Jamba Reasoning 3B – AI21’s Open-Source Lightweight Reasoning Model
What is Jamba Reasoning 3B?
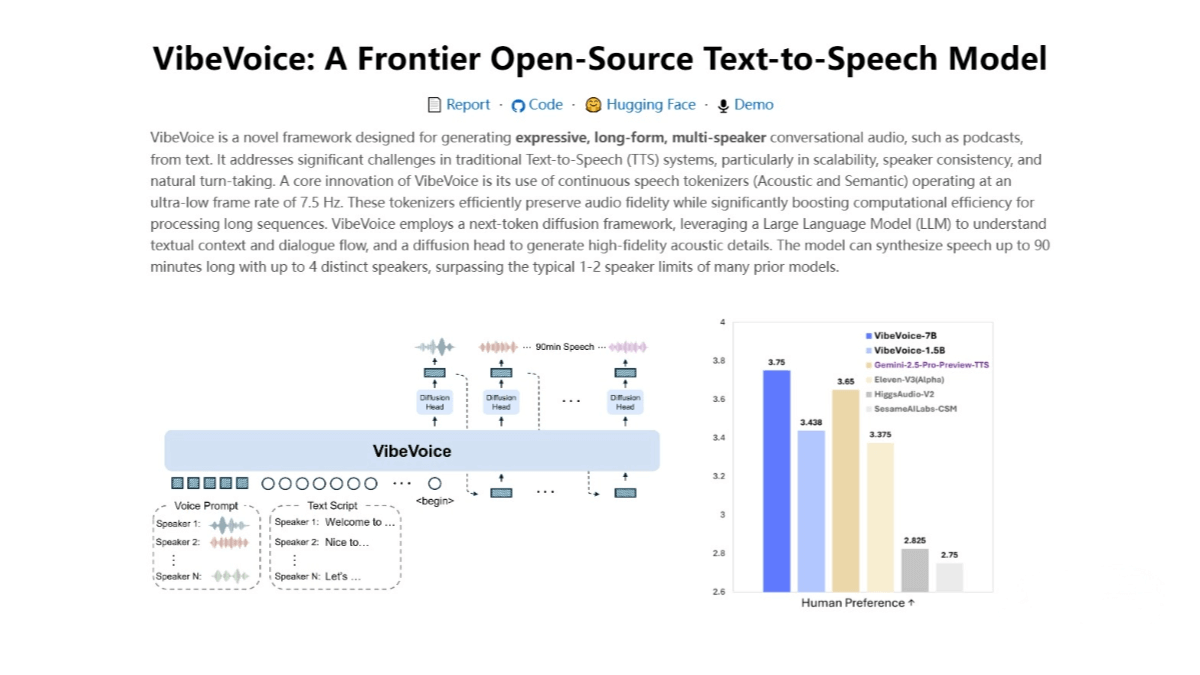
Jamba Reasoning 3B is a lightweight and efficient reasoning model developed by AI21 Labs, featuring 3 billion parameters and an ultra-long 256K context window. Built on a hybrid Transformer–Mamba architecture, it combines the strengths of attention mechanisms and state-space models (SSMs) to deliver high reasoning efficiency and low latency. The model performs exceptionally well across multiple intelligence benchmarks, particularly in instruction following and commonsense reasoning tasks. Supporting multiple languages, it can be deployed locally on devices such as smartphones or computers, making it suitable for both enterprise applications and individual developers. The model is open-source and free to use, offering broad potential for real-world applications.

Key Features of Jamba Reasoning 3B
1. Efficient Reasoning
Capable of rapidly processing complex tasks, making it ideal for real-time reasoning applications.
2. Long-Context Processing
Supports up to 256,000 tokens, enabling the handling of long documents, technical manuals, and complex reasoning tasks.
3. Multilingual Support
Covers multiple languages including English, Spanish, French, Portuguese, Italian, Dutch, German, Arabic, and Hebrew.
4. Local Deployment
Can be run on local devices (e.g., mobile phones, laptops), ensuring data privacy and offline usability.
Technical Principles of Jamba Reasoning 3B
Hybrid Architecture
Combines the Transformer’s attention mechanism with the Mamba State-Space Model (SSM).
-
The Mamba layers handle long-sequence processing efficiently.
-
The attention layers capture complex dependencies and contextual relationships.
Memory Efficiency
Optimized KV caching and hybrid design dramatically reduce memory consumption while maintaining high performance in long-context scenarios.
Multi-Stage Training Process:
-
Pretraining: Conducted on large-scale natural language corpora.
-
Intermediate Training: Extended on mathematical and code datasets, expanding the context window to 32K tokens.
-
Cold-Start Distillation: Uses supervised fine-tuning and direct preference optimization (DPO) to enhance reasoning performance.
-
Reinforcement Learning: Incorporates RLVR (Reinforcement Learning with Verification Regression) to further refine reasoning accuracy and efficiency.
Long-Context Handling
Through the unique Mamba layer design, the model can process contexts up to 256K tokens, with scalability tested up to 1 million tokens.
Low-Latency Optimization
On lightweight devices (e.g., M3 MacBook Pro), the model achieves up to 40 tokens per second generation speed at a 32K context length.
Project Resources
-
Official Website: https://www.ai21.com/blog/introducing-jamba-reasoning-3B/
-
Hugging Face Model Page: https://huggingface.co/ai21labs/AI21-Jamba-Reasoning-3B
Application Scenarios
1. Legal Document Analysis
Quickly extracts key clauses and insights from contracts, assisting lawyers in preliminary reviews and improving workflow efficiency.
2. Medical Report Interpretation
Identifies critical information from medical records and examination reports, supporting physicians in decision-making and improving healthcare quality.
3. Technical Manual Assistance
Provides real-time technical manual lookup for field engineers, enabling fast access to maintenance or operational instructions.
4. Writing Assistant
Helps users generate articles, emails, and reports efficiently, offering writing suggestions and style refinement to boost productivity.
5. Personal Assistant
Delivers lifestyle recommendations such as travel planning or recipe suggestions, enhancing daily convenience and user experience.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...