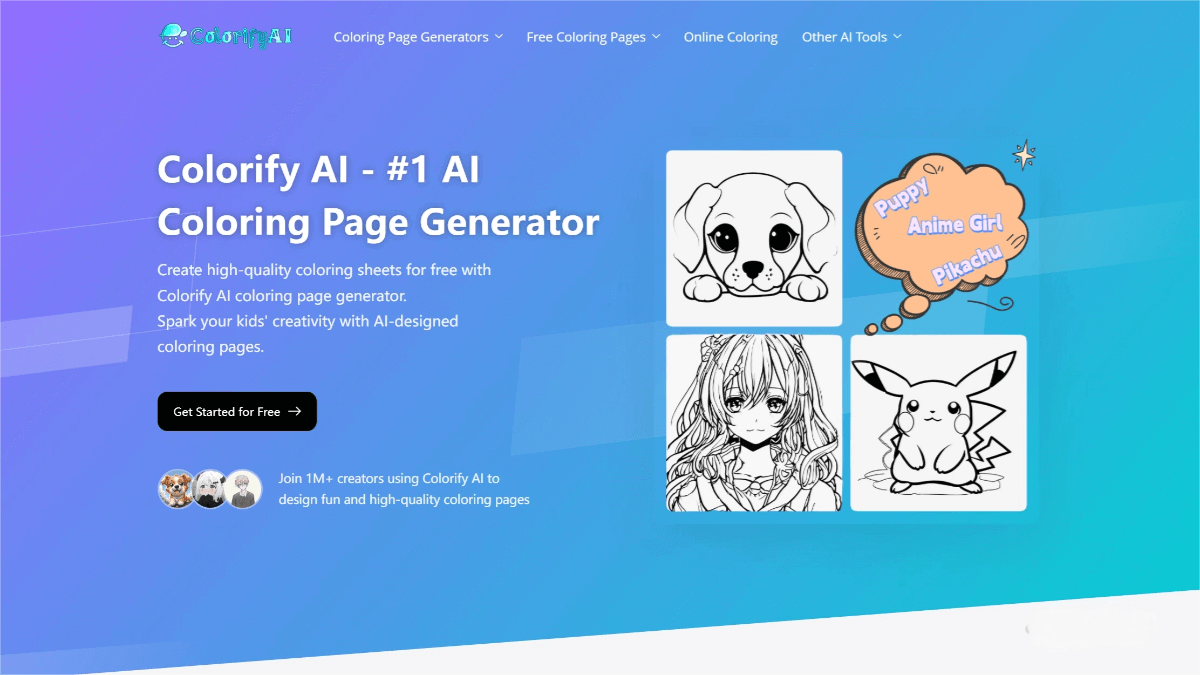
What is Kwai Keye-VL?
Kwai Keye-VL is a multimodal large language model independently developed by Kuaishou. It integrates the Qwen3-8B language model with a SigLIP-initialized visual encoder and supports dynamic resolution input. The model deeply fuses and processes text, image, and video data, offering a new paradigm of intelligent and comprehensive multimodal interaction through its innovative adaptive interaction mechanisms and dynamic reasoning capabilities. It excels in video understanding, complex visual perception, and logical reasoning — notably achieving an impressive 140 out of 150 on the 2025 Chinese National College Entrance Exam (Gaokao) math test. The model has been open-sourced, providing robust support for multimodal research and applications.

Main Features of Kwai Keye-VL
-
Video Understanding: Deeply analyzes short video content by recognizing scenes, people, actions, etc., and generates descriptions, tags, or content recommendations.
-
Image Recognition and Description: Automatically identifies objects and scenes in images, providing accurate descriptions.
-
Logical Reasoning: Performs exceptionally in logical reasoning tasks, such as solving math problems or conducting scientific inference.
-
Multimodal Interaction: Capable of handling and integrating text, image, and video information, enabling seamless cross-modal interactions.
-
Intelligent Content Creation: Assists users in creating content such as copywriting, scripts, or creative proposals based on its understanding of multimodal information.
Technical Principles of Kwai Keye-VL
-
Model Architecture:
Built on the Qwen3-8B language model and enhanced with a SigLIP-initialized visual encoder. It supports dynamic resolution input and processes images sliced into 14×14 patches while maintaining aspect ratio. An MLP layer aggregates visual features. The model employs 3D RoPE (Rotary Positional Encoding) to unify the processing of text, images, and videos, aligning positional encodings and timestamps to accurately capture temporal dynamics in videos. -
Pretraining Strategy:
-
Continuously pretrains the visual encoder to adapt to internal data distributions and support dynamic resolutions.
-
Freezes the backbone model and trains only lightweight MLP adapters to establish robust alignment between image/video and text with minimal computational cost.
-
Unlocks all model parameters for joint multi-task training to enhance comprehensive visual understanding.
-
Fine-tunes on curated high-quality data for refined understanding and discrimination.
-
Explores isomorphic-heterogeneous fusion techniques, using parameter averaging to combine models trained with different data compositions, reducing bias while retaining diverse capabilities and improving robustness.
-
-
Post-training Strategy:
-
No-Reasoning Training: Uses 5 million high-quality multimodal VQA data points, with task diversity ensured by the proprietary TaskGalaxy system (including 70,000 types of tasks). Data quality is enhanced through AI-selected hard samples and manual annotation. Combines open-source data with curated preference data (e.g., SFT error-based prompts, answers generated by Qwen2.5VL 72B vs. SFT model, manually ranked).
-
Reasoning Training: Trains on datasets representing four types of reasoning patterns to trigger the model’s chain-of-thought ability from scratch. Uses GRPO (Guided Reinforcement with Preference Optimization) for hybrid-mode reinforcement learning, leveraging a dual-track reward system that evaluates both correctness of results and consistency of reasoning processes. This significantly improves capabilities in multimodal perception, mathematical reasoning, short video understanding, and agent collaboration. Employs MPO (Maximum Preference Optimization) for iterative training on good-bad data pairs to eliminate repetitive failures and logic gaps, enabling the model to adaptively choose deep reasoning paths based on task complexity — achieving breakthroughs in both performance and stability.
-
Project Links for Kwai Keye-VL
-
Official Website: https://kwai-keye.github.io/
-
GitHub Repository: https://github.com/Kwai-Keye/Keye/tree/main
-
HuggingFace Model Hub: https://huggingface.co/Kwai-Keye
Application Scenarios for Kwai Keye-VL
-
Video Content Creation: Assists short video creators in quickly generating titles, descriptions, and scripts, boosting creative efficiency.
-
Intelligent Customer Service: Provides intelligent customer support through multimodal interaction (text, voice, images), enhancing user experience.
-
Educational Tutoring: Offers personalized learning assistance, including homework help and knowledge explanations, to support students.
-
Advertising and Marketing: Helps advertisers generate compelling copy and scripts to improve ad performance.
-
Medical Assistance: Aids doctors in analyzing medical images and offering preliminary diagnostic suggestions, improving medical efficiency.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...