
Meta open-sourced Llama 4 late at night! First use of MoE, amazing 10 million token contexts, surpassing DeepSeek in the arena
Never expected. Meta chose to release its latest AI model series — Llama 4 over the weekend. This is the newest member of its Llama family.
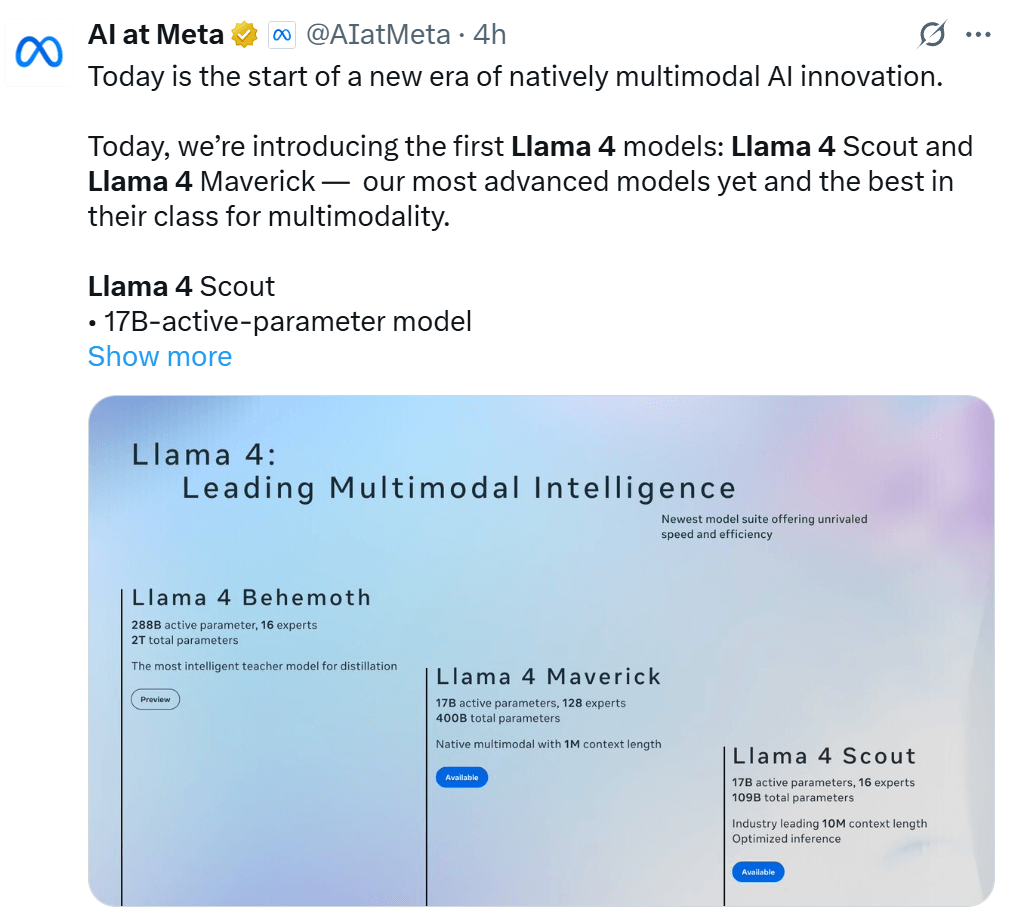
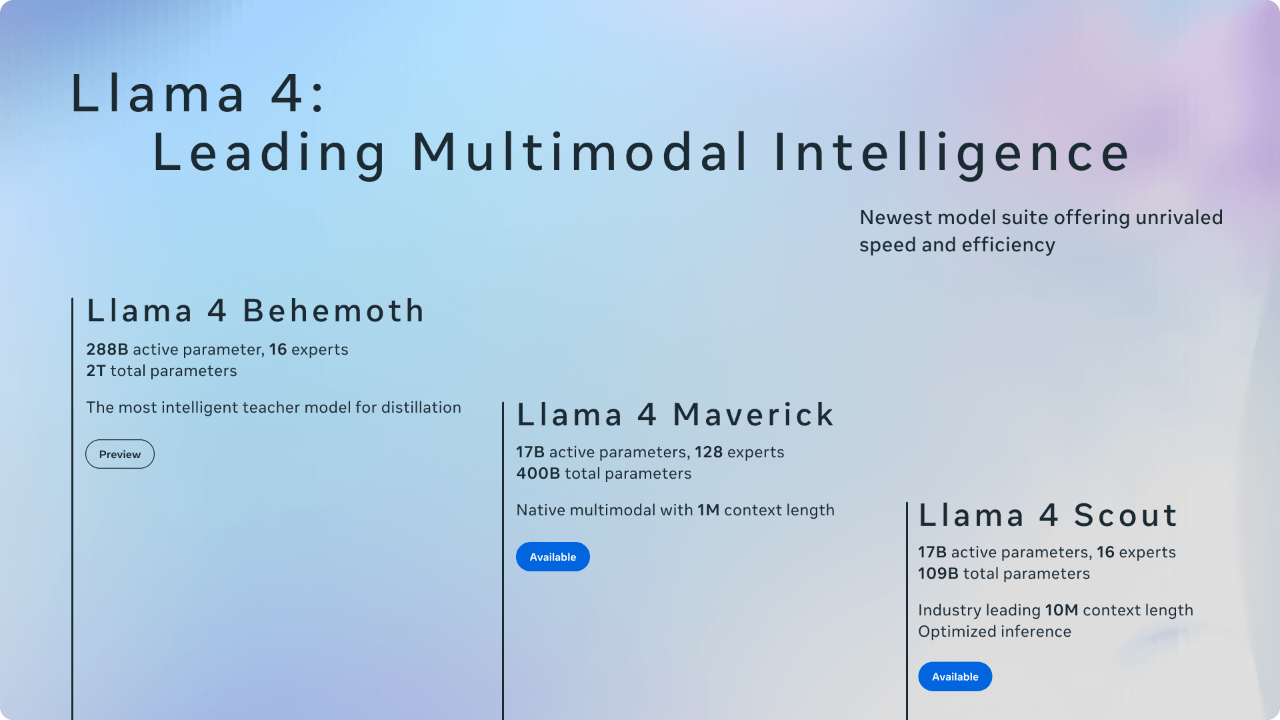
This series includes Llama 4 Scout, Llama 4 Maverick, and Llama 4 Behemoth. All these models have been trained on a vast amount of unlabeled text, image, and video data to endow them with extensive visual understanding capabilities.
