Open-o3 Video – A video reasoning model open-sourced jointly by Peking University and ByteDance
What is Open-o3 Video?
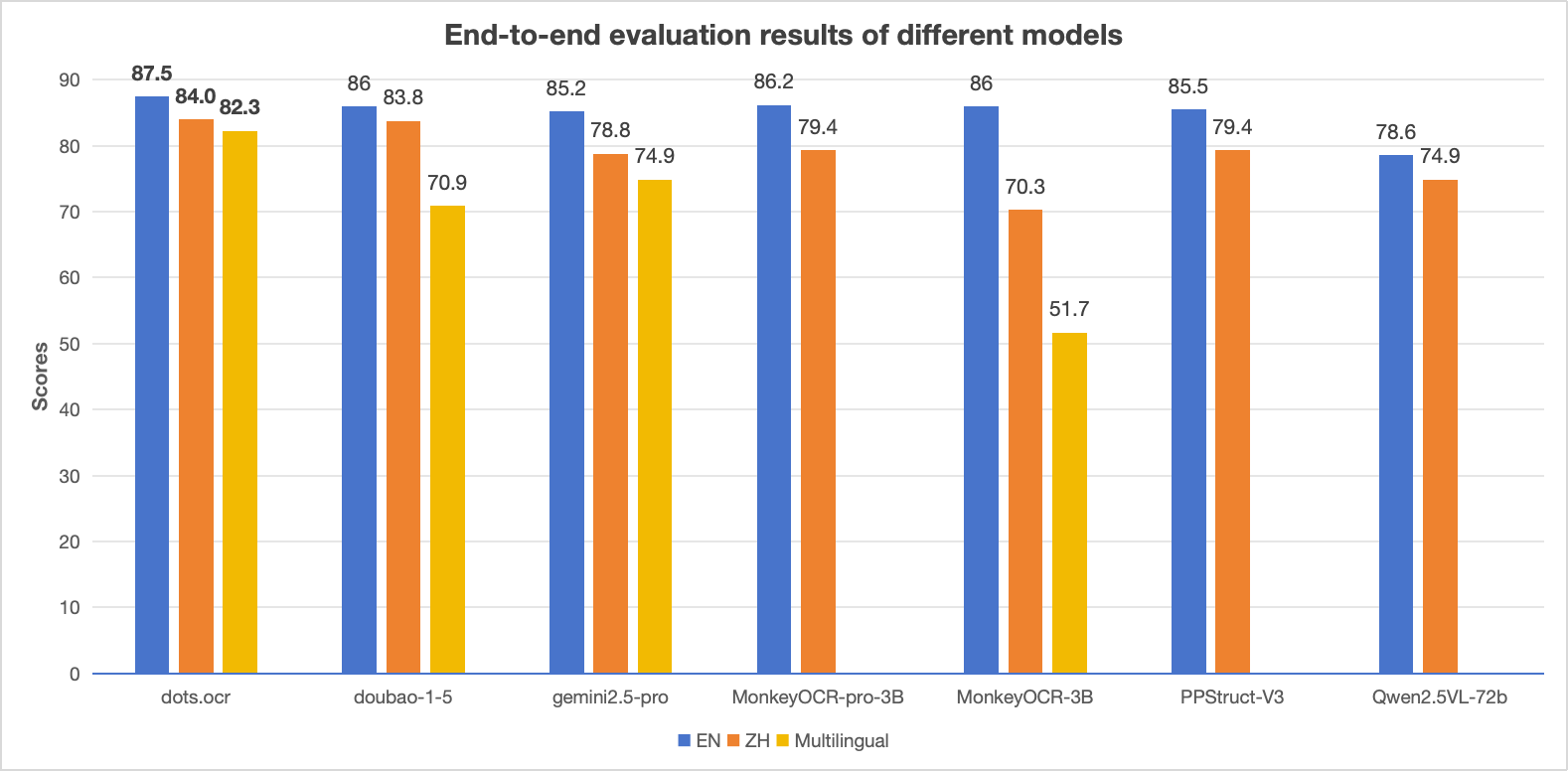
Open-o3 Video is an open-source video reasoning model jointly developed by Peking University and ByteDance. It achieves precise video reasoning by integrating explicit spatiotemporal evidence—such as key timestamps and bounding boxes. Supported by the carefully curated STGR dataset and a two-phase SFT-RL training strategy, the model delivers state-of-the-art performance on the V-STAR benchmark.Its non-agent architecture is optimized for handling complex spatiotemporal relationships efficiently, resulting in strong performance on video reasoning tasks. The training pipeline includes two phases—cold-start initialization and reinforcement learning—enabling the model to adapt effectively to diverse video-reasoning scenarios.

