What is SpikingBrain-1.0?
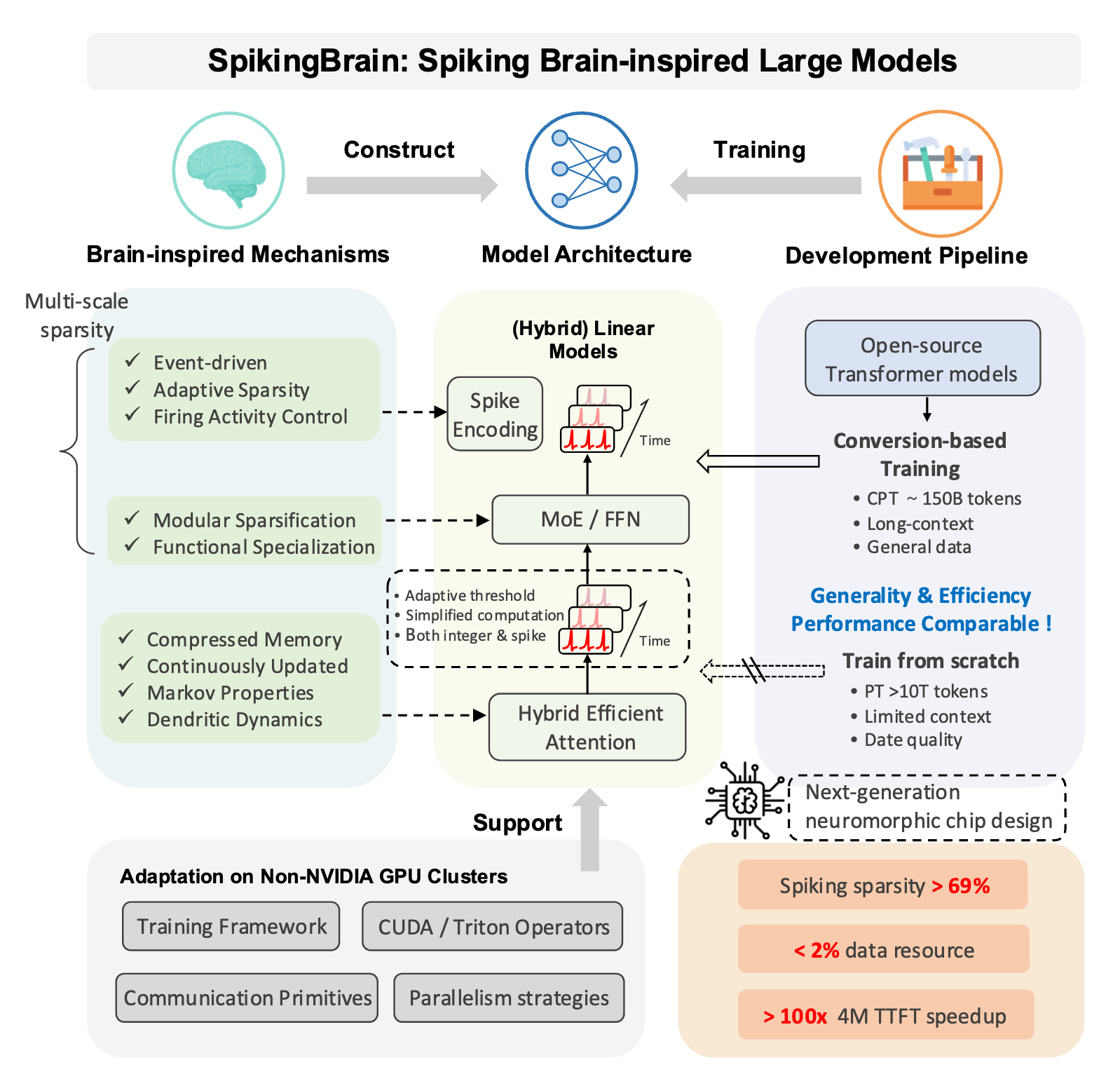
SpikingBrain-1.0 (Shunxi 1.0) is a brain-inspired spiking large model released by the Institute of Automation, Chinese Academy of Sciences. The model is built on intrinsic complexity and uses a novel non-Transformer architecture, overcoming the bottlenecks that Transformer architectures face when handling ultra-long sequences. It completes full-process training and inference on domestic GPU platforms, achieving improved efficiency and speed for large model inference on ultra-long sequences. Key advantages include highly efficient training with very small amounts of data and orders-of-magnitude improvement in inference efficiency, laying the foundation for a domestically controlled brain-inspired large model ecosystem.
Key Features of SpikingBrain-1.0
-
Ultra-long Sequence Processing: Efficiently handles ultra-long sequence data, breaking through the performance limitations of traditional Transformer architectures.
-
Low-Data Training: Can train effectively with very small datasets, significantly reducing training costs and data requirements.
-
Inference Efficiency Improvement: Achieves orders-of-magnitude efficiency gains during inference, suitable for large-scale applications and real-time processing scenarios.
-
Autonomous and Controllable Ecosystem: Supports the development of a domestically controlled brain-inspired large model ecosystem, providing core support for the growth of AI in China.
Technical Principles of SpikingBrain-1.0
-
Brain-Inspired Spiking Neural Networks: Designed based on spiking neural networks (SNNs), simulating the spike-based signal transmission of biological neurons, closer to the working mechanism of the human brain.
-
Non-Transformer Architecture: Employs a novel non-Transformer architecture to address computational complexity and memory usage issues in ultra-long sequence processing.
-
Intrinsic Complexity: Utilizes principles of intrinsic complexity, enabling efficient learning and inference through dynamic interactions and adaptive adjustments between neurons.
-
Domestic GPU Computing Power: Full-process training and inference are conducted on domestic GPU platforms, ensuring both autonomy and high-efficiency operation.
Project Links
-
GitHub Repository: https://github.com/BICLab/SpikingBrain-7B
-
arXiv Paper: https://arxiv.org/pdf/2509.05276
Application Scenarios of SpikingBrain-1.0
-
Natural Language Processing: In intelligent customer service, quickly understands and processes long user queries, significantly improving user experience.
-
Speech Processing: Accurately recognizes long spoken commands or dialogue content, widely applied in smart voice assistants and voice conferencing systems.
-
Fintech: In risk assessment, analyzes long-term financial data to provide strong support for investment decisions.
-
Intelligent Transportation: Predicts traffic flow by analyzing long-term traffic data, enabling accurate traffic forecasting.
-
Healthcare: Assists in disease diagnosis by analyzing long-term medical data, helping doctors make diagnostic decisions and treatment plans.