Claude Haiku 4.5 – a new lightweight AI model launched by Anthropic
What is Claude Haiku 4.5?
Claude Haiku 4.5 is Anthropic’s latest high-performance, cost-efficient small AI model. It delivers coding performance comparable to the previous flagship model Claude Sonnet 4, and even surpasses it in some tasks—while costing only one-third as much and running over twice as fast. The model offers excellent alignment and safety, rated at AI Safety Level 2 (ASL-2). Claude Haiku 4.5 can be deployed via the Claude API, Amazon Bedrock, and Google Cloud Vertex AI, making it ideal for real-time, low-latency use cases such as chat assistants, customer service agents, and programming companions.

Main Features of Claude Haiku 4.5
-
Coding Capabilities: Performs exceptionally well in programming tasks, supporting multiple languages and generating high-quality code. Ideal for rapid prototyping and multi-agent collaboration projects.
-
Real-Time Interaction: Optimized for low-latency tasks such as chatbots, customer support agents, and pair programming, ensuring fast and smooth user experiences.
-
Multi-Task Processing: Works alongside the flagship Claude Sonnet 4.5 to decompose complex problems into smaller sub-tasks for parallel execution, greatly improving efficiency.
-
High Security: Extensively tested for safety and alignment, with a very low incidence of harmful behavior—one of Anthropic’s safest models to date.
-
Cost Efficiency: Priced at only one-third of Claude Sonnet 4—$1 per million input tokens and $5 per million output tokens, offering exceptional value.
Performance Overview
Coding Ability:
-
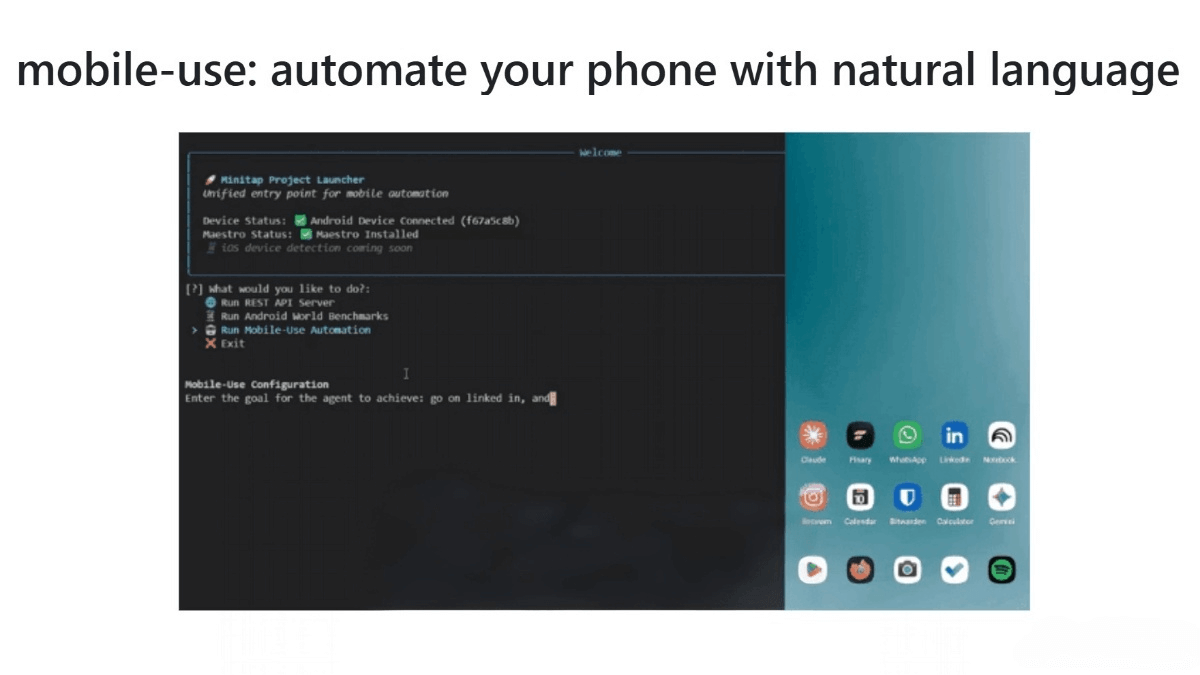
SWE-bench Verified: Achieved 73.3% accuracy, comparable to Claude Sonnet 4 (72.7%), approaching top industry levels.
-
Terminal-Bench: Scored 41.0%, outperforming Claude Sonnet 4 (36.4%).
-
OSWorld: Scored 50.7%, significantly higher than Claude Sonnet 4 (42.2%), showing strong performance in computer-use tasks.
Mathematical Ability:
-
With Python Tool Support: Achieved 96.3% accuracy, demonstrating excellent performance.
-
Without Tools: Scored 80.7% accuracy, slightly lower but still exceeding many large-scale models.
Multilingual Ability:
-
MMMLU Benchmark: Achieved an average accuracy of 73.3% across 14 non-English languages, indicating strong multilingual understanding.
Official Project Page
Application Scenarios
-
Programming Assistant: Provides developers with code generation, debugging suggestions, and rapid prototyping support—ideal for collaborative, multi-agent projects.
-
Chat Assistant: Builds real-time, responsive chatbots that handle user queries smoothly and efficiently.
-
Customer Support Agent: Assists customer service teams in quickly answering inquiries and delivering accurate, consistent information.
-
Pair Programming: Supports programmers with real-time feedback, logic optimization, and coding suggestions to improve code quality.
-
Educational Tutoring: Helps students learn programming by explaining complex concepts, generating exercises, and providing detailed answers.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts

No comments yet...