
dots.ocr – A Multilingual Document Parsing Model Open-Sourced by Xiaohongshu Hi Lab
What is dots.ocr?
dots.ocr is a multilingual document layout parsing model open-sourced by Xiaohongshu Hi Lab. The model is based on a 1.7 billion parameter vision-language model (VLM) that unifies layout detection and content recognition while maintaining a good reading order. Although the model is relatively small in scale, it achieves industry-leading performance (SOTA), performing excellently on benchmarks such as OmniDocBench. Its formula recognition rivals larger models like Doubao-1.5 and gemini2.5-pro, with notable advantages in parsing low-resource languages. dots.ocr offers a simple and efficient architecture; task switching only requires changing input prompts. Its fast inference speed makes it suitable for various document parsing scenarios.
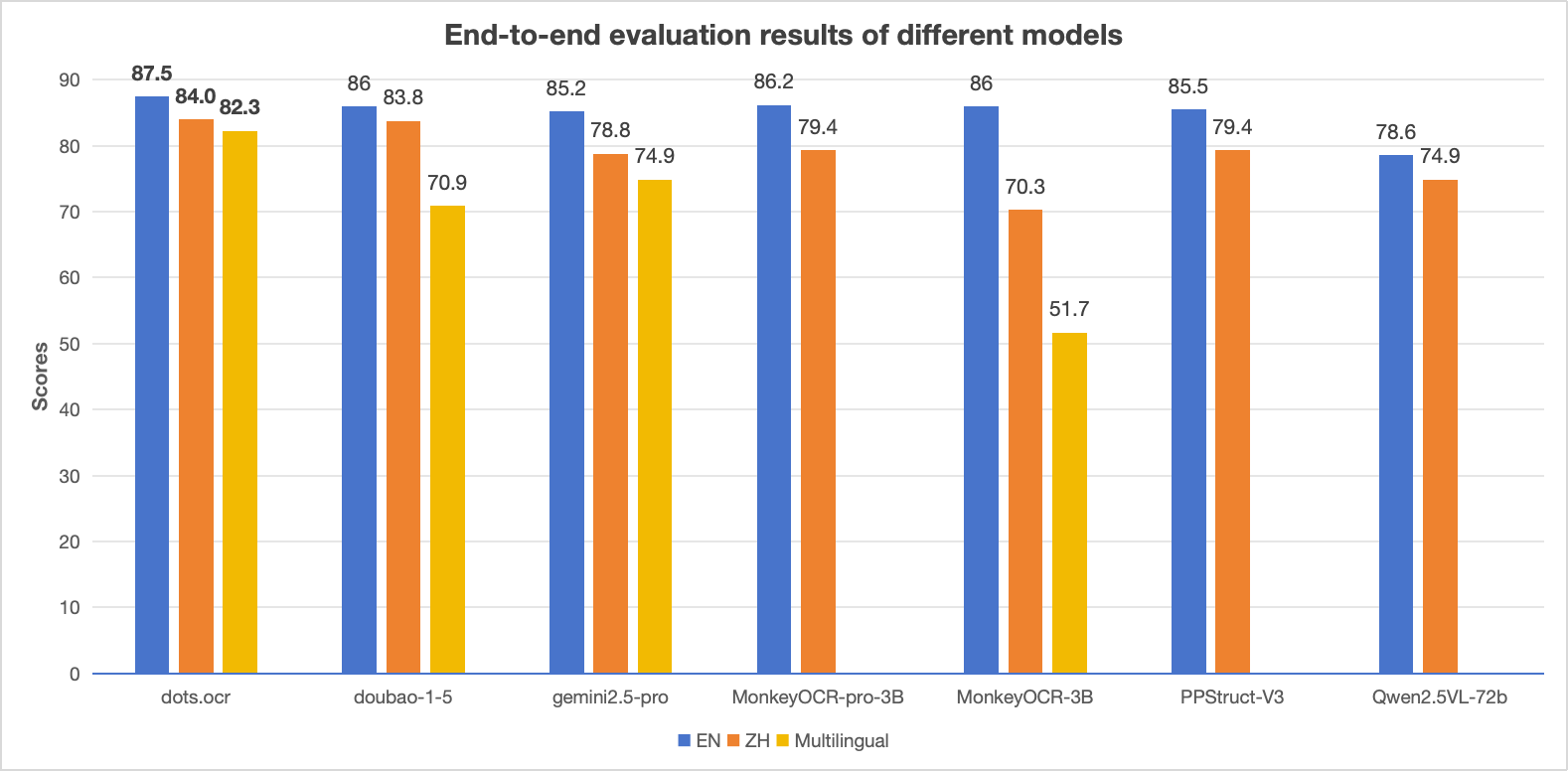
Main Features of dots.ocr
-
Multilingual Document Parsing: Supports document parsing in multiple languages, covering elements such as text, tables, formulas, and images.
-
Layout Detection and Content Recognition: Unifies layout detection and content recognition within a single vision-language model, maintaining a proper reading order.
-
Efficient Inference: Built on a 1.7 billion parameter vision-language model, offering fast inference suitable for large-scale document processing.
-
Flexible Task Switching: Easily switch between tasks such as layout detection and content recognition by changing input prompts.
-
Diverse Output Formats: Supports various output formats including JSON and Markdown, and provides layout visualization images.
Technical Principles of dots.ocr
-
Vision-Language Model (VLM): dots.ocr is built on a 1.7 billion parameter VLM that combines the strengths of a visual encoder and a language model. The visual encoder extracts visual features from document images, while the language model understands and generates text content.
-
Three-Stage Training Process:
-
Visual Encoder Pretraining: Trains a 1.2 billion parameter visual encoder from scratch using a large-scale image-text paired dataset.
-
Visual Encoder Continued Pretraining: Adds support for high-resolution inputs and aligns with the language model to further enhance visual feature extraction.
-
VLM Training: Trains on pure OCR datasets to optimize performance on document parsing tasks.
-
-
Supervised Fine-Tuning (SFT): Uses diverse datasets including manually annotated data, synthetic data, and open-source datasets. Employs an iterative data flywheel mechanism to continually improve model performance by enhancing data quality and diversity. Uses a “large model ranking + rule-based posterior” method to correct reading order, ensuring the sequence of layout elements aligns with human reading habits.
-
Task Switching Mechanism: Uses input prompts to specify tasks like layout detection, content recognition, or formula parsing. Prompts guide the model to generate the corresponding outputs, allowing flexible responses to various document parsing needs.
Project Links for dots.ocr
-
GitHub Repository: https://github.com/rednote-hilab/dots.ocr
-
HuggingFace Model Hub: https://huggingface.co/rednote-hilab/dots.ocr
-
Online Demo: https://dotsocr.xiaohongshu.com/
Application Scenarios of dots.ocr
-
Document Digitization and Content Extraction: Efficiently converts paper documents or PDFs into editable digital formats, accurately extracting structured content like text, tables, and formulas to support electronic document management.
-
Academic Research and Publishing: Quickly parses formulas, charts, and text in academic papers, assisting researchers in efficiently obtaining key information and accelerating research and knowledge dissemination.
-
Financial and Accounting Document Processing: Automatically extracts data and tables from financial reports, supporting financial data analysis and compliance checks to improve business efficiency.
-
Education: Parses educational materials such as textbooks and exams to extract questions and answers, aiding digitalization and online delivery of teaching content to support education informatization.
-
Enterprise Internal Document Management: Supports processing internal documents like meeting notes and project reports, extracting key information to optimize enterprise operations.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts

No comments yet...