What is PlayDiffusion?
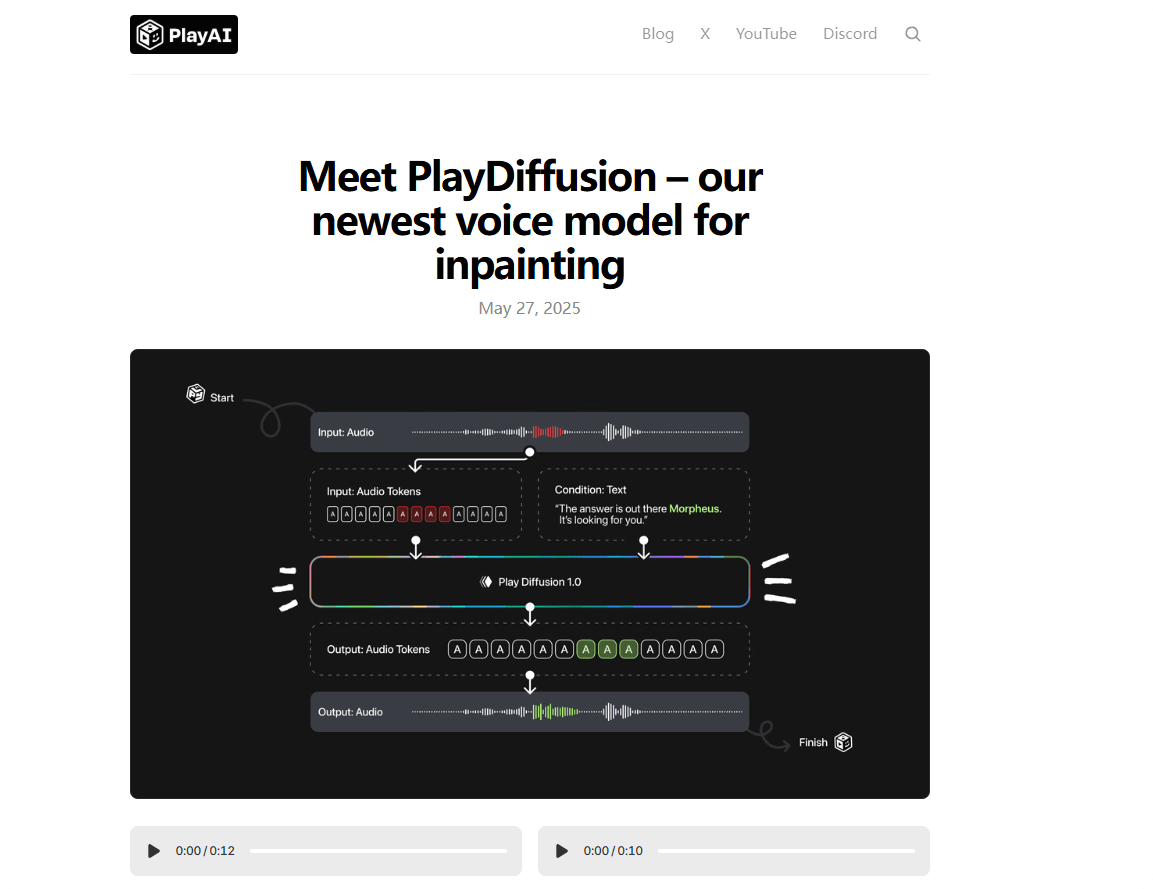
PlayDiffusion is a new audio editing model developed by Play AI, built on diffusion model technology and designed specifically for fine-grained audio editing and restoration. The model encodes audio into discrete token sequences, masks the segments that need editing, and uses a diffusion model—conditioned on updated text input—to denoise the masked region, achieving high-quality audio edits. It preserves context seamlessly, ensuring coherence and naturalness in speech, and also supports efficient text-to-speech (TTS) synthesis. Thanks to its non-autoregressive nature, PlayDiffusion offers significant advantages in both generation speed and quality over traditional autoregressive models, representing a breakthrough in audio editing and TTS.
Key Features of PlayDiffusion
-
Localized Audio Editing: Supports partial replacement, modification, or deletion of audio without regenerating the entire clip, maintaining natural and seamless transitions.
-
Efficient TTS: When masking the entire audio, the model functions as a fast TTS system—up to 50x faster inference than traditional TTS methods—with improved naturalness and consistency.
-
Maintains Speech Coherence: Preserves contextual information during editing to ensure speech continuity and consistent speaker voice.
-
Dynamic Voice Adjustment: Automatically modifies pronunciation, tone, and rhythm based on new text input, ideal for real-time interaction scenarios.
-
Seamless Integration and Ease of Use: Supports integration with Hugging Face and local deployment for easy experimentation and adoption.
Technical Overview of PlayDiffusion
-
Audio Encoding: Converts input audio sequences into discrete token sequences, where each token represents a unit of audio. This works for both real human speech and TTS-generated audio.
-
Masking Process: Marks the sections of audio that require modification with masks for targeted processing.
-
Diffusion-Based Denoising: Uses a diffusion model to denoise the masked regions based on updated text input. The model incrementally removes noise to generate high-quality audio token sequences. It employs a non-autoregressive approach, generating all tokens simultaneously and refining them over a fixed number of denoising steps.
-
Audio Decoding: The generated token sequences are converted back to speech waveforms using the BigVGAN decoder, ensuring that the final audio output is natural and coherent.
Project Links
-
Official Website: https://blog.play.ai/blog/play-diffusion
-
GitHub Repository: https://github.com/playht/PlayDiffusion
-
Live Demo: https://huggingface.co/spaces/PlayHT/PlayDiffusion
Use Cases for PlayDiffusion
-
Dubbing Corrections: Quickly replace mispronunciations while keeping the dubbing natural and smooth.
-
Dialogue Text Revisions: Easily modify dialogue content to ensure accurate and natural speech.
-
Podcast Editing: Modify or remove audio segments to improve content quality.
-
Real-Time Voice Interaction: Dynamically update speech content for natural, interactive experiences.
-
Speech Synthesis: Efficiently generate high-quality speech for narration and related applications.