
GLM-4.5V – Zhipu’s latest open-source generation of vision reasoning models
What is GLM-4.5V?
GLM-4.5V is the latest generation visual reasoning model released by Zhipu. Built on a 106-billion-parameter architecture with 12 billion active parameters, it is currently one of the leading visual-language models (VLMs). The model is an upgrade based on GLM-4.1V-Thinking, inheriting its excellent architecture and trained together with the new generation text foundation model GLM-4.5-Air. GLM-4.5V demonstrates outstanding performance in visual understanding and reasoning, suitable for applications such as web frontend replication, visual grounding, image search games, and video understanding. It is expected to drive further advancement in multimodal applications.
To help developers intuitively experience GLM-4.5V’s powerful capabilities and build custom multimodal applications, the team has open-sourced a desktop assistant app that supports real-time screenshot and screen recording, leveraging GLM-4.5V for tasks including code assistance, video analysis, game answering, and document interpretation.
Key Features of GLM-4.5V
-
Visual Understanding and Reasoning: Capable of analyzing images, videos, and other visual content, performing complex visual reasoning tasks such as object recognition, scene understanding, and relationship inference.
-
Multimodal Interaction: Supports fusion of text and visual content, such as generating images from text descriptions or creating textual descriptions based on images.
-
Web Frontend Replication: Generates frontend code from webpage design images to accelerate web development.
-
Image Search Games: Supports image-based search and matching tasks, finding specific targets in complex scenes.
-
Video Understanding: Analyzes video content to extract key information, perform summarization, and detect events.
-
Cross-Modal Generation: Enables seamless conversion between visual content and text, supporting multimodal content generation.
Technical Principles
-
Large-scale Pretraining: Built on a 106-billion-parameter pretrained architecture trained with massive amounts of text and visual data to learn joint language-vision representations.
-
Vision-Language Fusion: Uses a Transformer architecture to fuse text and visual features via cross-attention mechanisms enabling interaction between modalities.
-
Activation Mechanism: Incorporates 12 billion activation parameters that dynamically activate relevant parameter subsets during inference to improve computational efficiency and performance.
-
Structural Inheritance and Optimization: Inherits the superior structure of GLM-4.1V-Thinking and is further trained with the next-gen text base model GLM-4.5-Air to enhance capabilities.
-
Multimodal Task Adaptation: Fine-tuned and optimized to handle diverse multimodal tasks such as visual question answering, image captioning, and video understanding.
Performance Highlights
-
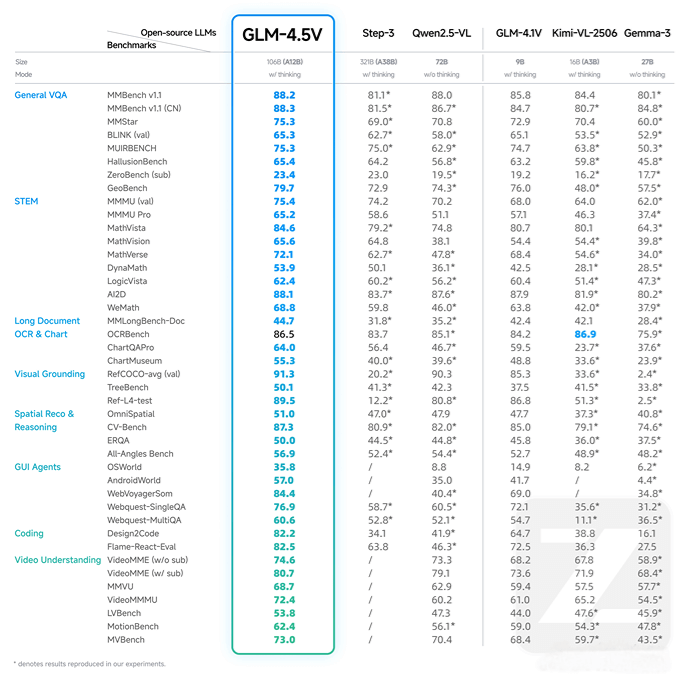
General VQA: Achieves top performance in general visual question answering, scoring 88.2 on the MMBench v1.1 benchmark.
-
STEM Tasks: Leads in science, technology, engineering, and mathematics tasks, scoring 84.6 on the MathVista test.
-
Long Document OCR & Charts: Excels in OCRBench for long documents and charts with a score of 86.5.
-
Visual Grounding: Outstanding visual grounding performance with a 91.3 score on the RefCOCO+loc (val) test.
-
Spatial Reasoning: Achieves 87.3 on CV-Bench for spatial reasoning abilities.
-
Coding: Demonstrates strong coding skills, scoring 82.2 on the Design2Code benchmark.
-
Video Understanding: Performs well in video understanding with a 74.6 score on the VideoMME (w/o sub) test.
Project Links
-
GitHub Repository: https://github.com/zai-org/GLM-V/
-
HuggingFace Model Hub: https://huggingface.co/collections/zai-org/glm-45v-68999032ddf8ecf7dcdbc102
-
Technical Paper: https://github.com/zai-org/GLM-V/tree/main/resources/GLM-4.5V_technical_report.pdf
-
Desktop Assistant App: https://huggingface.co/spaces/zai-org/GLM-4.5V-Demo-App
How to Use GLM-4.5V
-
Register and Log In: Visit the Z.ai official website and register with your email.
-
Select Model: After logging in, choose GLM-4.5V from the model dropdown menu.
-
Experience Features:
-
Web frontend replication: Upload webpage design images to generate frontend code automatically.
-
Visual reasoning: Upload images or videos for object recognition, scene analysis, and more.
-
Image search games: Upload target images for matching in complex scenes.
-
Video understanding: Upload videos to extract key information, generate summaries, or detect events.
-
API Pricing
-
Input: 2 RMB per million tokens
-
Output: 6 RMB per million tokens
-
Response speed: 60–80 tokens per second
Use Cases
-
Web Frontend Replication: Quickly generate frontend code from design images, helping developers efficiently build webpages.
-
Visual Question Answering: Provide accurate answers to user questions based on image content, applicable in education and intelligent customer service.
-
Image Search Games: Quickly locate target images in complex scenes, useful for security monitoring, smart retail, and game development.
-
Video Understanding: Analyze video content to extract summaries or detect events, optimizing video recommendations, editing, and monitoring.
-
Image Captioning: Generate precise textual descriptions for images to assist visually impaired users and enhance social media sharing experiences.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...