
OmniTalker – Alibaba’s Real-time Text-driven Talking Avatar Generation Framework
What is OmniTalker?
OmniTalker is a real-time text-driven talking head generation technology released by Alibaba. It can process various multimodal inputs such as text, images, audio, and video simultaneously, and generate natural speech responses in a streaming manner. Its core architecture is the Thinker-Talker framework. The Thinker is responsible for processing multimodal inputs and generating semantic representations and textual content, while the Talker converts this information into smooth speech output. OmniTalker employs the TMRoPE (Time-aligned Multimodal Rotary Position Embedding) technique to ensure precise synchronization between video and audio inputs.
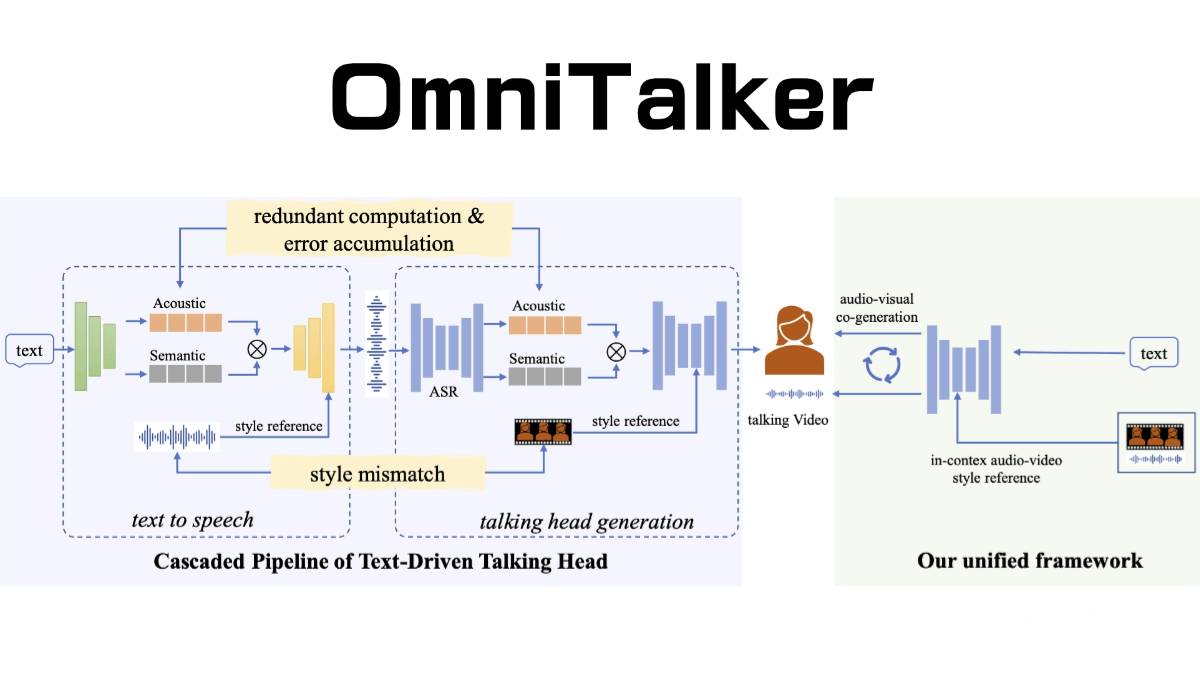
The main functions of OmniTalker
- Multimodal Input Processing: Capable of perceiving multiple modalities such as text, images, audio, and video.
- Streaming Generation of Text and Speech Responses: Generates text and natural speech responses in a streaming manner. Audio and video encoders adopt a chunk-based processing method, decoupling the handling of long-sequence multimodal data.
- Precise Audio-Video Synchronization: Proposes the TMRoPE (Time-aligned Multimodal RoPE) technique to organize audio and video in an interleaved sequential manner, achieving precise synchronization of inputs.
- Real-time Interaction: Supports chunked input and immediate output, enabling fully real-time interaction.
- Natural and Fluent Speech Generation: Delivers excellent performance in the naturalness and stability of speech generation, surpassing many existing streaming and non-streaming alternatives.
- Performance Advantages: Excels in multimodal benchmark tests, with audio capabilities outperforming similar-sized Qwen2-Audio and maintaining parity with Qwen2.5-VL-7B.
The technical principle of OmniTalker
- Thinker-Talker Architecture: OmniTalker adopts the Thinker-Talker architecture, where the Thinker is responsible for processing multimodal inputs (including text, images, audio, and video) to generate high-dimensional semantic representations and textual content. The Talker, based on the semantic representations and text provided by the Thinker, generates natural speech responses in a streaming manner. This approach avoids interference between text generation and speech generation, ensuring semantic consistency and real-time performance.
◦ Thinker: Based on a Transformer decoder architecture equipped with audio and image encoders, the Thinker is responsible for extracting and understanding multimodal information.
◦ Talker: Utilizing a dual-track autoregressive Transformer decoder structure, the Talker directly generates speech tokens from the high-dimensional semantic representations provided by the Thinker, ensuring the naturalness and fluency of speech output. - TMRoPE (Time-aligned Multimodal Rotational Position Embedding): To address the time synchronization issue of audio and video inputs, OmniTalker introduces the TMRoPE technique. By interleaving audio and video frames in chronological order and applying positional encoding, it ensures seamless alignment of information across different modalities on the time axis. This enables the model to more accurately understand and generate audio-video content.
- Stream Processing: OmniTalker supports streaming input and output, enabling real-time processing of multimodal information and rapid response. The audio and visual encoders adopt a chunk-based processing method, dividing long-sequence data into smaller chunks for processing, thereby reducing latency and improving efficiency.
◦ Chunk Prefilling: The audio encoder utilizes a 2-second chunk-based attention mechanism, while the visual encoder employs flash attention with an added MLP layer to enhance efficiency.
◦ Sliding Window DiT Model: Used for streaming generation of mel spectrograms, further supporting high-quality streaming speech generation. - End-to-end training: The Thinker and Talker modules are jointly trained in an end-to-end manner, sharing historical context information. This avoids potential errors that may accumulate between separately trained modules, ensuring the overall performance and consistency of the model.
- Efficient Voice Generation: The voice generation module of OmniTalker utilizes an efficient speech codec (qwen-tts-tokenizer) to generate audio tokens in a streaming manner through autoregression. This reduces data requirements and inference difficulty while enhancing the naturalness and robustness of voice generation.
The project address of OmniTalker
- Project official website: https://humanaigc.github.io/omnitalker/
- arXiv technical paper: https://arxiv.org/pdf/2504.02433v1
Application scenarios of OmniTalker
- Intelligent Voice Assistant: OmniTalker’s real-time audio and video interaction capabilities and natural and smooth voice generation ability make it an ideal intelligent voice assistant. It can process users’ voice commands and generate real-time voice responses, providing users with a more natural and convenient interaction experience.
- Multimodal Content Creation: In the field of content creation, OmniTalker can process text, image, and video inputs simultaneously, generating corresponding text or voice descriptions.
- Education and Training: OmniTalker can be used in the field of education and training. By processing multimodal inputs, it can provide students with a richer and more personalized learning experience.
- Intelligent Customer Service: In the field of intelligent customer service, OmniTalker can process customer voice or text questions in real time, generating accurate responses. This improves customer service efficiency and enhances the customer experience.
- Industrial Quality Inspection: In the manufacturing field, OmniTalker can simultaneously process product appearance images and process parameter texts to detect defective parts on the production line in real time.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts



No comments yet...