
What is V-JEPA 2?
V-JEPA 2 is a world model introduced by Meta AI that understands, predicts, and plans based on video data to comprehend the physical world. It is built on a 1.2-billion-parameter Joint Embedding Predictive Architecture (JEPA) and trained using self-supervised learning on over 1 million hours of video and 1 million images. V-JEPA 2 achieves new performance heights in tasks such as action recognition, action prediction, and video question answering. It enables zero-shot robotic planning, allowing robots to interact with unfamiliar objects in new environments. V-JEPA 2 marks a significant step toward advanced machine intelligence and lays the foundation for future AI applications in the physical world.
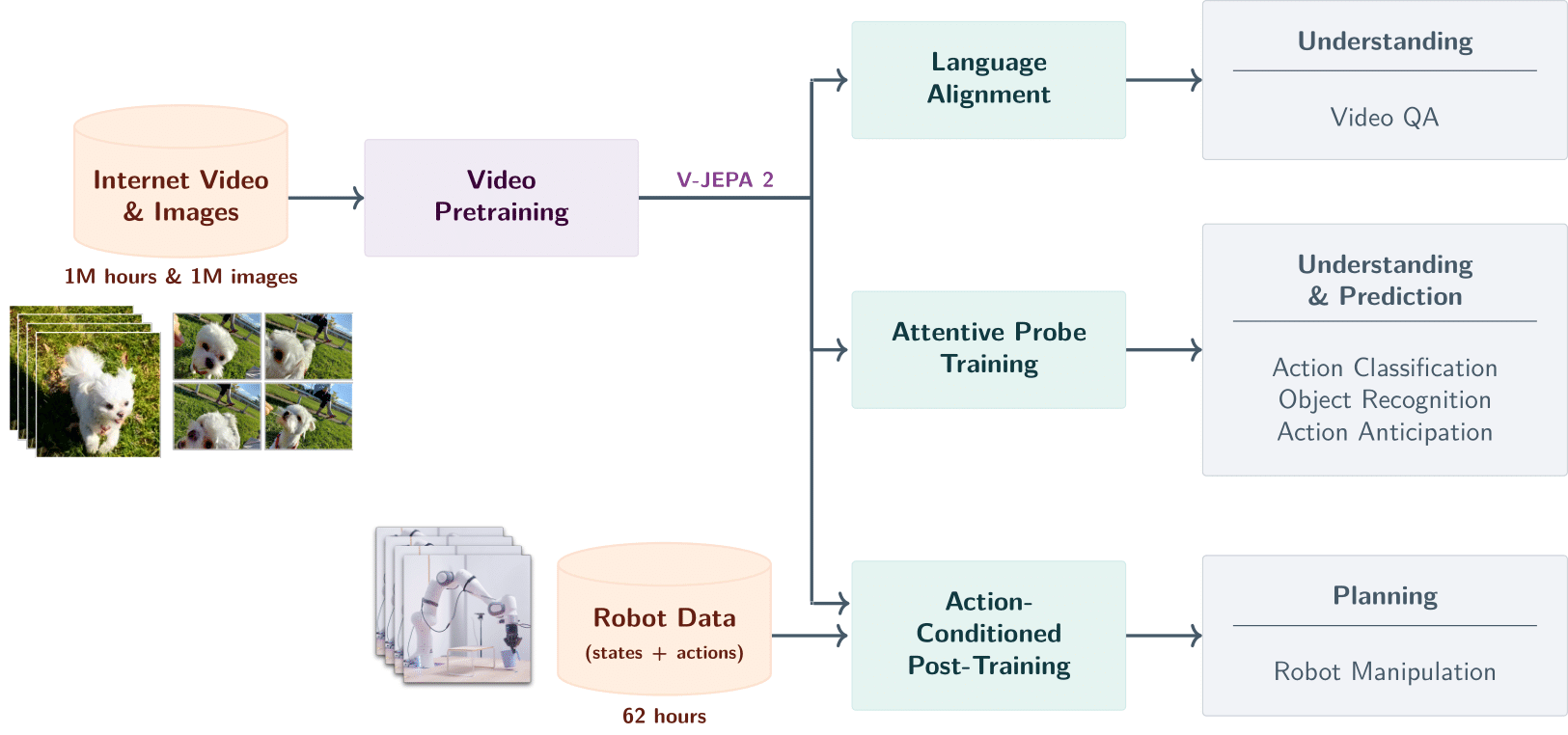
Key Features of V-JEPA 2
-
Understanding the Physical World:
Understands objects, actions, and motion from video input, capturing semantic information in scenes. -
Predicting Future States:
Predicts future video frames or action outcomes based on the current state and actions, supporting both short-term and long-term predictions. -
Planning and Control:
Uses its predictive capabilities for zero-shot robotic planning, enabling robots to complete tasks like grasping, placing, and manipulating objects in unfamiliar environments. -
Video Question Answering:
When integrated with language models, it can answer questions related to video content, including physical causality, action prediction, and scene understanding. -
Generalization:
Demonstrates strong generalization in unseen environments and with novel objects, supporting zero-shot learning and adaptation in new scenarios.
Technical Principles of V-JEPA 2
-
Self-Supervised Learning:
Learns general-purpose visual representations from large-scale video data without the need for manual annotations. -
Encoder-Predictor Architecture:
-
Encoder: Converts raw video input into semantic embeddings that capture key information in the video.
-
Predictor: Uses the encoder output and additional context (e.g., action information) to predict future video frames or states.
-
-
Multi-Stage Training:
-
Pretraining Phase: Trains the encoder using large-scale video data to learn general visual representations.
-
Post-training Phase: Fine-tunes an action-conditioned predictor using a small amount of robot interaction data, enabling the model to perform planning and control.
-
-
Action-Conditioned Prediction:
Incorporates action information to predict how specific actions impact the state of the world, supporting model-based predictive control. -
Zero-Shot Planning:
Uses the predictor for zero-shot planning in new environments by optimizing action sequences to achieve a goal, without requiring additional training data.
V-JEPA 2 Project Resources
-
Project Website: https://ai.meta.com/blog/v-jepa-2-world-model-benchmarks/
-
GitHub Repository: https://github.com/facebookresearch/vjepa2
-
Technical Paper: https://scontent-lax3-2.xx.fbcdn.net/v/t39.2365-6
Application Scenarios of V-JEPA 2
-
Robotic Control and Planning:
Enables zero-shot planning for robots, allowing them to complete tasks such as grasping and placing in new environments without additional training data. -
Video Understanding and Question Answering:
Works with language models to answer questions related to video content, supporting action recognition, prediction, and content generation. -
Smart Surveillance and Security:
Detects anomalous behaviors and environmental changes, useful in video surveillance, industrial monitoring, and traffic management. -
Education and Training:
Enhances virtual reality (VR) and augmented reality (AR) experiences, offering immersive environments for skill development and training. -
Healthcare and Wellness:
Assists in rehabilitation training and surgical operations by predicting and analyzing motion, providing real-time feedback and guidance.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts

No comments yet...