Qwen3-TTS-Flash – the text-to-speech model released by Alibaba Tongyi
What is Qwen3-TTS-Flash?
Qwen3-TTS-Flash is a flagship speech synthesis model launched by Alibaba Tongyi, supporting multiple voices, languages, and dialects. The model delivers outstanding stability in Chinese and English speech, excellent multilingual performance, and highly expressive human-like voices. It offers 17 voice options, each supporting 10 languages, and supports multiple dialects such as Mandarin, Minnan, and Cantonese. The model can automatically adjust tone based on input text, shows strong robustness for complex text, and generates speech with fast speed and ultra-low first-packet latency (as low as 97ms). Qwen3-TTS-Flash is now accessible via the Qwen API, providing users with natural and expressive speech synthesis services.

Main Features of Qwen3-TTS-Flash
-
Multi-voice support: Offers 17 different voice options, each supporting multiple languages, to meet diverse user needs.
-
Multilingual and multi-dialect support: Supports a wide range of languages, including Mandarin, English, French, German, Russian, Italian, Spanish, Portuguese, Japanese, and Korean, as well as dialects such as Minnan, Wu, Cantonese, Sichuanese, Beijing, Nanjing, Tianjin, and Shaanxi.
-
High expressiveness: Produces natural, expressive speech that automatically adjusts intonation based on input text, making voices more vivid.
-
High robustness: Automatically processes complex text, extracts key information, and adapts well to diverse text formats.
-
Fast generation: Provides extremely low first-packet latency (down to 97ms), generating speech quickly and enhancing user experience.
-
High voice similarity: Delivers excellent performance in multilingual speech stability and timbre similarity, surpassing other models in the field.
Technical Principles of Qwen3-TTS-Flash
-
Deep learning model:
-
Text encoder: Converts input text into semantic representations, extracting key information and features.
-
Speech decoder: Generates speech waveforms based on the text encoder’s output, ensuring naturalness and expressiveness.
-
Attention mechanism: Aligns text and speech more effectively, improving accuracy and fluency in generated speech.
-
-