Ahmad Al-Dahle, head of Meta GenAI, said that Llama 4 demonstrates Meta’s long-term commitment to open-source AI and the entire open-source AI community, as well as its unwavering belief that open systems will produce the best small, medium, and upcoming cutting-edge large models.
Google CEO Sundar Pichai couldn’t help but exclaim that the world of artificial intelligence is never boring. Congratulations to the Llama 4 team. Keep moving forward!
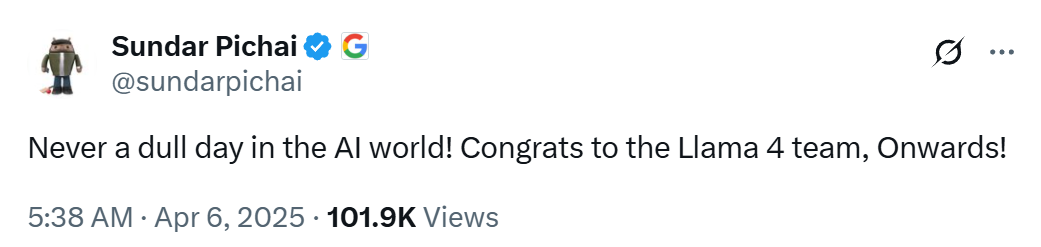
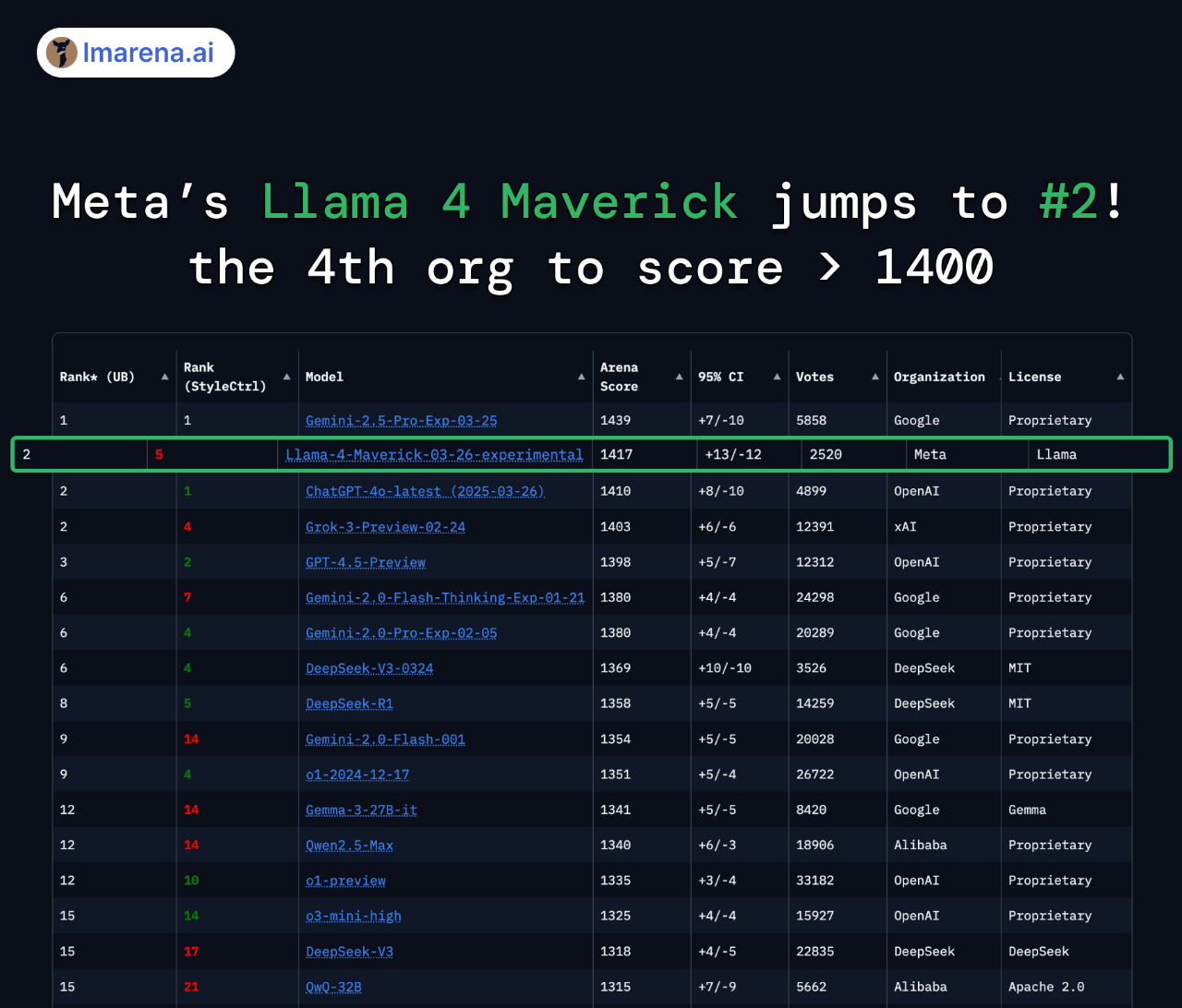
In the Arena for large models, Llama 4 Maverick ranks second overall, becoming the fourth large model to break the 1400-point barrier. It ranks first among open models, surpassing DeepSeek; it ranks first in tasks such as difficult prompts, programming, mathematics, and creative writing; it significantly outperforms its predecessor, Llama 3 405B, with its score rising from 1268 to 1417; it ranks fifth in style control.
