
FG-CLIP 2 – 360 Open-Source Bilingual Fine-Grained Vision-Language Alignment Model
What is FG-CLIP 2?
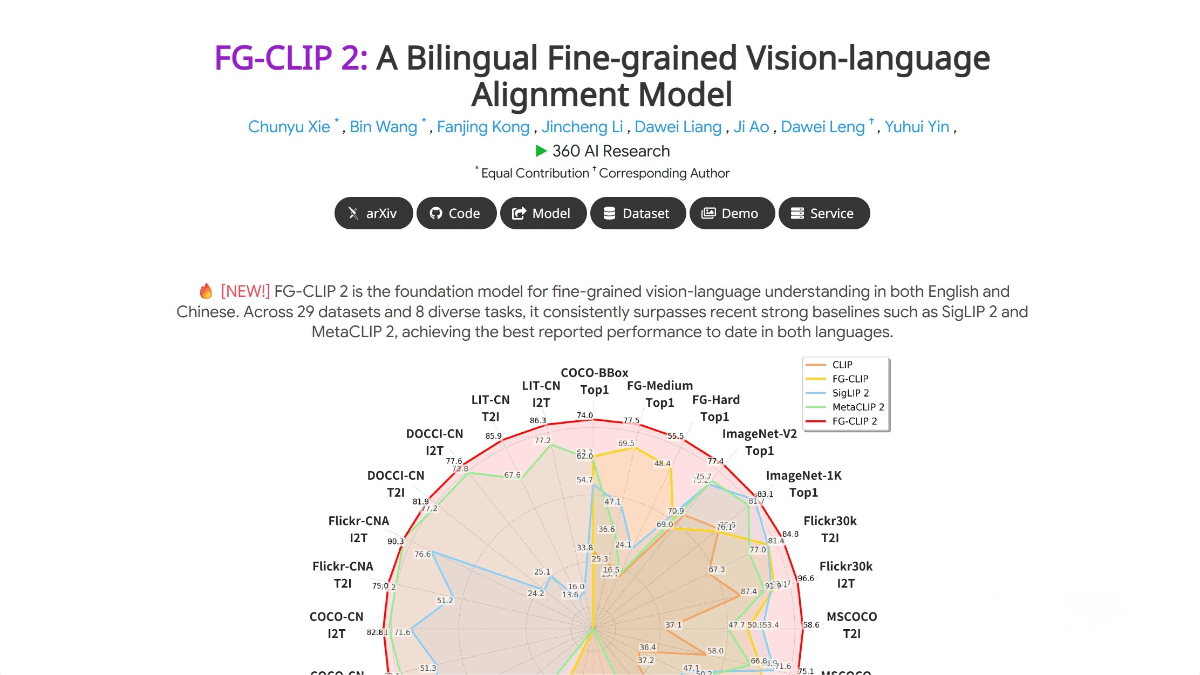
FG-CLIP 2 is an open-source bilingual fine-grained vision-language alignment model developed by 360, designed to solve the problem of precise alignment between visual and linguistic information. It represents a major breakthrough in vision-language understanding, especially excelling in both Chinese and English tasks. The model adopts a hierarchical alignment architecture, which progressively enhances its understanding of image details through global semantic alignment and fine-grained vision-language learning. It also introduces a dynamic attention mechanism that intelligently focuses on key regions within images, enabling better handling of complex vision-language tasks. In multiple authoritative benchmark tests, FG-CLIP 2 has outperformed leading models such as Google’s SigLIP 2 and Meta’s MetaCLIP 2, establishing itself as one of the most powerful vision-language models in the world.
Main Features of FG-CLIP 2
-
Fine-Grained Vision-Language Understanding:
Accurately understands detailed visual information, including object attributes and spatial relationships, addressing the limitations of traditional models in fine-grained recognition. -
Bilingual Support:
Excels in both Chinese and English tasks, achieving true native bilingual support. -
Hierarchical Alignment Architecture:
Captures both macro-level scenes and micro-level details simultaneously, enhancing the model’s ability to interpret image nuances. -
Dynamic Attention Mechanism:
Intelligently focuses on key regions in images for improved performance on complex vision-language tasks. -
Optimized Bilingual Collaboration Strategy:
Solves the imbalance between Chinese and English understanding, improving overall performance across bilingual tasks. -
Powerful Performance:
Outperforms Google’s SigLIP 2 and Meta’s MetaCLIP 2 across 29 authoritative public benchmark datasets, ranking among the top global models. -
High-Concurrency Response Speed:
Utilizes an explicit dual-tower architecture where image and text features can be pre-computed and cached, achieving millisecond-level response in high-concurrency scenarios. -
Adaptive Input Resolution:
A dynamic resolution mechanism enables the model to flexibly process inputs of varying sizes, improving adaptability and robustness. -
Rich Open-Source Resources:
Offers code, model weights, and detailed training datasets, greatly benefiting researchers and developers.
Technical Principles of FG-CLIP 2
-
Hierarchical Alignment Architecture:
Improves image detail understanding through global semantic alignment and fine-grained vision-language learning. -
Dynamic Attention Mechanism:
Focuses intelligently on key visual regions, enhancing performance on complex tasks. -
Bilingual Collaboration Strategy:
Optimizes the balance between Chinese and English comprehension, boosting overall bilingual performance. -
Multimodal Data Training:
Trained on large-scale Chinese-English image-text pairs to enhance cross-lingual generalization. -
Fine-Grained Supervised Learning:
Introduces supervision signals such as region-text matching and long-description modeling to strengthen fine-grained visual understanding. -
Intra-Text Contrastive Learning:
Applies intra-modal text contrastive loss to better distinguish semantically similar descriptions. -
Hard Negative Sample Training:
Incorporates “hard negatives” generated by large models to further enhance model robustness and accuracy. -
Dynamic Resolution Mechanism:
Enables adaptive processing of inputs with varying resolutions, improving flexibility and versatility.
Project Links
-
Official Website: https://360cvgroup.github.io/FG-CLIP/
-
GitHub Repository: https://github.com/360CVGroup/FG-CLIP
-
arXiv Paper: https://arxiv.org/pdf/2510.10921
Application Scenarios of FG-CLIP 2
-
Home Robotics:
Accurately understands and executes complex home instructions such as “pick up the phone with a cracked screen on the coffee table,” improving the practicality of home robots. -
Security Monitoring:
Quickly locates and identifies targets, e.g., “find the suspicious person wearing a black cap,” increasing efficiency and accuracy in surveillance systems. -
E-commerce:
Enhances text-to-image retrieval accuracy and reduces multilingual labeling costs, optimizing user experience through precise understanding of product descriptions. -
Autonomous Driving:
Accurately recognizes road objects and scenes, such as “detect obstacles in the front lane,” improving driving safety. -
Medical Imaging:
Assists doctors in diagnostic imaging tasks, such as “identify abnormal areas in X-ray images,” improving diagnostic accuracy and efficiency. -
Education:
Powers intelligent educational tools that can “recognize objects in pictures and provide related knowledge,” enriching teaching content and interactivity.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...