
Logics-Parsing – An End-to-End Document Parsing Model Open-Sourced by Alibaba
What is Logics-Parsing?
Logics-Parsing is an end-to-end document parsing model open-sourced by Alibaba, built on Qwen2.5-VL-7B. It leverages reinforcement learning to optimize document layout analysis and reading order inference, enabling the conversion of PDF images into structured HTML output. The model supports multiple content types, including plain text, mathematical formulas, tables, chemical formulas, and handwritten Chinese characters.
It adopts a two-stage training strategy:
-
Supervised fine-tuning – to learn structured output generation.
-
Layout-centered reinforcement learning – to enhance text accuracy, layout positioning, and reading order.
On the LogicsParsingBench benchmark, Logics-Parsing demonstrates outstanding performance, particularly in parsing plain text, chemical structures, and handwritten content, outperforming other approaches.
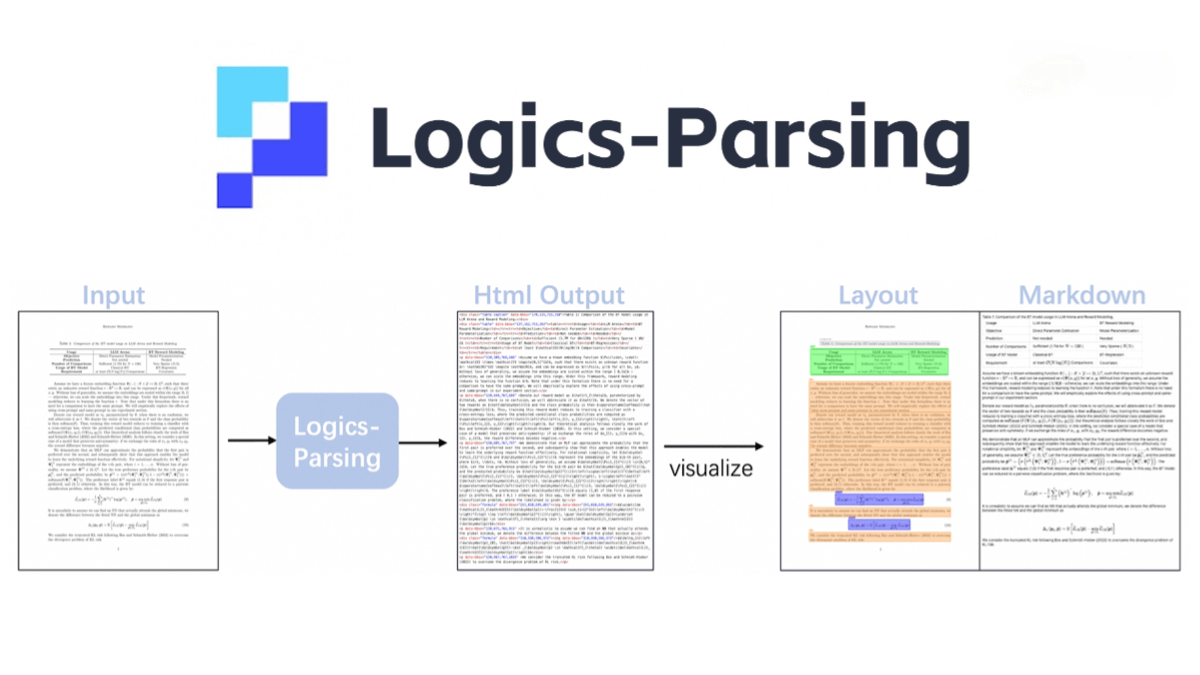
Key Features of Logics-Parsing
-
End-to-end document parsing: Converts PDF images directly into structured HTML output, supporting diverse content types such as plain text, mathematical formulas, tables, chemical formulas, and handwritten Chinese characters.
-
Reinforcement learning optimization: Employs a two-stage training method—supervised fine-tuning followed by layout-centered reinforcement learning to improve text accuracy, layout recognition, and reading order.
-
High performance: Achieves state-of-the-art results on LogicsParsingBench, especially for plain text, chemical structures, and handwritten content.
-
Wide applicability: Suitable for parsing academic papers, multi-column complex documents, newspapers, posters, and other structured document formats.
Technical Principles of Logics-Parsing
-
Based on Qwen2.5-VL-7B: Built upon the powerful Qwen2.5-VL-7B model, inheriting its strong vision-language understanding capabilities.
-
Two-stage training:
-
Stage 1: Supervised fine-tuning to train the model to generate structured HTML outputs.
-
Stage 2: Layout-centered reinforcement learning, optimized with three reward components—text accuracy, layout localization, and reading order.
-
-
Reinforcement learning optimization: Helps the model better understand document layout and logical reading sequences, producing more accurate structured outputs.
-
Structured HTML output: Converts document images into structured HTML, preserving logical document structure with content blocks labeled with categories, bounding box coordinates, and OCR text.
-
Advanced content recognition: Accurately recognizes complex scientific formulas, chemical structures, and handwritten Chinese characters, converting chemical structures into standard SMILES format.
-
Automatic noise removal: Filters out irrelevant elements such as headers and footers, focusing on the core document content.
Project Links
-
GitHub Repository: https://github.com/alibaba/Logics-Parsing
-
HuggingFace Model Hub: https://huggingface.co/Logics-MLLM/Logics-Parsing
-
arXiv Paper: https://arxiv.org/pdf/2509.19760
Application Scenarios of Logics-Parsing
-
Academic paper parsing: Handles multi-column layouts, mathematical formulas, and chemical structures in research papers, extracting key information into structured formats.
-
Complex multi-column documents: Suitable for parsing newspapers, posters, and other documents with intricate layouts.
-
Handwritten document recognition: Supports parsing handwritten Chinese characters, useful for notes, exams, and other handwriting scenarios.
-
Chemical document processing: Recognizes chemical formulas and converts them into SMILES format, enabling structured analysis in chemistry research.
-
Mathematical document parsing: Accurately processes documents containing complex formulas, such as textbooks and research articles.
-
Multilingual document support: Supports parsing documents in multiple languages, making it applicable to international document processing needs.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...