
MindOmni – A Multimodal Large Language Model Jointly Developed by Tencent and Tsinghua University, Among Other Institutions
What is MindOmni?
MindOmni is a multimodal large language model developed by Tencent ARC Lab in collaboration with Tsinghua Shenzhen International Graduate School, The Chinese University of Hong Kong, and The University of Hong Kong. It significantly enhances the reasoning and generation capabilities of vision-language models through a reinforcement learning algorithm known as RGPO (Reasoning Generation Policy Optimization).
Using a three-stage training strategy, the model first builds a unified vision-language framework, then applies supervised fine-tuning with chain-of-thought (CoT) data, and finally optimizes its reasoning-generation ability using RGPO. MindOmni excels in multimodal understanding and generation tasks and demonstrates powerful reasoning-generation performance in complex scenarios such as mathematical problem-solving, opening new paths for multimodal AI development.
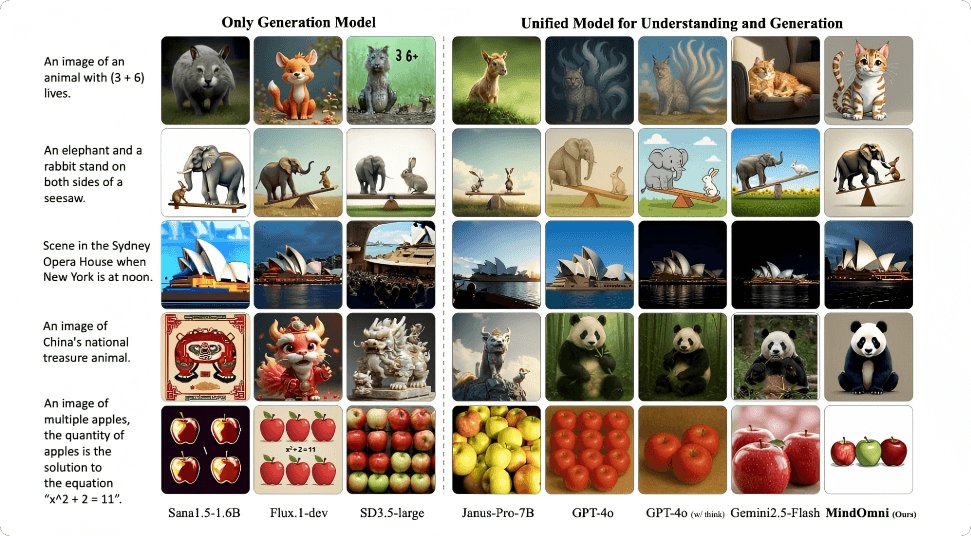
Key Features of MindOmni
-
Visual Understanding: Interprets and analyzes image content, and answers image-related questions.
-
Text-to-Image Generation: Produces high-quality images based on textual descriptions.
-
Reasoning Generation: Performs complex logical reasoning and generates images embedded with reasoning processes.
-
Visual Editing: Edits existing images by adding, removing, or modifying elements.
-
Multimodal Input Processing: Accepts and processes both text and image inputs simultaneously to generate contextually appropriate outputs.
Technical Architecture of MindOmni
-
Model Components:
-
Vision-Language Model (VLM): Uses a pre-trained Vision Transformer (ViT) to extract visual features and a text encoder to convert text into discrete tokens.
-
Lightweight Connector: Bridges the VLM and the diffusion decoder to ensure seamless feature transfer.
-
Text Head: Handles textual input and output generation.
-
Diffusion Decoder Module: Generates images through a denoising process that transforms latent noise into visual outputs.
-
-
Three-Stage Training Strategy:
-
Stage 1 – Pretraining:
Equips the model with basic text-to-image generation and editing capabilities. Trains on image-text pairs and X2I datasets to link the VLM and diffusion decoder. Optimization is guided by diffusion loss and KL divergence loss. -
Stage 2 – CoT Fine-Tuning:
Uses Chain-of-Thought (CoT) instruction data to improve logical reasoning generation. A series of coarse-to-fine CoT instructions are used to supervise and fine-tune the model. -
Stage 3 – Reinforcement Learning with RGPO:
Enhances the quality and accuracy of generated content using multimodal feedback signals (text + image features). Introduces:-
Reasoning Generation Policy Optimization (RGPO) algorithm
-
Format and Consistency Reward Functions to evaluate vision-language alignment
-
KL Divergence Regularization to stabilize training and avoid catastrophic forgetting
-
-
Project Resources
-
Official Website: https://mindomni.github.io/
-
GitHub Repository: https://github.com/TencentARC/MindOmni
-
arXiv Paper: https://arxiv.org/pdf/2505.13031
-
Online Demo: https://huggingface.co/spaces/stevengrove/MindOmni
Application Scenarios of MindOmni
-
Content Creation: Generates high-quality images from text descriptions, useful for creative industries such as advertising, gaming, and film production, accelerating the design and ideation process.
-
Education: Produces visuals and explanatory graphics aligned with teaching materials, helping students understand and retain complex concepts more effectively.
-
Entertainment Industry: Generates characters, scenes, and props for game development; provides storyboards and concept art for film production, enhancing creative expression.
-
Advertising: Creates compelling visuals and promotional content to boost marketing performance.
-
Smart Assistants: Combines voice, text, and image inputs to offer more natural and intelligent user interactions, catering to a wide range of user needs.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...