So, what are the characteristics of the Llama 4 model series? Specifically:
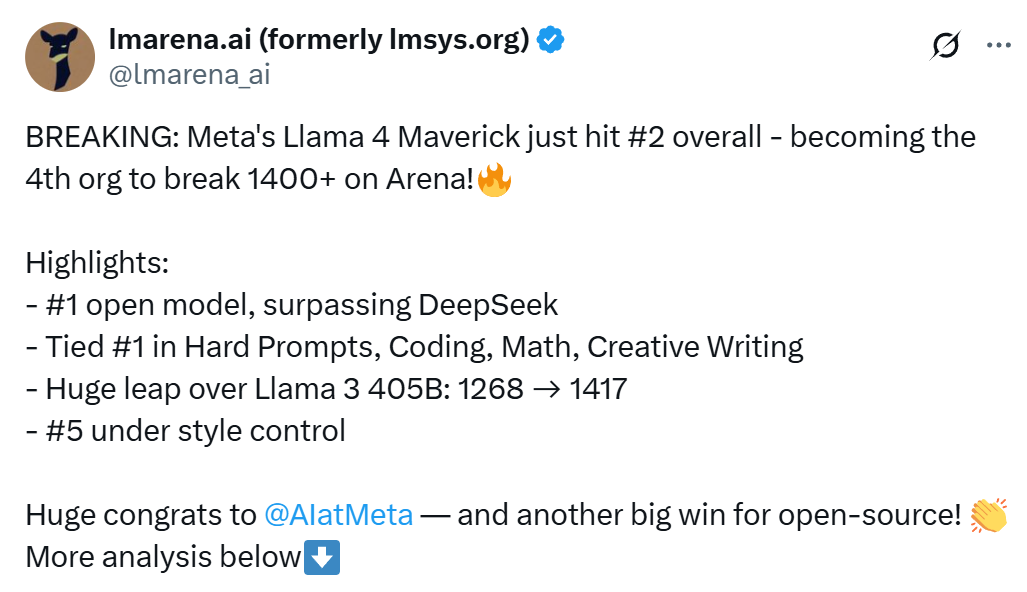
Llama 4 Scout is a model with 17 billion activated parameters and 16 experts. It is the best multimodal model globally of its kind, more powerful than previous generations of Llama models and capable of running on a single NVIDIA H100 GPU. Additionally, Llama 4 Scout offers an industry-leading 10M context window and outperforms Gemma 3, Gemini 2.0 Flash-Lite, and Mistral 3.1 in widely reported benchmarks.
Llama 4 Maverick is a model with 128 experts and 17 billion activated parameters, making it the best multimodal model of its kind. It has outperformed GPT-4o and Gemini 2.0 Flash in widely reported benchmarks, while achieving results comparable to the new DeepSeek v3 in reasoning and programming — with less than half the activated parameters. Llama 4 Maverick offers a top-notch price-performance ratio, and its experimental chat version has achieved an ELO score of 1417 on LMArena.
The above two models are the best models that Meta has developed so far. This is mainly because they are obtained through knowledge distillation from the Llama 4 Behemoth model, which has 288 billion activation parameters and 16 experts.
Llama 4 Behemoth is one of Meta’s most powerful models and also one of the smartest large language models in the world. In multiple Science, Technology, Engineering, and Mathematics (STEM) benchmark tests, Llama 4 Behemoth outperforms GPT-4.5, Claude 3.7 Sonnet, and Gemini 2.0 Pro.
However, Llama 4 Behemoth is still under training. Meta will release more content later.
The good news is that users can now download the latest Llama 4 Scout and Llama 4 Maverick models on llama.com and Hugging Face.
All Llama 4 models adopt a native multimodal design. For example, you can upload an image and ask any questions about it.

Llama 4 Scout supports a context length of up to 10 million tokens, which is currently the longest context length in the industry, unlocking new use cases around memory, personalization, and multimodal applications.

Llama 4 is also excellent in image grounding, capable of aligning user prompts with relevant visual concepts and anchoring the model’s responses to specific regions in the image.

Llama 4 has undergone pre-training and fine-tuning, enabling it to understand unparalleled text in 12 languages and supporting global development and deployment.

Pre-training
When constructing the next-generation Llama model, Meta experimented with various new methods during the pre-training phase.
First of all, this is the first time that Meta has adopted the Mixture of Experts (MoE) architecture. In the MoE model, a single token only activates a portion of the total parameters. Meta states that the MoE architecture is more computationally efficient during training and inference, and provides higher quality compared to dense models under a fixed training FLOPs budget.
