What is SRPO?
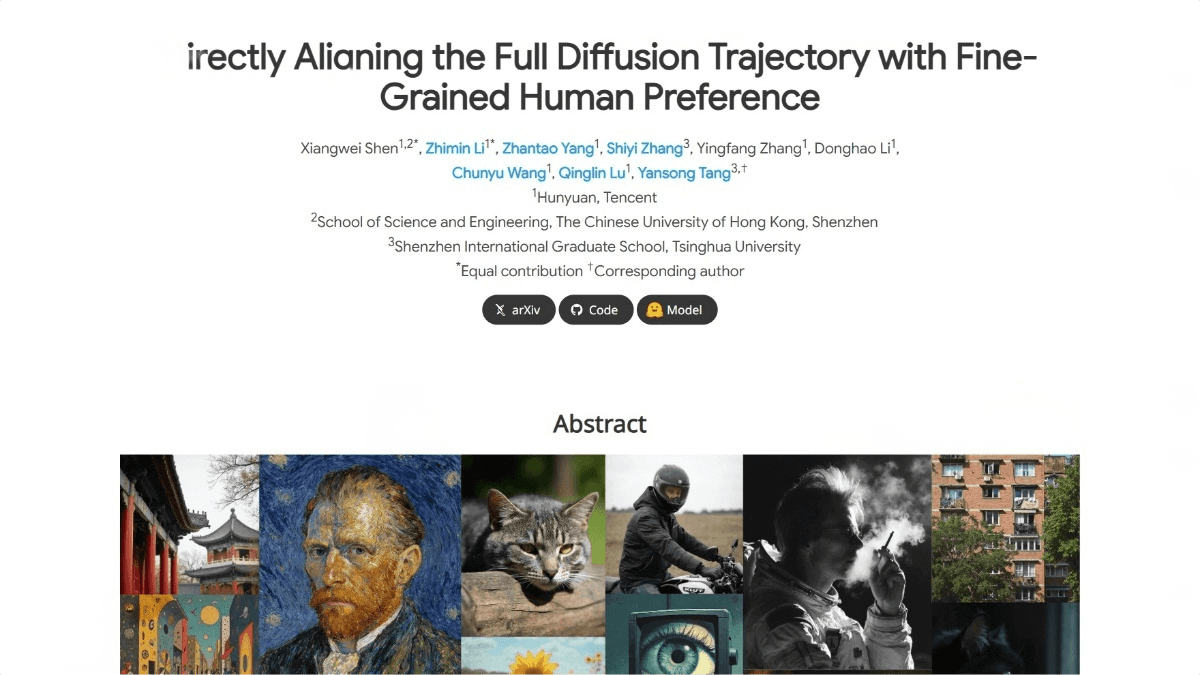
SRPO (Semantic Relative Preference Optimization) is a text-to-image generation model launched by Tencent Hunyuan. By designing reward signals as text-conditional signals, it enables online adjustment of rewards, reducing reliance on offline reward fine-tuning. SRPO introduces Direct-Align technology, which restores the original image from any timestep directly using a predefined noise prior, avoiding over-optimization issues in later timesteps. Experiments on the FLUX.1.dev model demonstrate that SRPO significantly improves the human-evaluated realism and aesthetic quality of generated images while maintaining extremely high training efficiency—requiring only 10 minutes for optimization.
Main Functions of SRPO
-
Enhancing image generation quality: Optimizes diffusion models to produce images with significantly improved realism, richer details, and higher aesthetic quality.
-
Online reward adjustment: Allows users to dynamically adjust reward signals through text prompts, instantly changing the style and preferences of image generation without offline fine-tuning of the reward model.
-
Improving model adaptability: Enables diffusion models to better adapt to various task requirements and human preferences, such as optimizing for different lighting conditions, artistic styles, or levels of detail.
-
Boosting training efficiency: By optimizing during the early stages of the diffusion process, SRPO can complete training and optimization in as little as 10 minutes, greatly improving efficiency.
Technical Principles of SRPO
-
Direct-Align Technology: During training, SRPO injects Gaussian noise into clean images and recovers the original image through a single-step denoising operation. This avoids over-optimization in later timesteps of the diffusion process and reduces “reward hacking” behaviors (e.g., the model exploiting reward model biases to generate low-quality images). Compared with traditional methods, early-stage optimization improves both efficiency and generation quality.
-
Semantic Relative Preference Optimization (SRPO): Designs reward signals as text-conditional signals, adjusting them using pairs of positive and negative prompts. By optimizing based on reward differences between positive and negative prompt pairs, SRPO supports dynamic reward adjustment during training, enabling real-time adaptation to different tasks.
-
Reward Aggregation Framework: To enhance stability, SRPO injects noise multiple times during training to generate intermediate images, each denoised and recovered. Using a decayed discount factor, these intermediate rewards are aggregated, reducing reward hacking in later timesteps and improving overall image quality.
Project Resources
-
Project website: https://tencent.github.io/srpo-project-page/
-
GitHub repository: https://github.com/Tencent-Hunyuan/SRPO
-
HuggingFace model hub: https://huggingface.co/tencent/SRPO
-
arXiv technical paper: https://arxiv.org/pdf/2509.06942v2
Application Scenarios
-
Digital art creation: Artists and designers can generate high-quality artworks, dynamically adjusting style via text prompts, enabling rapid iteration from concept sketches to final pieces.
-
Advertising and marketing: Agencies can generate brand-aligned visuals and market-specific images, quickly producing diverse design options to boost creative efficiency.
-
Game development: Developers can create high-quality game textures, character designs, and scene backgrounds, enhancing visual effects and player immersion.
-
Film and television production: Used to generate realistic visual effects, backgrounds, and characters, reducing time and costs in post-production.
-
Virtual Reality (VR) and Augmented Reality (AR): Produces high-quality virtual environments and objects, enhancing immersion and realism in VR/AR applications.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...