Step-Audio-AQAA – An end-to-end large audio language model developed by StepFun
What is Step-Audio-AQAA?
Step-Audio-AQAA is an end-to-end large audio language model developed by the StepFun team, specifically designed for Audio Query-Audio Answer (AQAA) tasks. It can directly process audio input to generate natural and accurate speech responses without relying on traditional Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) modules, simplifying the system architecture and eliminating cascading errors.
The training process of Step-Audio-AQAA includes multimodal pre-training, supervised fine-tuning (SFT), direct preference optimization (DPO), and model merging. Through these methods, the model demonstrates excellent performance in complex tasks such as speech emotion control, role-playing, and logical reasoning. In the StepEval-Audio-360 benchmark test, Step-Audio-AQAA outperformed existing LALM models across multiple key dimensions, showcasing its strong potential in end-to-end speech interaction.
Step-Audio-AQAA Key Features
-
Direct Audio Processing: Generates speech responses directly from raw audio input, bypassing traditional ASR and TTS pipelines.
-
Seamless Voice Interaction: Supports voice-to-voice interaction, allowing users to ask questions via speech and receive spoken answers, enhancing naturalness and fluency.
-
Emotion & Tone Control: Adjusts emotion (e.g., happiness, sadness, seriousness) and intonation at the sentence level.
-
Speech Rate Control: Allows users to modify the speed of responses for different scenarios.
-
Timbre & Pitch Adjustment: Adapts voice characteristics (timbre, pitch) based on user instructions, suitable for role-playing or contextual needs.
-
Multilingual Support: Works with Chinese, English, Japanese, and more.
-
Dialect Support: Covers Sichuan dialect, Cantonese, and other Chinese dialects for regional adaptability.
-
Emotional Speech Generation: Produces context-aware emotional responses.
-
Role-Playing: Simulates roles like customer service agents, teachers, or friends with role-appropriate speech.
-
Logical Reasoning & Q&A: Handles complex reasoning and knowledge-based questions with accurate spoken answers.
-
High-Fidelity Speech Output: Uses a neural vocoder to generate natural, high-quality speech waveforms.
-
Speech Coherence: Maintains fluency and consistency in long sentences or paragraphs.
-
Mixed Text & Audio Output: Supports interleaved text and speech responses based on user preference.
-
Multimodal Input Understanding: Processes hybrid inputs (speech + text) and generates corresponding speech replies.
Technical Principles
-
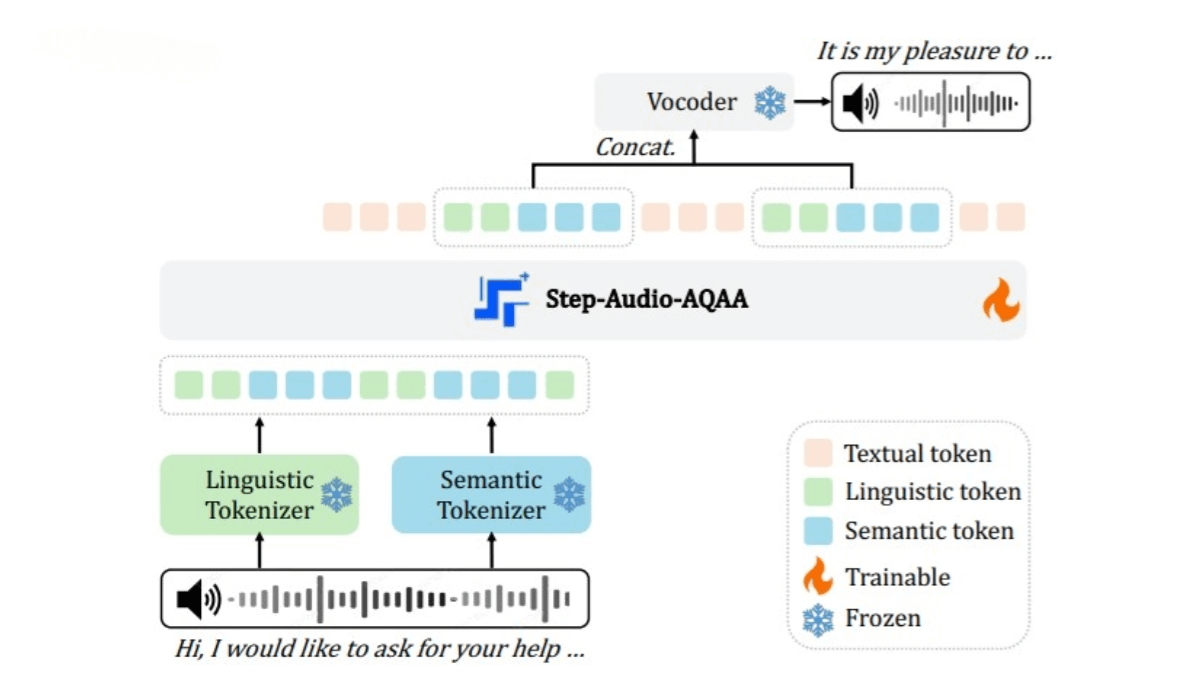
Dual-Codebook Audio Tokenizer
-
Converts audio signals into structured token sequences.
-
Two tokenizers:
-
Linguistic Tokenizer: Extracts phonemes & linguistic attributes (sampled at 16.7 Hz, codebook size 1024).
-
Semantic Tokenizer: Captures acoustic features (emotion, tone) (sampled at 25 Hz, codebook size 4096).
-
-
Effectively captures complex speech information.
-
-
Backbone LLM
-
Uses Step-Omni, a 130B-parameter multimodal LLM pre-trained on text, speech, and image data.
-
Embeds dual-codebook tokens into a unified vector space for deep semantic understanding via Transformer blocks.
-
-
Neural Vocoder
-
Synthesizes high-quality speech waveforms from generated audio tokens.
-
Based on a U-Net architecture with ResNet-1D layers + Transformer blocks, efficiently converting discrete tokens into continuous speech.
-
Project Links
-
Hugging Face Model Hub: https://huggingface.co/stepfun-ai/Step-Audio-AQAA
-
arXiv Paper: https://arxiv.org/pdf/2506.08967
Applications
-
Emotional Companion Robots: Adapts responses based on user mood, providing emotional support.
-
Multilingual Customer Service: Handles dialect-based queries and supports multiple languages.
-
Game NPC Interaction: Generates real-time emotional speech for dynamic in-game dialogues.
-
Smart Voice Assistants: Enables voice-based queries & reminders (e.g., schedules, info retrieval).
-
Education & Entertainment: Used for voice-based teaching, storytelling, poetry recitation, with flexible text/speech output switching.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...