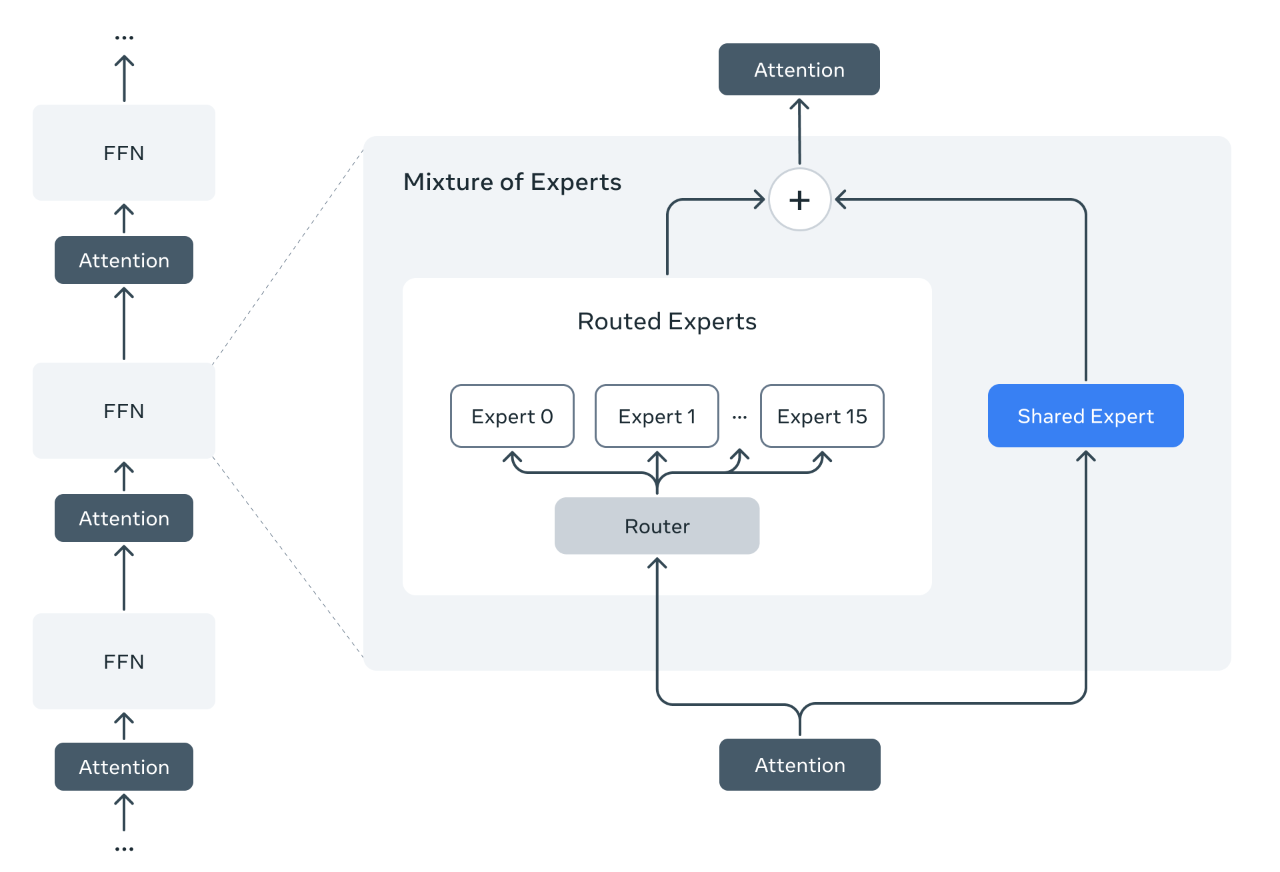
Taking the Llama 4 Maverick model as an example, this model has 17 billion activated parameters and 400 billion total parameters. Meta adopts alternating dense layers and mixture-of-experts (MoE) layers to improve inference efficiency. In the MoE layers, they utilize 128 routing experts and one shared expert. Each token will be sent to the shared expert and one of the 128 routing experts.
Therefore, although all parameters are stored in memory, only a portion of the total parameters is activated when serving these models. This improves inference efficiency by reducing model serving costs and latency —— Llama 4 Maverick can run on a single NVIDIA H100 DGX host for easy deployment, or achieve maximum efficiency through distributed inference.
The Llama 4 series models adopt a native multimodal design, seamlessly integrating text and visual tokens into a unified model backbone through early fusion. Early fusion represents a significant advancement, as it enables the model to be jointly pre-trained using a vast amount of unannotated text, image, and video data. Additionally, Meta has improved the visual encoder in Llama 4, which is based on MetaCLIP, to better adapt the encoder to the LLM.
Additionally, Meta has developed a new training technique called MetaP, which can reliably set model hyperparameters, such as the learning rate and initialization scale per layer. Meta found that the selected hyperparameters exhibit good transferability across different batch sizes, model widths, depths, and training token values.
Llama 4 has been pre-trained on 200 languages and supports open-source fine-tuning efforts, covering more than 100 languages with over 1 billion tokens for each language. Overall, it has 10 times more multilingual tokens than Llama 3.
In addition, Meta employs FP8 precision for training, achieving both quality and high FLOPs utilization. When pre-training the Llama 4 Behemoth model using FP8 and 32K GPUs, Meta achieved 390 TFLOPs per GPU. The total amount of data mixed used for training exceeds 30 trillion tokens, more than double the amount of data mixed used for pre-training Llama 3, and encompasses diverse text, image, and video datasets.
Finally, Meta continues to train the model through so-called mid-training to enhance its core capabilities, including expanding long contexts with specialized datasets. This enables Meta to improve the model’s quality while unlocking an industry-leading input context length of 10 million for Llama 4 Scout.
