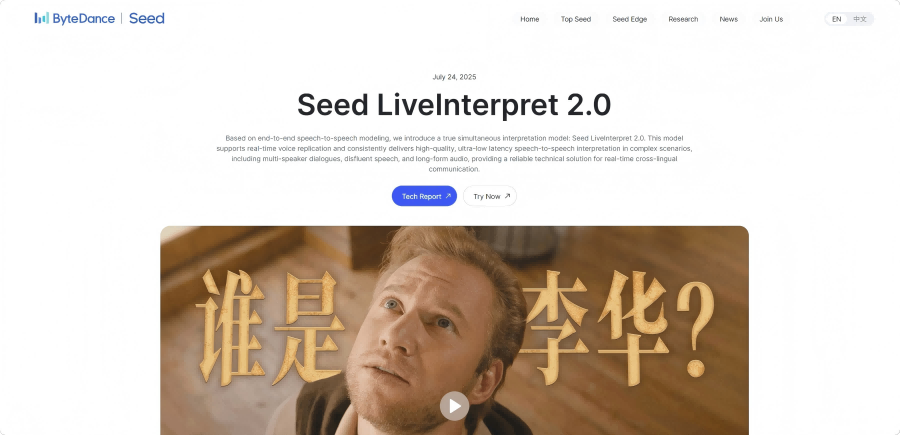
Seed LiveInterpret 2.0 – ByteDance’s “Seed” simultaneous interpretation model
What is Seed LiveInterpret 2.0?
Seed LiveInterpret 2.0 is an end-to-end simultaneous interpretation model developed by ByteDance’s Seed team. It supports bidirectional translation between Chinese and English with near-human-level accuracy and ultra-low latency, enabling real-time “listen and speak” translation. Built on a full-duplex speech generation and understanding framework, the model can handle multi-speaker input and replicate a speaker’s voice in real-time without needing pre-recorded voice samples. In complex scenarios, the translation accuracy exceeds 70%, and in single-speaker settings, it surpasses 80%. The average speech-to-speech delay is only 2–3 seconds—over 60% lower than traditional systems. Seed LiveInterpret 2.0 intelligently balances translation quality and latency to adapt to varying speech input conditions. The model is available to external users via Volcano Engine.
Key Features of Seed LiveInterpret 2.0
-
High-fidelity, ultra-low-latency speech-to-speech translation:
Supports two-way translation between Chinese and English with delays as low as 2–3 seconds, approaching professional human interpreter performance. -
Zero-shot voice cloning:
Replicates the speaker’s vocal characteristics in real-time without requiring pre-recorded voice samples, enhancing the naturalness of communication. -
Smart balance between quality and latency:
Dynamically adjusts output pace based on speech clarity and fluency, ensuring optimal trade-off between accuracy and responsiveness. -
Accurate contextual understanding:
Delivers high-quality understanding and translation in complex scenarios like multi-speaker conversations or mixed Chinese-English speech, with the ability to correct potential errors. -
Real-time speech processing:
Supports simultaneous multi-speaker input and outputs translated speech continuously, just like a human interpreter.
Technical Architecture of Seed LiveInterpret 2.0
-
Full-duplex speech understanding and generation framework:
Seed LiveInterpret 2.0 uses a full-duplex end-to-end speech-to-speech architecture, capable of processing incoming speech and generating translated output simultaneously. This allows it to mimic human interpreters with extremely low latency, delivering real-time translated speech as it listens to the source language. -
Multimodal Large Language Model (LLM):
The model is powered by a multimodal LLM that integrates an audio encoder with a language model through large-scale pretraining and continual multitask learning. The pretraining corpus includes audio-to-text transcription, text-to-audio synthesis, and pure text processing tasks to enhance speech understanding and generation capabilities. -
Supervised Fine-tuning (SFT):
Following multimodal pretraining, the model is fine-tuned using high-quality human-annotated data. This improves the timing and accuracy of translations, significantly boosting performance, especially in complex environments. -
Reinforcement Learning (RL):
To further reduce latency and enhance translation quality, reinforcement learning is employed. Using process-level (single-turn) and outcome-level (multi-turn) reward models, the system learns to dynamically adjust its translation strategy during training, striking a better balance between quality and latency. -
Zero-shot voice cloning:
The model can clone a speaker’s voice in real time without needing pre-recorded samples. It extracts the speaker’s vocal features on the fly and speaks in that voice in the target language, improving immersion and communication fluidity. -
Intelligent quality-latency tradeoff:
Based on the clarity, fluency, and complexity of incoming speech, the model automatically adjusts translation timing. It responds quickly to fluent input, while waiting for clearer content when input is fragmented—ensuring better accuracy. -
Robust in complex scenarios:
Leveraging deep speech understanding capabilities, Seed LiveInterpret 2.0 excels in handling noisy input, speaker overlap, language mixing, and unstructured speech. It can resolve ambiguities and produce accurate, natural translations.
Project Links
-
Official Website: https://seed.bytedance.com/zh/seed_liveinterpret
-
Technical Paper (arXiv): https://arxiv.org/pdf/2507.17527
Application Scenarios of Seed LiveInterpret 2.0
-
International Conferences:
Enables real-time translation of speeches, helping participants from different language backgrounds fully engage with conference content. -
Multilingual Live Streaming:
Provides real-time interpretation for live audiences, breaking down language barriers in global broadcasts. -
Remote Education:
Facilitates real-time interaction between teachers and students across language boundaries. For example, in international online courses, students can listen to lectures and participate in discussions while teachers can understand and respond to their questions instantly. -
Cross-border Business Communication:
Assists in real-time translation during business meetings and negotiations, ensuring precise and efficient communication between parties. -
Tourism and Cultural Exchange:
Helps travelers engage with locals more effectively and understand cultural and historical context through real-time interpretation.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts

No comments yet...