
NVIDIA NeMo™ Nano 2 – A high-efficiency inference model launched by NVIDIA
What is NVIDIA NeMo™ Nano 2?
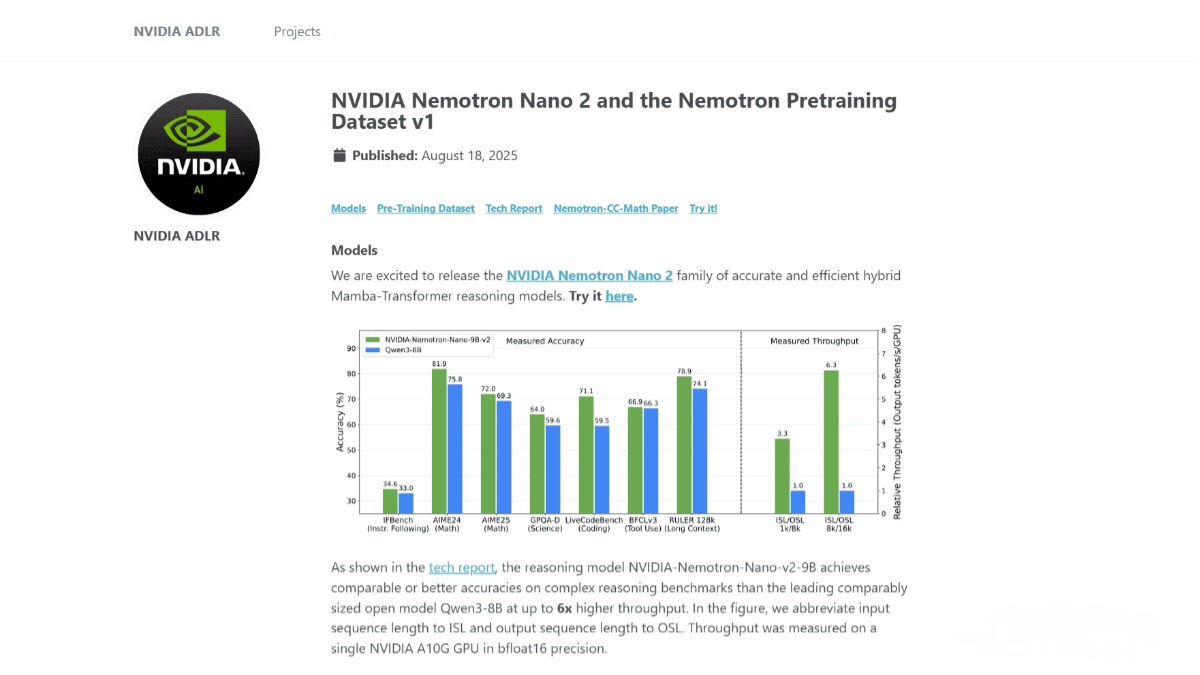
NVIDIA NeMo™ Nano 2 is a high-efficiency inference model released by NVIDIA, with 9 billion parameters. The model is based on a hybrid Mamba-Transformer architecture and was pre-trained on 20 trillion tokens, supporting a context length of 128K. Compared to Qwen3-8B, it achieves 6× faster inference speed while maintaining comparable or higher accuracy. The model also features a reasoning budget control, allowing users to specify the number of inference tokens. NVIDIA has open-sourced the base model along with most of the pre-training datasets, enabling developers to further research and apply the model.
Key Features of NVIDIA NeMo™ Nano 2
-
High Throughput: Excels in complex reasoning tasks, with throughput up to 6× higher than Qwen3-8B.
-
Long Context Support: Supports a context length of 128K tokens and can perform inference on a single NVIDIA A10G GPU, suitable for long text and complex tasks.
-
Inference Process Support: Generates reasoning traces before producing the final answer, and users can specify the model’s “thinking” budget.
-
Flexible Output Modes: Users can choose to skip intermediate reasoning steps and directly obtain the final answer.
-
Multilingual Capability: Pre-trained on datasets in multiple languages, providing strong multilingual reasoning ability.
-
Multi-domain Coverage: Includes data across mathematics, coding, academics, STEM, and more, suitable for diverse applications.
Technical Principles of NVIDIA NeMo™ Nano 2
-
Hybrid Mamba-Transformer Architecture: Replaces most self-attention layers in a traditional Transformer with Mamba-2 layers, significantly increasing inference speed, especially for long reasoning chains. Some Transformer layers are retained to preserve flexibility and accuracy.
-
Pre-training: Conducted on 20 trillion tokens using FP8 precision and Warmup-Stable-Decay learning rate scheduling. The model underwent continued pre-training to extend long-context capabilities up to 128K tokens without degrading benchmark performance.
-
Post-training Optimization:
-
Supervised Fine-Tuning (SFT): Improves performance on specific tasks.
-
Policy Optimization: Enhances instruction-following ability.
-
Preference Optimization: Aligns model outputs with human preferences.
-
Reinforcement Learning from Human Feedback (RLHF): Improves dialogue capabilities and instruction compliance.
-
-
Model Compression: Using pruning and knowledge distillation, the 12B-parameter base model is compressed to 9B parameters while maintaining performance. Optimized for 128K token inference on a single NVIDIA A10G GPU, reducing inference costs.
-
Inference Budget Control: Enables the model to perform reasoning based on user-specified “thinking” budgets, avoiding unnecessary computation. Users can choose whether to show the reasoning process or directly get the final answer.
Project Links for NVIDIA NeMo™ Nano 2
-
Official Website: https://research.nvidia.com/labs/adlr/NVIDIA-Nemotron-Nano-2/
-
Hugging Face Model Hub: https://huggingface.co/collections/nvidia/nvidia-nemotron-689f6d6e6ead8e77dd641615
-
Technical Paper: https://research.nvidia.com/labs/adlr/files/NVIDIA-Nemotron-Nano-2-Technical-Report.pdf
-
Online Demo: https://build.nvidia.com/nvidia/nvidia-nemotron-nano-9b-v2
Application Scenarios for NVIDIA NeMo™ Nano 2
-
Education: Assists students in solving complex math and science problems by explaining formulas or physical laws step by step for better understanding.
-
Academic Research: Helps researchers generate detailed reasoning traces and analytical reports, supporting paper writing and experiment design.
-
Software Development: Assists developers in generating high-quality code snippets, speeding up coding and optimization.
-
Programming Education: Provides code examples and explanations to help beginners understand programming languages and algorithms.
-
Customer Service: Acts as a multilingual chatbot, delivering efficient and accurate customer support.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts



No comments yet...