Post-training
Llama 4 Maverick delivers unparalleled, industry-leading performance in image and text understanding, enabling the creation of complex AI applications that transcend language barriers. As the flagship model for general-purpose assistants and chat use cases, Llama 4 Maverick excels in precise image understanding and creative writing.
When conducting post-training on the Llama 4 Maverick model, the biggest challenge is to balance multiple input modalities, reasoning ability, and conversational ability. To mix modalities, Meta designed a carefully orchestrated curriculum strategy that does not degrade performance compared to single-modality expert models.
In Llama 4, Meta has comprehensively improved the post-training process by adopting different methods: lightweight Supervised Fine-Tuning (SFT) > Online Reinforcement Learning (RL) > Lightweight Direct Preference Optimization (DPO). Meta found that SFT and DPO may overly constrain the model, limiting the exploration ability during the online RL phase, thereby reducing accuracy in reasoning, programming, and math domains.
To address this issue, Meta utilized the Llama model as an evaluator, removed over 50% of the data labeled as “easy,” and performed lightweight supervised fine-tuning (SFT) on the remaining more challenging dataset. In the subsequent multimodal online reinforcement learning (RL) phase, significant performance improvements were achieved by carefully selecting more difficult prompts.
In addition, Meta has implemented a continuous online Reinforcement Learning (RL) strategy, alternating between training the model and using it to continuously filter and retain prompts of medium to high difficulty. This strategy is highly beneficial in terms of the trade-off between computation and accuracy.
Finally, Meta also conducted lightweight Direct Preference Optimization (DPO) to address edge cases related to model response quality, effectively achieving a good balance between model intelligence and conversational ability. These improvements have resulted in an industry-leading general-purpose chat model with state-of-the-art intelligence and image understanding capabilities.
