interaction: Integrates multimodal inputs such as voice, gestures, and facial expressions to enable more natural and intelligent interaction. For example, in smart home settings, a voice assistant can interpret users’ gestures and expressions through visual data to offer more accurate services.
-
Emotion Analysis: Combines voice and visual data to more accurately identify users’ emotional states.
-
Medical Image Analysis: Fuses different types of medical imaging (e.g., MRI, CT) to help doctors gain a more comprehensive understanding of conditions, improving diagnosis accuracy and early detection.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts



No comments yet...