
VLN-R1 – An Embodied Intelligence Framework by HKU and Shanghai AI Lab
What is VLN-R1?
VLN-R1 is a novel embodied intelligence framework developed jointly by The University of Hong Kong and the Shanghai AI Laboratory. It leverages Large Vision-Language Models (LVLMs) to directly convert first-person video streams into continuous navigation actions. Built on the Habitat 3D simulator, VLN-R1 constructs the VLN-Ego dataset and uses a long-short memory sampling strategy to balance historical and real-time observations. The training process includes two stages: Supervised Fine-Tuning (SFT), which aligns model-predicted action sequences with expert demonstrations, and Reinforcement Fine-Tuning (RFT), which optimizes multi-step future actions using a Time-Decay Reward (TDR) mechanism. VLN-R1 demonstrates strong performance on the VLN-CE benchmark, validating the effectiveness of LVLMs in embodied navigation with enhanced task-specific reasoning and high data efficiency.
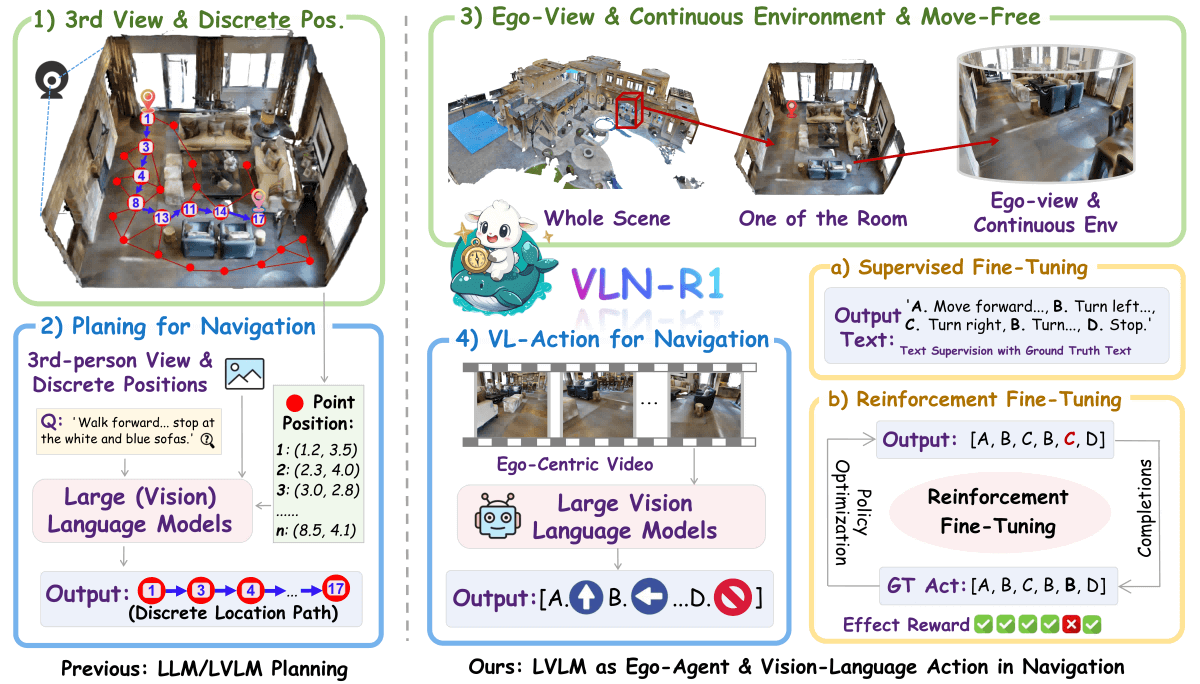
Key Features of VLN-R1
-
Continuous Environment Navigation: VLN-R1 processes raw first-person video streams, enabling agents to move freely in continuous 3D environments beyond pre-defined navigation nodes.
-
Action Generation: It produces four fundamental action commands—FORWARD, TURN-LEFT, TURN-RIGHT, and STOP—for precise and reliable navigation control.
-
Data-Efficient Training: Through SFT and RFT, VLN-R1 achieves high navigation performance with limited training data.
-
Cross-Domain Adaptation: Leveraging RFT, the model can quickly adapt to new environments and navigation tasks even with scarce data.
-
Task-Specific Reasoning: The TDR mechanism enhances long-term reasoning and planning by optimizing predictions of multi-step future actions.
Technical Principles of VLN-R1
-
Dataset Construction: The VLN-Ego dataset is built on the Habitat 3D simulator, featuring first-person video streams and corresponding future action predictions, providing rich data for training.
-
Long-Short Memory Sampling: A dynamic sampling strategy balances the significance of past frames and real-time inputs, ensuring the model retains both short-term relevance and long-term context during navigation.
-
Supervised Fine-Tuning (SFT): The model is aligned with expert demonstrations by minimizing cross-entropy loss between predicted and actual action sequences, ensuring accurate interpretation of language instructions.
-
Reinforcement Fine-Tuning (RFT): Using Group-relative Policy Optimization (GRPO), this stage incorporates a Time-Decay Reward (TDR) strategy to evaluate and refine multi-step action predictions, strengthening long-horizon navigation.
-
Large Vision-Language Models (LVLMs): Leveraging advanced LVLMs (e.g., Qwen2-VL), VLN-R1 maps visual and language inputs directly to navigation actions, enhancing generalization and adaptability.
Project Links for VLN-R1
-
Project Website: https://vlnr1.github.io/
-
GitHub Repository: https://github.com/Qi-Zhangyang/GPT4Scene-and-VLN-R1
-
arXiv Paper: https://arxiv.org/pdf/2506.17221
Application Scenarios for VLN-R1
-
Home Service Robots: Enables household robots to navigate freely based on natural language instructions from residents, completing tasks like cleaning or item retrieval to improve daily convenience.
-
Industrial Automation: Assists factory robots in navigating production floors based on operator commands, performing material handling and equipment maintenance to boost productivity.
-
Smart Warehousing: Supports warehouse robots in navigating between shelves according to verbal instructions, efficiently storing and retrieving goods to streamline inventory management.
-
Healthcare Support: Empowers service robots in hospitals or care homes to deliver medication or meals based on commands from staff or patients, easing workloads for healthcare professionals.
-
Intelligent Transportation: Assists autonomous vehicles in navigating complex urban environments based on traffic signals and verbal instructions, improving driving safety and adaptability.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts

No comments yet...