function and performance
Llama 4 Maverick boasts 17 billion activated parameters, 128 experts, and a total of 400 billion parameters. Compared to Llama 3.3 70B, it offers higher quality at a lower price. As shown in the table below, Llama 4 Maverick is the best-performing multimodal model of its kind, surpassing similar models such as GPT-4o and Gemini 2.0 in coding, reasoning, multilingual, long-context, and image benchmark tests. It is also competitive with the larger-scale DeepSeek v3.1 in coding and reasoning.
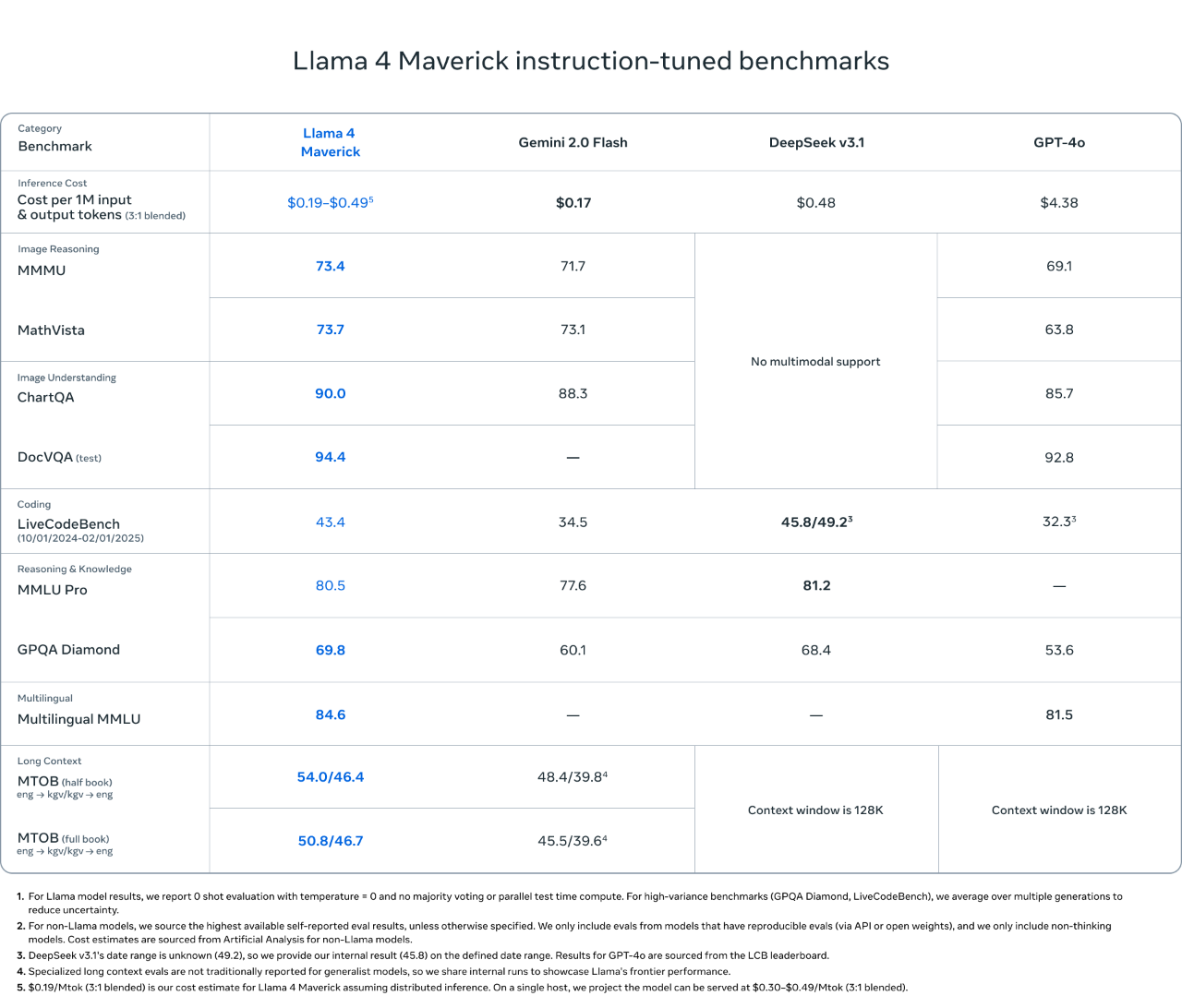
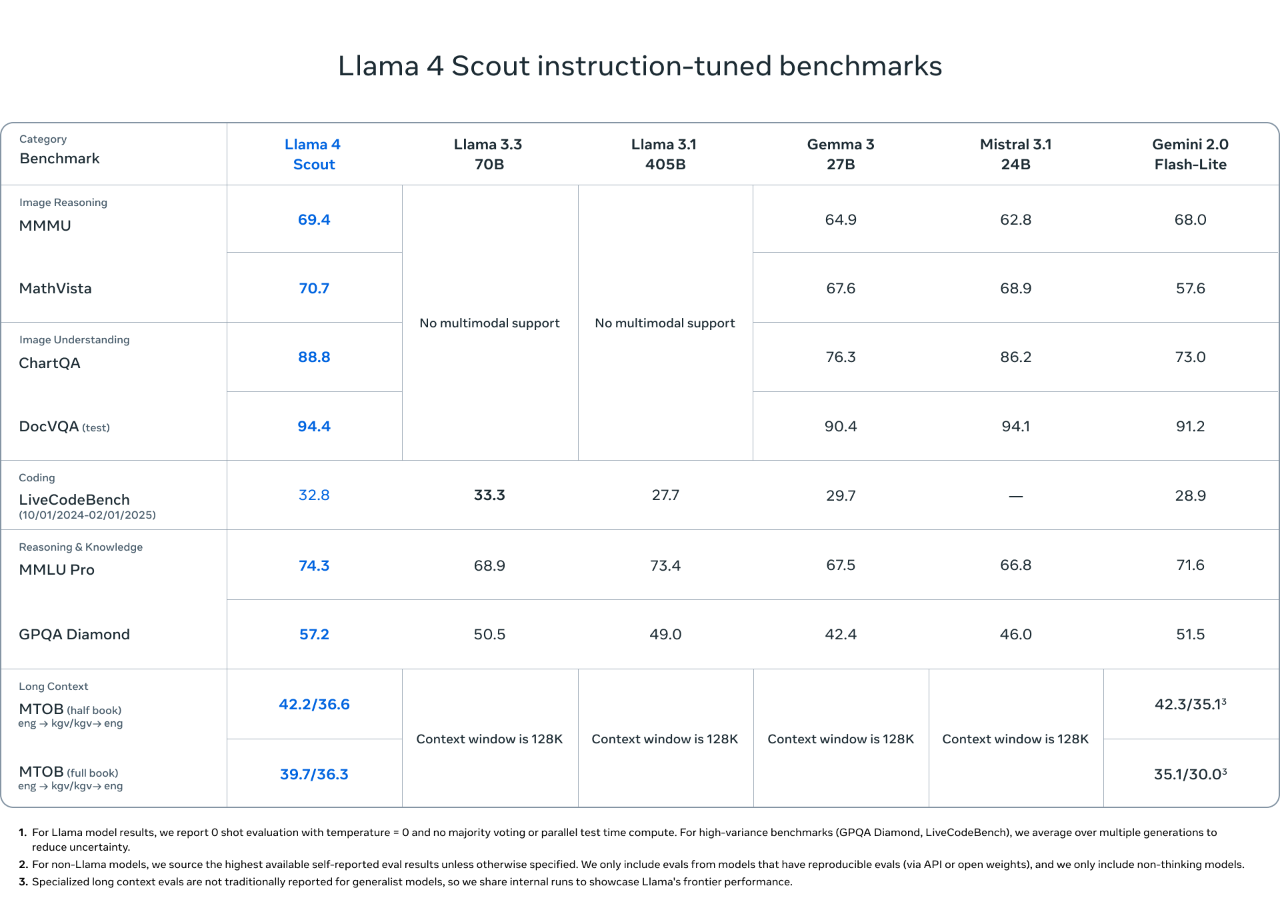
The smaller model, Llama 4 Scout, is a general-purpose model with 17 billion activation parameters, 16 experts, and 109 billion total parameters, delivering state-of-the-art performance in its category. Llama 4 Scout significantly increases the supported context length from 128K in Llama 3 to an industry-leading 10 million tokens. This provides greater possibilities for applications such as multi-document summarization, parsing extensive user activities for personalized tasks, and reasoning over large codebases.
Llama 4 Scout utilizes a context length of 256K during both pre-training and post-training, endowing the base model with robust long-context generalization capabilities. In tasks such as needle-in-a-haystack retrieval, the model has demonstrated convincing results.
One of the key innovations of the Llama 4 architecture is the use of interleaved attention layers without positional embeddings, enhanced by temperature scaling during inference to improve long-context generalization. This architecture is referred to as the iRoPE architecture, where “i” stands for interleaved attention layers, emphasizing its long-term goal of supporting unlimited context lengths, and “RoPE” refers to the rotational positional embeddings used in most layers.
