What is MobileCLIP2?
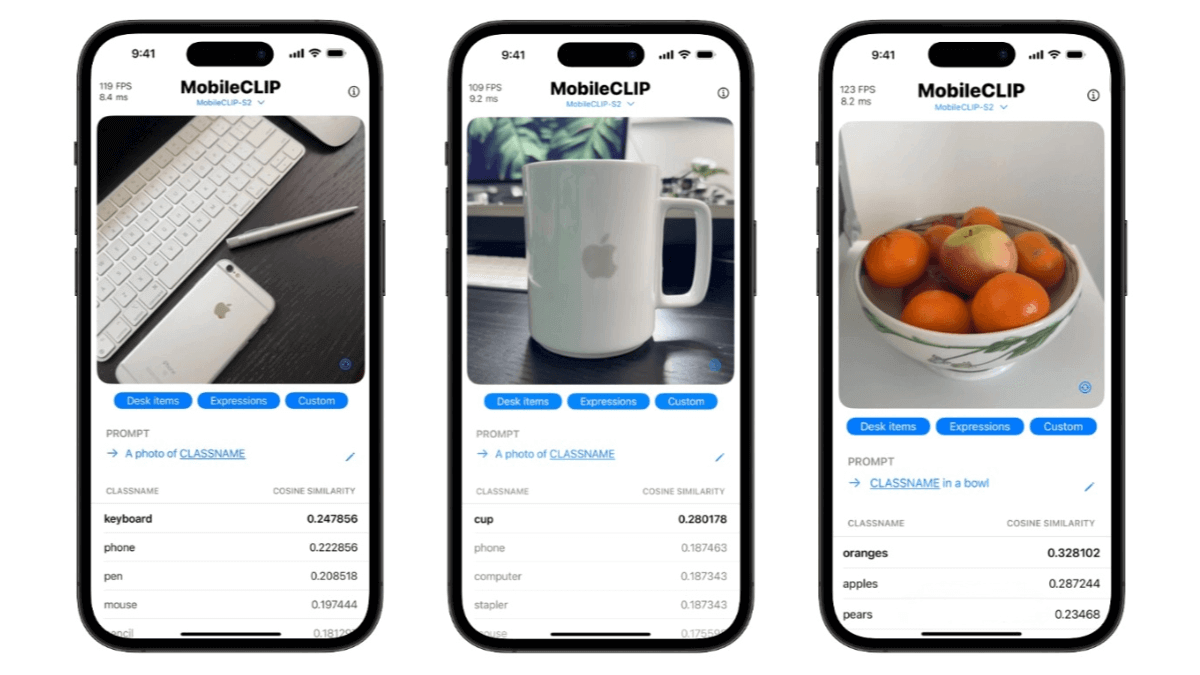
MobileCLIP2 is an efficient on-device multimodal model developed by Apple researchers, serving as an upgraded version of MobileCLIP. It has been optimized for multimodal reinforced training by integrating a higher-performance CLIP teacher model trained on the DFN dataset and an improved image-text generator teacher model, further enhancing model performance. MobileCLIP2 demonstrates strong performance in zero-shot classification tasks; for instance, on the ImageNet-1k zero-shot classification task, its accuracy improves by 2.2% compared to MobileCLIP-B. MobileCLIP2-S4 achieves comparable performance to SigLIP-SO400M/14 while maintaining a smaller model size and lower inference latency. The model also performs well on various downstream tasks, including visual-language model evaluation and dense prediction tasks. MobileCLIP2 is suitable for multiple applications such as image retrieval, content moderation, and smart photo albums, enabling tasks like retrieving images based on text descriptions, checking image-text consistency, and automatic image classification.
Key Features of MobileCLIP2
-
Zero-shot image classification: Leverages pre-trained multimodal features to classify images directly without additional training data, enabling rapid adaptation to new tasks.
-
Text-to-image retrieval: Retrieves the most relevant images from a library based on text input, enabling precise image search.
-
Image-to-text generation: Generates descriptive text from input images, providing suitable titles or captions to aid content understanding and creation.
-
Image-text consistency assessment: Evaluates the alignment between images and text descriptions, useful for content moderation, smart album categorization, and ensuring image-text coherence.
-
Multimodal feature extraction: Extracts high-quality multimodal features for images and text, supporting downstream tasks like image classification, object detection, and semantic segmentation to improve model performance.
Technical Principles of MobileCLIP2
-
Multimodal reinforced training: Enhances joint understanding of images and text by optimizing the CLIP teacher model ensemble and image-text generator teacher model.
-
Contrastive knowledge distillation: Uses contrastive knowledge distillation to transfer key information from large teacher models to smaller student models, balancing performance and efficiency.
-
Temperature adjustment optimization: Introduces a temperature adjustment mechanism during contrastive knowledge distillation to optimize training and improve adaptability to different modalities.
-
Synthetic text generation: Employs an improved image-text generator to create high-quality synthetic text, enriching training data and enhancing the model’s understanding and generation of textual diversity.
-
Efficient model architecture: Designs lightweight architectures, such as MobileCLIP2-B and MobileCLIP2-S4, which maintain high performance while significantly reducing computational complexity and inference latency, suitable for on-device deployment.
-
Fine-tuning and optimization: Fine-tuned on diverse, high-quality image-text datasets to improve task-specific performance and increase practical usability and adaptability.
Project Links for MobileCLIP2
-
GitHub repository: https://github.com/apple/ml-mobileclip
-
Hugging Face model hub: https://huggingface.co/collections/apple/mobileclip2-68ac947dcb035c54bcd20c47
Applications of MobileCLIP2
-
Mobile applications: Enhances AR apps, personal assistants, and real-time photo classification, enabling local data processing without cloud dependency.
-
Edge computing: Suitable for environments with limited bandwidth and processing power, such as drones, robots, and remote sensors, supporting real-time visual recognition tasks and decision-making.
-
IoT devices: Can be integrated into IoT devices like security cameras or smart home assistants, enabling local visual recognition with privacy protection, low latency, and operation in unstable internet conditions.
-
Image classification: Provides a lightweight zero-shot image classification solution; even if the model has never seen a category, it can classify images using only textual labels.
-
Feature extraction: Acts as a feature extractor for images and text, providing high-quality multimodal features for downstream tasks such as diffusion models (e.g., Stable Diffusion) and multimodal large language models (e.g., LLaVA).
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts



No comments yet...