What is SAIL-Embedding?
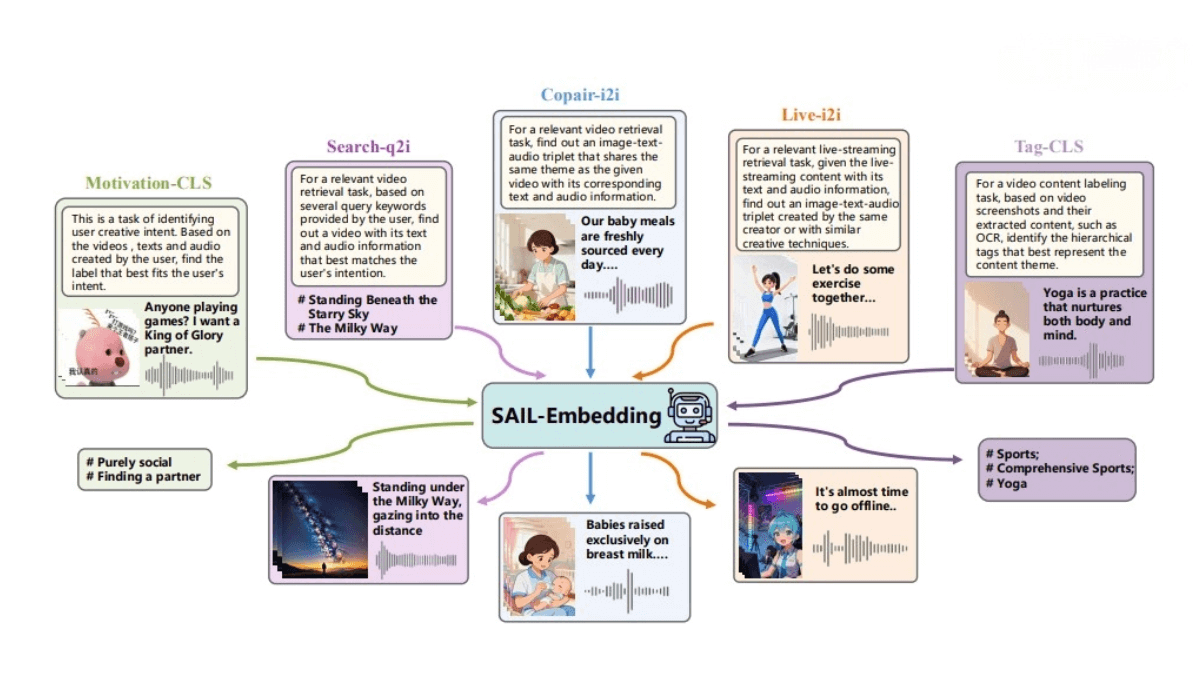
SAIL-Embedding is an omni-modal embedding foundation model jointly developed by ByteDance’s Douyin SAIL team and The Chinese University of Hong Kong’s MMLab. It addresses real-world challenges in multimodal information retrieval and recommendation systems by supporting arbitrary input modalities—including text, vision, and audio—and generating unified, information-rich representations for multimodal retrieval and classification tasks.
Through techniques such as dynamic hard negative mining and adaptive multi-source data balancing, SAIL-Embedding enhances training robustness and scalability. It leverages large language models (LLMs) as the backbone for reasoning and multimodal fusion, allowing flexible integration of modalities. Across multiple benchmarks, SAIL-Embedding significantly outperforms other methods, especially in search and collaborative perception scenarios.
Main Features of SAIL-Embedding
Omni-modal Support:
Processes multiple input modalities—vision, text, and audio—to generate unified multidimensional embedding vectors, meeting the needs of diverse business applications.
Dynamic Hard Negative Mining:
Automatically determines optimal similarity thresholds to identify challenging negative samples, improving the model’s discriminative power and robustness against complex data.
Adaptive Multi-source Data Balancing:
Dynamically adjusts sampling weights among datasets based on data distribution, balancing quality and diversity while reducing dependency on manual parameter tuning.
Content-aware Progressive Training:
Gradually enhances the embedding space’s ability to distinguish between task-specific requirements, improving generalization to unseen scenarios and equipping the model with broader domain knowledge.
Collaboration-aware Recommendation Enhancement:
Integrates user historical behavior patterns into multimodal representations via multi-interest-driven sequence-to-item distillation, aggregating user preference signals to improve recommendation accuracy.
Random Specialization Training:
Randomly selects datasets for training to boost domain adaptability, increase training efficiency, and enhance generalization.
Data-driven Matching Mechanism:
Dynamically constructs query-target pairs based on data characteristics, enabling flexible contrastive learning across modalities and improving optimization stability.
Technical Principles of SAIL-Embedding
Dynamic Hard Negative Mining:
Focuses on identifying challenging negative examples, strengthening domain-specific understanding, and reducing misclassification caused by ambiguous samples.
Adaptive Multi-source Data Balancing:
Learns optimal sampling weights directly from data distribution, balancing dataset quality and diversity without manual parameter tuning.
Content-aware Progressive Training:
Gradually improves the embedding space’s discriminative capability and generalization to diverse and unseen tasks, enhancing the model’s domain comprehension.
Collaboration-aware Recommendation Enhancement:
Incorporates user behavioral patterns into multimodal embeddings via sequence-to-item distillation, effectively merging multi-dimensional user interest signals for more accurate content recommendations.
Project Links
-
Hugging Face Model Collection: https://huggingface.co/collections/BytedanceDouyinContent/sail-embedding
-
arXiv Technical Paper: https://arxiv.org/pdf/2510.12709
Application Scenarios of SAIL-Embedding
Multimodal Information Retrieval:
Supports cross-modal retrieval tasks such as image-text, video-text, and audio-text search. It enables finding related visual or audio content based on textual queries, improving retrieval accuracy and efficiency.
Recommendation Systems:
Applied in video or livestream recommendation, leveraging users’ historical behaviors and preferences to deliver personalized and relevant content recommendations.
Content Classification and Tag Generation:
Automatically classifies multimedia content and generates tags—for example, assigning thematic labels to videos or classifying images—enhancing efficiency and precision in content organization and management.
Cold-start Recommendation:
Addresses the cold-start problem for new users or new items by rapidly generating feature embeddings from multimodal inputs, enabling effective recommendations even with limited interaction data.
Video Content Understanding:
Provides deep video understanding capabilities, including topic recognition and sentiment analysis, supporting applications such as video editing, recommendation, and content moderation.
Cross-modal Generation:
Enables cross-modal generation tasks such as creating images or videos from text descriptions or generating textual captions from visual content, expanding the boundaries of multimodal applications.