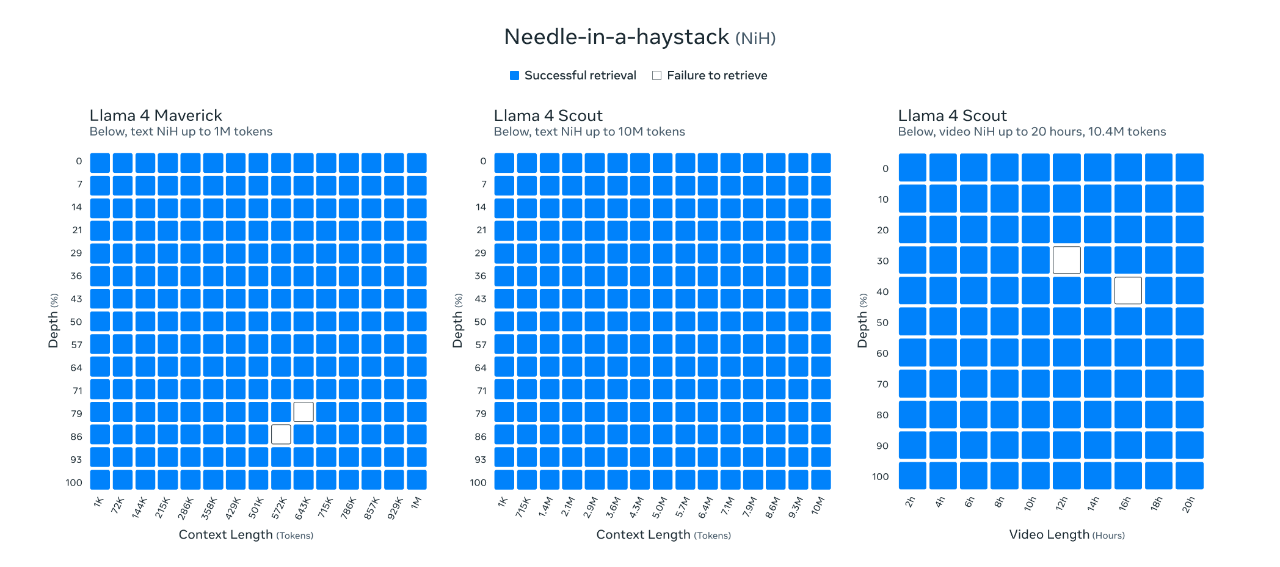
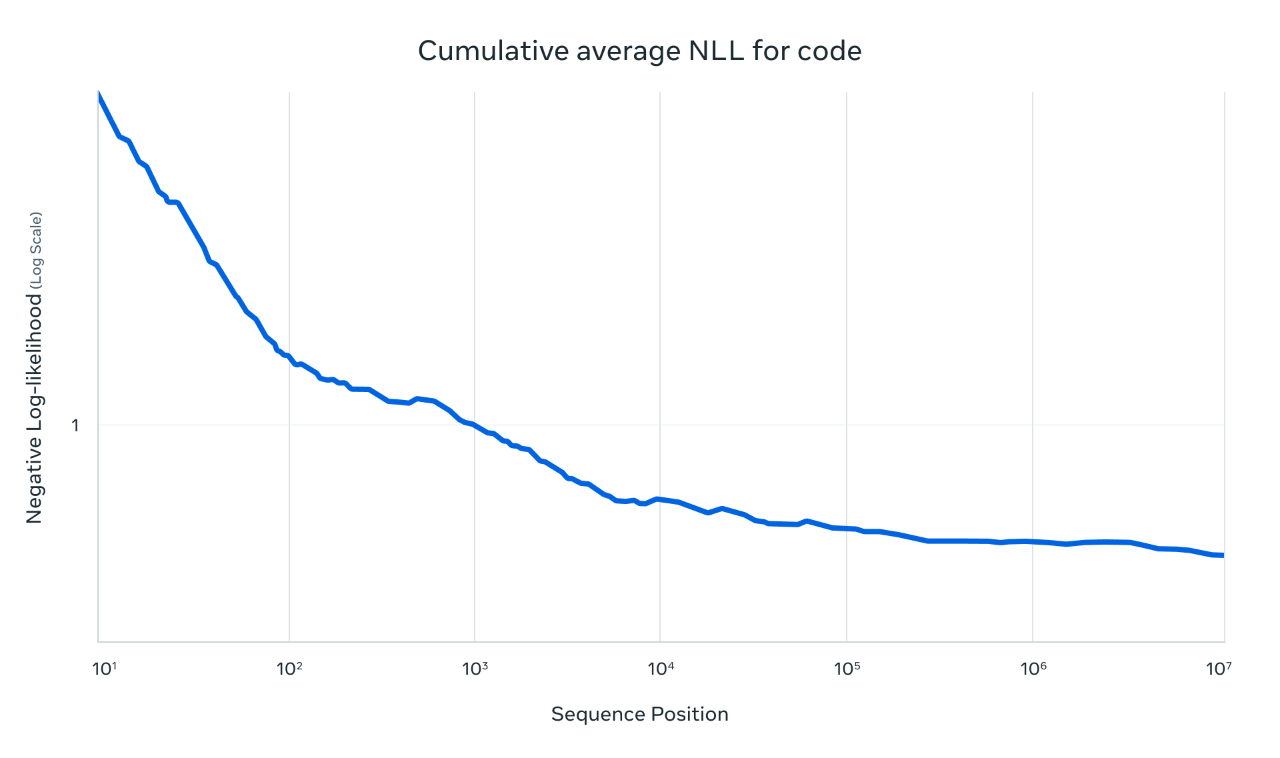
Meta conducted extensive training on two models using images and video frames of still images to endow them with broad visual understanding capabilities, including the understanding of temporal activities and related images. This enables the models to easily perform visual reasoning and understanding tasks with multi-image inputs and text prompts. These models support up to 48 images during pre-training and 8 images during post-training, achieving good results.