Key Features of Open-o3 Video
1. Spatiotemporal Reasoning
Integrates explicit spatiotemporal evidence, including key timestamps and bounding boxes, enabling accurate video reasoning and robust handling of temporal and spatial relationships within videos.
2. Data Curation & Training Strategy
Uses the curated STGR dataset and a two-phase SFT-RL training strategy:
-
Cold-start initialization with supervised learning,
-
Followed by reinforcement learning to optimize model performance.
This approach helps Open-o3 Video achieve strong results on the V-STAR benchmark.
3. Non-Agent Architecture
The non-agent design efficiently processes complex spatiotemporal relationships, improving both accuracy and computational efficiency in video reasoning tasks.
4. Open Source & Extensibility
Being fully open-source, the model is easy for researchers and developers to use, modify, and extend—helping accelerate progress in video reasoning research.
Technical Principles of Open-o3 Video
1. Explicit Spatiotemporal Evidence Integration
By explicitly incorporating key timestamps and bounding boxes, the model tightly couples reasoning with actual visual observations, making its predictions more interpretable and reliable.
2. Two-Phase Training Strategy
The model combines cold-start initialization and reinforcement learning:
-
The cold-start stage uses supervised learning to build foundational spatiotemporal reasoning ability.
-
The reinforcement learning stage introduces multiple reward mechanisms to further improve accuracy, temporal alignment, and spatial precision.
3. Dataset Curation
Two high-quality datasets—STGR-CoT-30k and STGR-RL-36k—provide rich spatiotemporal annotations and reasoning traces. These datasets address the lack of unified spatiotemporal supervision in existing video-reasoning resources.
4. Non-Agent Framework Design
The non-agent architecture efficiently handles complex spatiotemporal relationships, avoiding information loss and inefficiency that may occur in agent-based models, ultimately improving overall reasoning performance.
Project Links
-
Project Website: https://marinero4972.github.io/projects/Open-o3-Video/
-
GitHub Repository: https://github.com/marinero4972/Open-o3-Video
-
HuggingFace Model: https://huggingface.co/marinero4972/Open-o3-Video/tree/main
-
arXiv Paper: https://arxiv.org/pdf/2510.20579
Application Scenarios of Open-o3 Video
1. Video Content Understanding
Accurately identifies and analyzes key events and objects in videos. By leveraging explicit spatiotemporal evidence, it provides detailed reasoning and explanations, helping users understand core video content.
2. Video Question Answering Systems
Serves as the core engine for video QA. It can quickly localize relevant spatiotemporal segments based on user queries and generate accurate, interpretable answers.
3. Video Editing & Creation
Assists creators by identifying key elements and highlight moments within videos—making tasks like editing, clipping, and applying effects more efficient.
4. Intelligent Surveillance & Analysis
Supports real-time analysis of surveillance footage, rapidly detecting abnormal events and important objects with detailed spatiotemporal evidence, helping upgrade intelligent security systems.
5. Education & Training
Can be used to analyze teaching videos, helping teachers and students better understand content and providing more targeted feedback for learning.
6. Entertainment & Interactive Media
Enhances interactivity for short-video platforms, livestreaming, and similar services—for example, generating creative reasoning-based Q&A or challenges to boost user engagement.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...