
OmniVinci — NVIDIA’s newly released omni-modal large language model
What is OmniVinci?
OmniVinci is NVIDIA’s omni-modal large language model designed to handle multimodal tasks involving vision, audio, language, and reasoning. It uses the unique OmniAlignNet technology to achieve cross-modal semantic alignment, the Temporal Embedding Grouping mechanism to solve temporal synchronization issues, and Constrained Rotary Time Embedding to enhance time-awareness.On benchmarks such as DailyOmni, OmniVinci outperforms models like Qwen2.5, especially in audio–video synchronization and understanding tasks. The model requires only 0.2 trillion training tokens, making it far more efficient than similar models, and is well-suited for applications such as media analysis and game development.
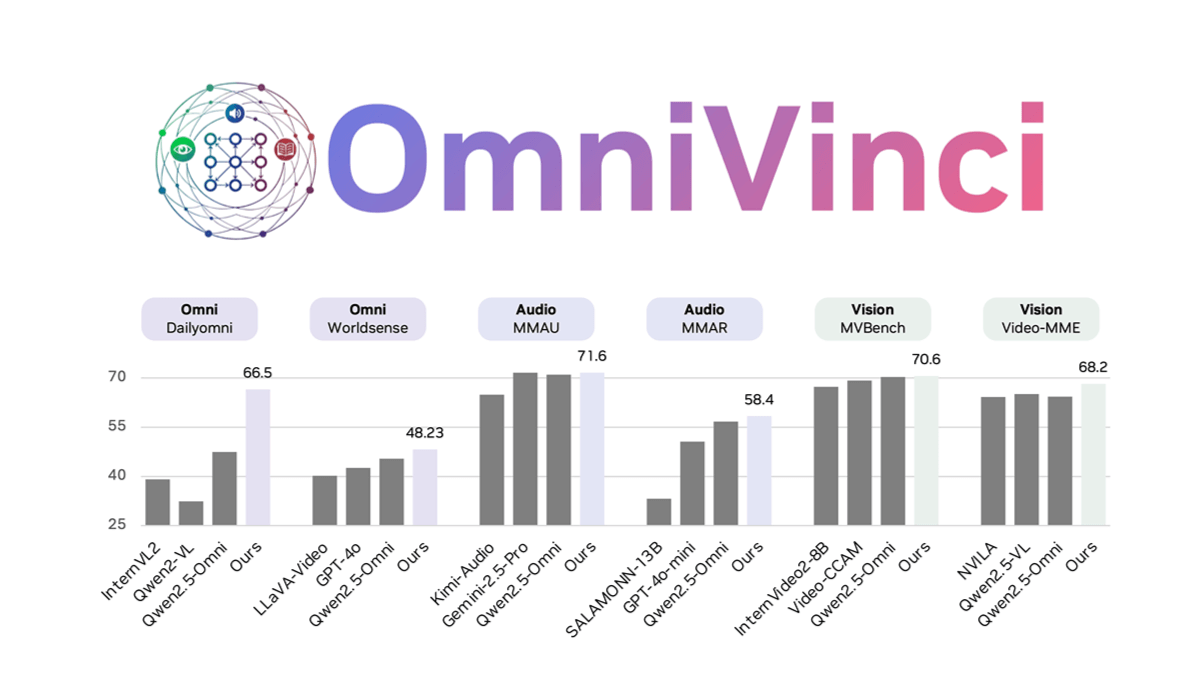
Key Features of OmniVinci
1. Multimodal Understanding
OmniVinci can process visual (images, videos), audio, and text inputs simultaneously, enabling unified cross-modal understanding.
It can accurately fuse information from different modalities—for example, identifying human actions, speech content, and scene context within a video.
2. Cross-Modal Alignment
Through the OmniAlignNet module, OmniVinci enhances alignment between visual and audio embeddings in a shared omni-modal latent space, solving the semantic inconsistency issues common in traditional multimodal models.
3. Temporal Information Processing
With Temporal Embedding Grouping and Constrained Rotary Time Embedding, OmniVinci effectively handles temporal alignment and absolute time encoding across visual and auditory signals. This makes it suitable for time-sensitive tasks such as video surveillance and audio analysis.
4. Wide Range of Applications
OmniVinci can be applied to scenarios such as video content analysis, medical AI, robotic navigation, speech transcription and translation, and industrial inspection—providing powerful multimodal solutions across industries.
5. Open Source and Community Collaboration
The model’s code, datasets, and web demos are all open-sourced, enabling researchers and developers to experiment, extend, and contribute to the omni-modal AI community.
Technical Principles of OmniVinci
1. OmniAlignNet Module
OmniAlignNet strengthens the alignment of visual and audio embeddings within a shared omni-modal latent space, addressing the semantic disconnect often seen across modalities and improving overall fusion quality.
2. Temporal Embedding Grouping
This technique captures relative temporal alignment between visual and audio signals, enabling OmniVinci to better understand temporal logic within multimodal sequences.
3. Constrained Rotary Time Embedding
By using dimension-sensitive rotary encoding, OmniVinci can precisely represent absolute time information, further improving its ability to handle time-series data.
4. Data Optimization & Synthetic Data Generation
OmniVinci uses a carefully designed data synthesis pipeline to generate 24 million single-modal and omni-modal dialogue samples—15% of which are explicit multimodal synthetic data.
A multi-model collaborative error-correction mechanism helps eliminate “modality hallucinations,” improving data quality.
5. Efficient Training Strategy
OmniVinci is trained on only 0.2T tokens, compared to 1.2T tokens used by similar models.
Despite this reduced training cost, it achieves strong performance on multimodal tasks through an optimized training process.
6. Reinforcement Learning Enhancement
The model is trained under the GRPO reinforcement learning framework, which accelerates convergence and boosts performance on multimodal reasoning tasks by combining visual and auditory reward signals.
7. Architectural Innovations
OmniVinci introduces several architectural innovations—OmniAlignNet, Temporal Embedding Grouping, and Constrained Rotary Time Embedding—which significantly improve multimodal understanding capabilities.
Project Links
-
Project Website: https://nvlabs.github.io/OmniVinci/
-
GitHub Repository: https://github.com/NVlabs/OmniVinci
-
HuggingFace Model: https://huggingface.co/nvidia/omnivinci
-
arXiv Paper: https://arxiv.org/pdf/2510.15870
Application Scenarios of OmniVinci
1. Video Content Analysis
OmniVinci can describe human actions, dialogue content, and scene details in videos—useful for commentary generation, sports analysis, news production, and more.
2. Medical AI
By combining doctors’ spoken explanations with medical imaging (such as CT or MRI), OmniVinci can answer complex medical questions and support diagnosis and treatment planning, improving accuracy and efficiency.
3. Robotic Navigation
OmniVinci enables more effective human–robot interaction through voice-controlled navigation, suitable for home-service robots, industrial robots, and other intelligent systems.
4. Speech Transcription & Translation
Supports speech transcription and multilingual translation, making it ideal for real-time meetings, voice assistants, and online education.
5. Industrial Inspection
By combining visual and audio information, OmniVinci helps detect defects in semiconductor components, monitor production lines, and improve industrial detection accuracy while reducing labor costs.
6. Intelligent Security
In security systems, OmniVinci can analyze both video and audio signals to detect abnormal behaviors or events in real time, boosting the intelligence level of surveillance systems.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...