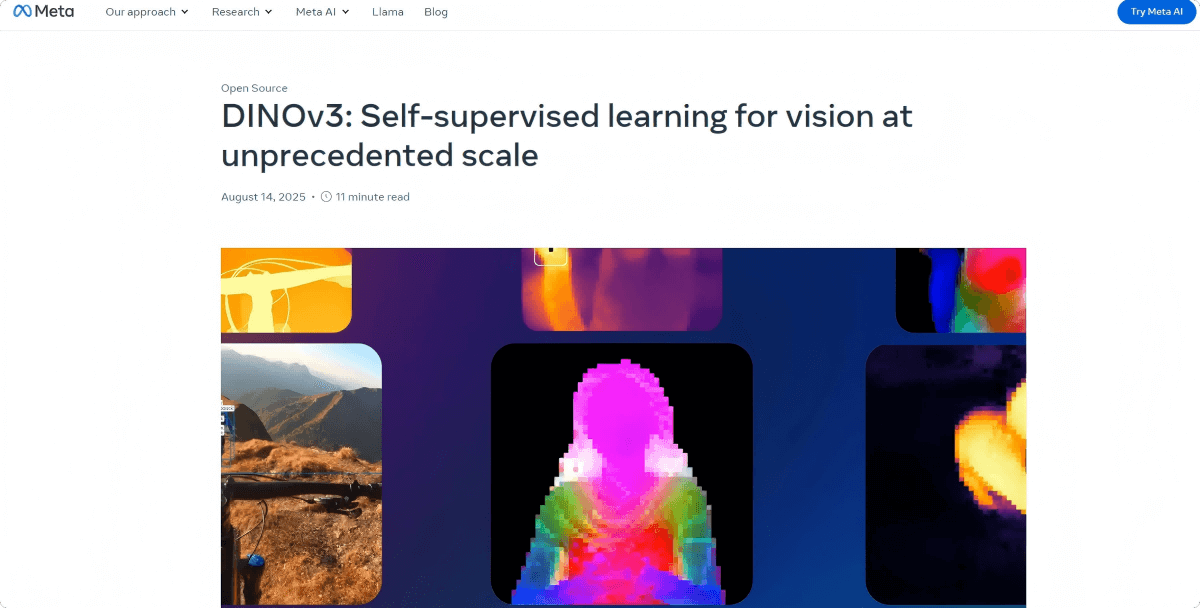
DINOv3 – Meta’s Open-Source General-Purpose Vision Foundation Model
What is DINOv3?
DINOv3 is a general-purpose, state-of-the-art (SOTA) vision foundation model developed by Meta. Trained on unlabeled data, the model generates high-quality, high-resolution visual features suitable for multiple tasks, including image classification, semantic segmentation, and object detection. DINOv3 has 7 billion parameters and was trained on 1.7 billion images, achieving performance that surpasses weakly supervised models. The model offers multiple variants to accommodate different computational needs. Its open-source training code and pre-trained models provide strong support for computer vision research and application development.
Key Features of DINOv3
-
High-Resolution Visual Feature Extraction: Produces high-quality, high-resolution visual features for fine-grained image analysis and multiple vision tasks.
-
Multi-Task Support Without Fine-Tuning: Supports multiple downstream tasks in a single forward pass without requiring fine-tuning, significantly reducing inference cost.
-
Wide Applicability: Suitable for web images, satellite imagery, medical imaging, and other domains, including scenarios with scarce annotations.
-
Diverse Model Variants: Offers multiple model variants (e.g., ViT-B, ViT-L, and ConvNeXt architectures) to meet different computational resource requirements.
Technical Principles of DINOv3
-
Self-Supervised Learning (SSL): Uses self-supervised learning to train the model without labeled data. Through contrastive learning, DINOv3 learns general visual features from vast amounts of unlabeled images, reducing data preparation costs and improving generalization.
-
Gram Anchoring Strategy: Introduces Gram Anchoring to mitigate the collapse of dense features, generating clearer and more semantically consistent feature maps, improving performance on high-resolution image tasks.
-
Rotary Position Encoding (RoPE): Employs RoPE to avoid limitations of fixed positional encodings, naturally adapting to inputs of different resolutions for flexible and efficient multi-scale image processing.
-
Model Distillation: Transfers knowledge from large models (e.g., ViT-7B) to smaller variants (e.g., ViT-B and ViT-L), retaining performance while improving deployment efficiency for different computing environments.
Project Links
-
Official Website: https://ai.meta.com/blog/dinov3-self-supervised-vision-model/
-
HuggingFace Model Hub: https://huggingface.co/docs/transformers/main/en/model_doc/dinov3
-
Technical Paper: https://ai.meta.com/research/publications/dinov3/
Application Scenarios
-
Environmental Monitoring: Analyzes satellite imagery to monitor deforestation, land-use changes, and supports environmental research and conservation efforts.
-
Medical Imaging Diagnostics: Processes large volumes of unlabeled medical images to assist in pathology, endoscopy, and other tasks, enhancing diagnostic efficiency.
-
Autonomous Driving: Supports accurate road scene understanding and obstacle detection through powerful object detection and semantic segmentation capabilities.
-
Retail & Logistics: Monitors retail store inventory, analyzes customer behavior, and identifies/classifies items in logistics centers.
-
Disaster Response: Quickly analyzes satellite and drone imagery after disasters to assess affected areas and support rescue operations.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...