KernelLLM: Meta’s AI-Powered GPU Kernel Generator for Seamless PyTorch-to-Triton Conversion
What is KernelLLM?
KernelLLM is a cutting-edge large language model (LLM) developed by Meta (Facebook) and released on Hugging Face. It is specifically designed to generate efficient GPU kernel code, enabling seamless conversion from PyTorch modules to Triton kernels.
Built upon the Llama 3.1 Instruct model, KernelLLM is fine-tuned to understand both high-level PyTorch logic and low-level GPU programming, making it a powerful tool for optimizing deep learning workloads.
Key Features of KernelLLM
-
Automatic PyTorch-to-Triton Conversion: Automatically translates PyTorch modules into corresponding Triton GPU kernel implementations.
-
Multi-Candidate Kernel Generation: Supports generation of multiple kernel candidates in a single pass to increase success rates.
-
Automated Verification: Includes built-in unit test functionality to verify the correctness of generated kernels.
-
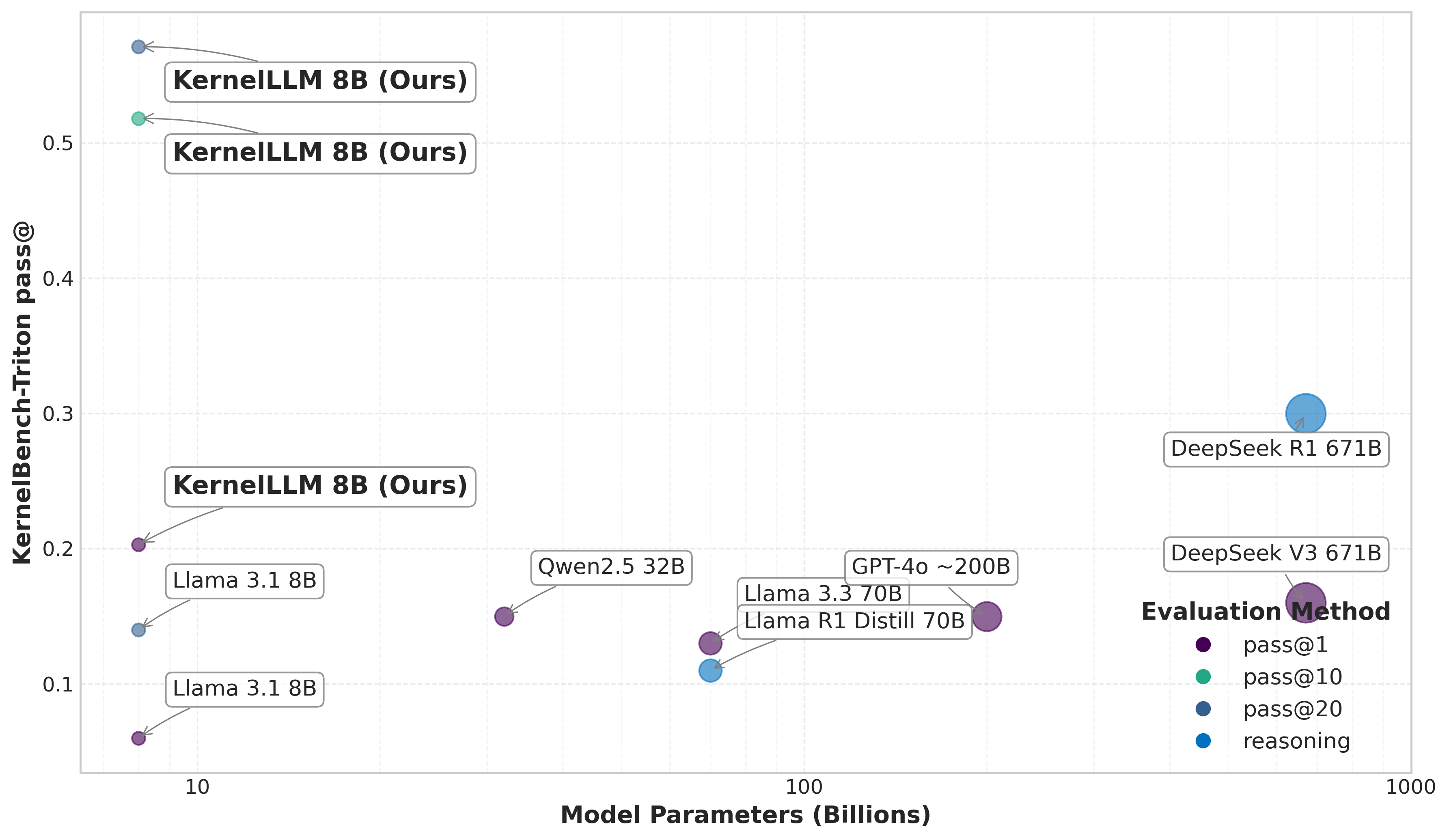
High Performance: Outperforms other state-of-the-art models like GPT-4o and DeepSeek V3 in KernelBench-Triton benchmark tests.
Technical Foundations
-
Training Data: Trained on approximately 25,000 aligned pairs of PyTorch modules and Triton kernels, combining examples from The Stack dataset and synthetic samples generated using
torch.compile(). -
Training Methodology: Fine-tuned using supervised instruction tuning (SFT) on 16 GPUs over 10 epochs, totaling around 192 GPU hours.
-
Evaluation Benchmark: Assessed using the KernelBench-Triton benchmark to measure its capability in generating accurate and performant GPU kernels.
Project Resources
-
Hugging Face Model Page: https://huggingface.co/facebook/KernelLLM
Application Scenarios
-
High-Performance Computing: Automatically generate efficient GPU kernels for scientific and data-intensive applications.
-
Deep Learning Optimization: Produce custom GPU kernels to accelerate model training and inference.
-
Compiler Development: Assist in building and optimizing Triton-compatible compiler toolchains.
-
Education & Research: Serve as an educational tool to teach GPU programming and performance optimization.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...