
What is Voxtral?
Voxtral is an advanced audio model developed by Mistral AI, designed to advance speech as a natural mode of human-computer interaction through its exceptional transcription and deep understanding capabilities. It is available in two versions—24B for production-scale applications and 3B for local deployment. Voxtral supports multiple languages, long-context understanding, built-in question answering and summarization functions, and can directly trigger backend function calls. It outperforms existing open-source models and proprietary APIs across various benchmarks while offering significantly lower costs. Voxtral is widely applied across diverse scenarios, accelerating the adoption of voice-based interaction.
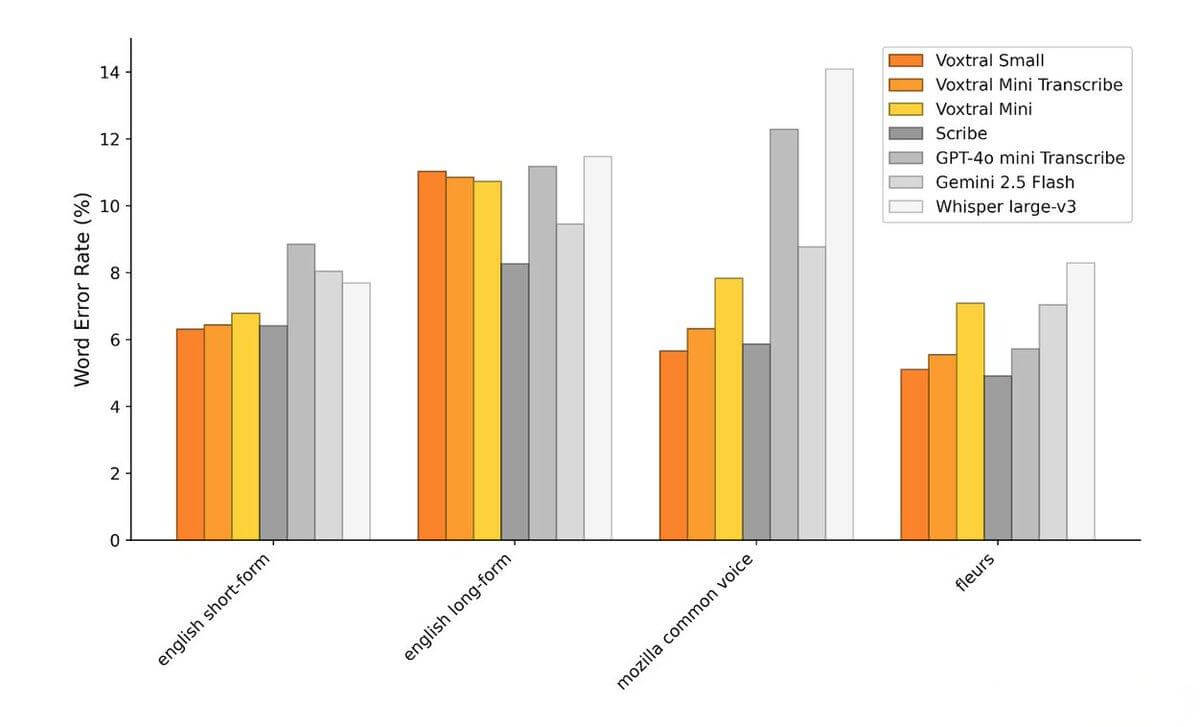
What Are Its Main Features?
-
High-accuracy transcription: Outperforms Whisper large-v3, the current open-source benchmark
-
Semantic audio understanding: Supports tasks like Q&A, summarization, and multilingual context handling
-
Long-form audio support: Handles up to 30 minutes for transcription and 40 minutes for understanding (via 32k token context)
-
Multilingual detection & transcription: Automatically detects and processes languages such as English, Spanish, French, Portuguese, Hindi, German, Dutch, Italian, and more
-
Voice-triggered function calling: Enables speech commands to trigger backend workflows or API calls
-
Built-in reasoning abilities: Inherits text reasoning capabilities from the Mistral Small 3.1 LLM
How Does It Work?
-
Transformer-based architecture: Extends a unified audio-text Transformer backbone
-
End-to-end speech-text modeling: Combines ASR and semantic reasoning into a single framework
-
32k-token context window: Allows complex reasoning over extended audio segments
-
Apache 2.0 license: Fully open-source and available for commercial use
-
Optimized for vLLM deployment: Integrated with vLLM, enabling function calling and interactive speech-driven applications
Project Resources
-
Official launch blog: https://mistral.ai/news/voxtral
-
Hugging Face model hubs:
-
Voxtral Small (24B): Voxtral-Small-24B-2507
-
Voxtral Mini (3B): Voxtral-Mini-3B-2507
-
Use Cases
-
Meeting transcription and summarization: Converts lengthy audio into structured, readable summaries
-
Voice-driven automation: Enables commands like “Add to calendar” or “Send email” via voice
-
Multilingual customer service: Supports real-time semantic conversations in multiple languages
-
Edge devices and IoT: The Mini version is ideal for privacy-sensitive, on-device speech processing
-
Enterprise-grade voice systems: Offers private deployment, domain-specific fine-tuning, speaker detection, and emotion analysis
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts



No comments yet...