
DRA-Ctrl – A cross-modal image editing framework jointly developed by Zhejiang University, Ant Group, and other institutions
What is DRA-Ctrl?
DRA-Ctrl (Dimension-Reduction Attack Control) is an innovative cross-modal image editing framework developed by Zhejiang University in collaboration with Ant Group and other institutions. The framework leverages the high-dimensional feature representations of video generation models—including visual, temporal, spatial, and causal dimensions—to predict and accurately edit the states of image subjects. By applying knowledge compression and task adaptation from videos to images, DRA-Ctrl effectively bridges the gap between continuous video frames and discrete image generation using long-range context modeling and flat full-attention mechanisms of video models. Experiments show that DRA-Ctrl outperforms models trained directly on images across various image generation tasks, offering new possibilities for applying large-scale video generators in broader visual domains.
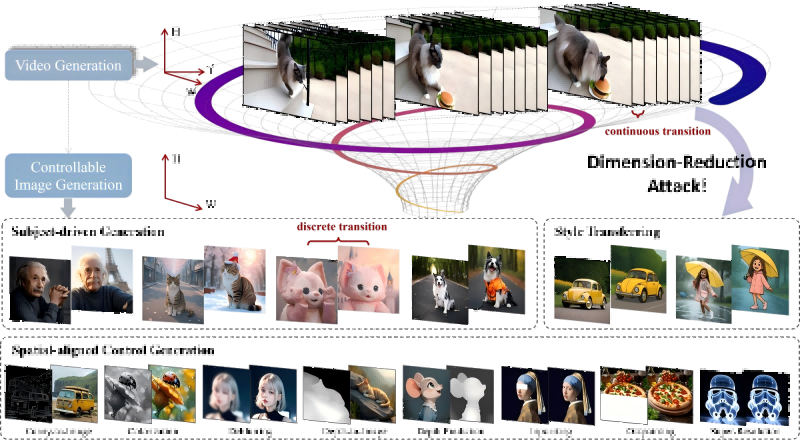
Key Features of DRA-Ctrl
-
Multi-task Support: DRA-Ctrl supports a wide range of image generation tasks, including subject-driven generation, spatially conditioned generation, Canny-to-image, colorization, deblurring, depth-to-image, depth prediction, inpainting/outpainting, super-resolution, and style transfer. It demonstrates strong cross-task adaptability.
-
High-Quality Generation: Leveraging high-dimensional feature representations from video generation models, DRA-Ctrl produces high-quality images, outperforming models trained solely on images.
-
Cross-modal Adaptation: DRA-Ctrl transfers the knowledge of video generation models to image generation tasks through effective compression techniques, enabling robust cross-modal knowledge migration.
Technical Principles of DRA-Ctrl
-
High-Dimensional Feature Representation from Video Models: Video generation models capture rich, dynamic, and continuous high-dimensional information across visual, temporal, spatial, and causal dimensions, providing abundant context for image generation tasks.
-
Video-to-Image Knowledge Compression: This involves transferring the capabilities of video models to image tasks using a variety of strategies, such as mixup-based transformation, Frame Skipping Positional Embedding (FSPE), re-weighted loss, and attention masking.
-
Mixup-based Transformation Strategy: To bridge the gap between continuous video frames and discrete image generation, DRA-Ctrl introduces a mixup-based transformation strategy to ensure smooth transition from video to image tasks.
-
Frame Skipping Positional Embedding (FSPE): By embedding the positions of skipped frames, DRA-Ctrl better handles the discontinuity between video frames, enhancing the quality of image generation.
-
Loss Re-weighting: During training, DRA-Ctrl re-weights the loss associated with different frames to help the model focus on learning features most relevant to image generation.
-
Attention Masking Strategy: DRA-Ctrl redesigns the attention mechanism with custom masking to better align text prompts with image-level controls.
Project Resources for DRA-Ctrl
-
Official Website: https://dra-ctrl-2025.github.io/DRA-Ctrl/
-
GitHub Repository: https://github.com/Kunbyte-AI/DRA-Ctrl
-
HuggingFace Model Hub: https://huggingface.co/Kunbyte/DRA-Ctrl
-
arXiv Paper: https://arxiv.org/pdf/2505.23325
Application Scenarios of DRA-Ctrl
-
Content Creation: Enables artists and designers to quickly generate creative images, accelerating the design process and enhancing productivity.
-
Film and Animation Production: Generates high-quality backgrounds, characters, and scenes, reducing the manual workload in visual effects and animation.
-
Game Development: Assists game developers in creating immersive characters, props, and environments, improving visual appeal and user engagement.
-
Advertising and Marketing: Helps ad agencies generate visually compelling promotional images tailored to diverse client needs.
-
Education and Training: Supports the generation of educational content such as scientific illustrations and historical scenes, enhancing teaching effectiveness.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts



No comments yet...