Multilingual and multi-dialect training: Trained on diverse datasets covering different languages and dialects to learn pronunciation and intonation rules. With voice embedding technology, the model generates speech in various timbres to meet diverse user needs.
-
High robustness: Preprocesses input text (segmentation, POS tagging, semantic parsing) to ensure correct comprehension. The model can automatically handle complex or erroneous text, extract key information, and generate accurate speech.
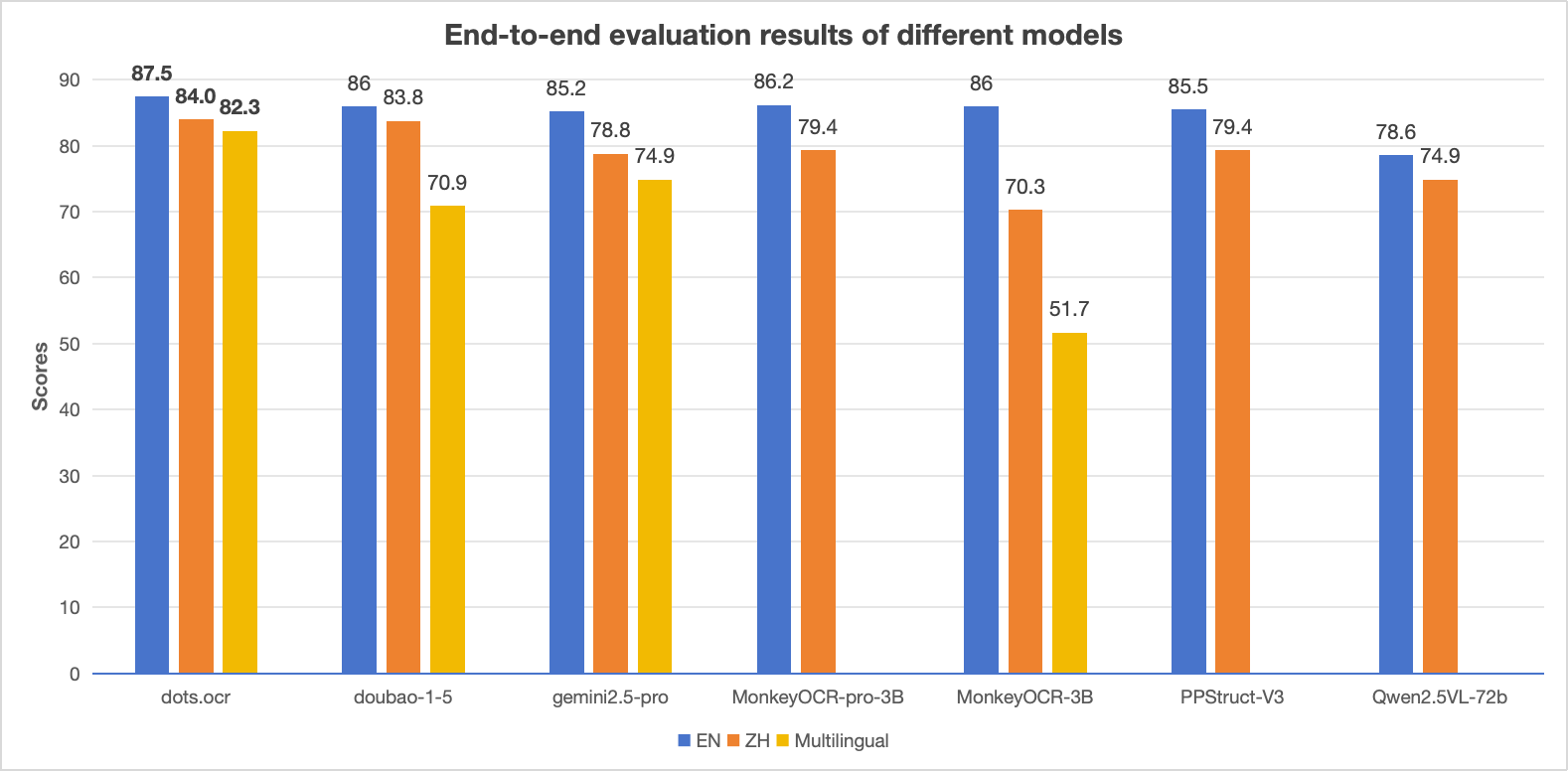
Performance of Qwen3-TTS-Flash
-
Chinese and English stability: On the seed-tts-eval test set, Qwen3-TTS-Flash achieved state-of-the-art (SOTA) performance in Chinese and English speech stability, outperforming SeedTTS, MiniMax, and GPT-4o-Audio-Preview.
-
Multilingual stability: On the MiniMax TTS multilingual test set, Qwen3-TTS-Flash reached SOTA in WER (Word Error Rate) for Chinese, English, Italian, and French, significantly surpassing MiniMax, ElevenLabs, and GPT-4o-Audio-Preview.
-
Voice similarity: In speaker similarity tests for English, Italian, and French, Qwen3-TTS-Flash outperformed MiniMax, ElevenLabs, and GPT-4o-Audio-Preview, showcasing superior timbre expressiveness.
Project Links for Qwen3-TTS-Flash
-
Official Website: https://qwen.ai/blog?id=b4264e11fb80b5e37350790121baf0a0f10daf82&from=research.latest-advancements-list
-
Online Demo: https://huggingface.co/spaces/Qwen/Qwen3-TTS-Demo
Application Scenarios of Qwen3-TTS-Flash
-
Intelligent customer service: Provides natural, smooth voice interaction to improve service experience, such as answering FAQs and guiding users through processes.
-
Audiobooks: Converts written content into vivid speech, enabling listeners to enjoy novels, news, textbooks, and more in audio form.
-
Voice assistants: Enables voice interaction in smart home devices, wearables, and more, making device control and information access easier.
-
Education: Supports teaching by offering multilingual, multi-voice explanations to help students learn languages and knowledge more effectively.
-
Entertainment industry: Used in animation, gaming, and film production for character dubbing, creating more immersive and engaging audio experiences.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...