Llama 4 Scout demonstrates exceptional performance in image localization. It can align user prompts with relevant visual concepts and anchor the model’s responses to specific regions within the image. This enables large language models to perform visual question answering more precisely, better understand user intentions, and locate objects of interest.
In addition, Llama 4 Scout outperforms similar models in coding, reasoning, long context, and image benchmark tests, and exhibits stronger performance than all previous Llama models.
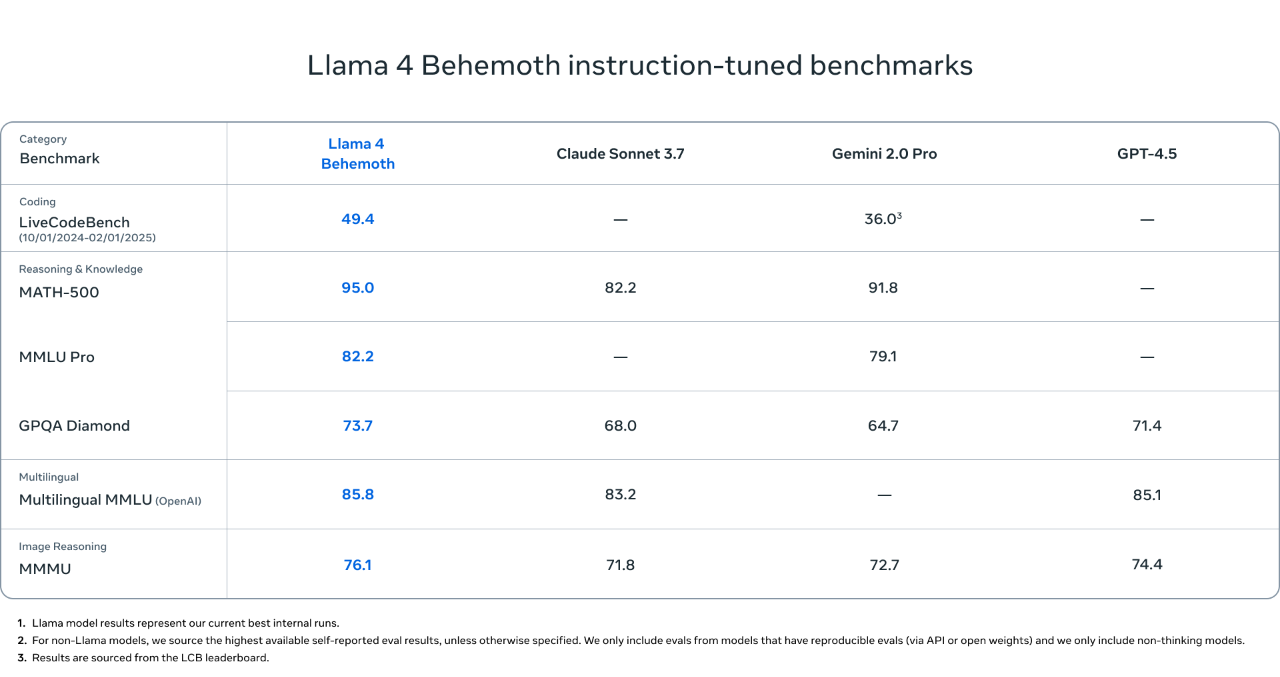
Pushing Llama to a New Scale: 2T Behemoth
The Llama 4 Behemoth Preview is a teacher model and a multimodal mixture-of-experts model, featuring 288 billion activation parameters, 16 experts, and nearly 2 trillion total parameters.
In mathematical, multilingual, and image benchmark tests, it delivers state-of-the-art performance among non-inference models, making it the perfect choice for training smaller Llama 4 models.
Training a model with two trillion parameters post-training is a huge challenge, requiring researchers to completely redesign and improve the training plan starting from the data scale. To maximize performance, Meta had to prune 95% of the Supervised Fine-Tuning (SFT) data, while the pruning ratio for smaller models was 50%. This measure was taken to achieve the necessary balance between quality and efficiency. Meta also found that performing lightweight Supervised Fine-Tuning (SFT) first, followed by large-scale Reinforcement Learning (RL), can significantly enhance the model’s reasoning and coding capabilities.
Meta’s reinforcement learning (RL) approach focuses on conducting pass@k analysis through policy models, sampling prompts with higher difficulty levels, and constructing training curricula with gradually increasing difficulty. Additionally, during the training process, prompts with zero advantage are dynamically filtered out, and mixed prompt training batches containing diverse capabilities are constructed. These measures have significantly enhanced the model’s performance in mathematics, reasoning, and coding. Finally, sampling from a variety of system instructions is crucial for ensuring that the model maintains instruction-following capabilities in reasoning and coding tasks, enabling it to perform excellently across a wide range of tasks.
Expanding reinforcement learning (RL) for a model with two trillion parameters is also a huge challenge, which forces Meta to redesign and improve the underlying reinforcement learning infrastructure to cope with unprecedented scale.
Meta has optimized the design of Mixed Expert (MoE) parallelization to enhance speed and thereby accelerate the iteration process. Additionally, they have developed a fully asynchronous online reinforcement learning training framework, which improves flexibility. Compared to existing distributed training frameworks that sacrifice computational memory in order to load all models into memory, Meta’s new infrastructure can flexibly allocate different models to different GPUs and balance resources among multiple models based on computing speed. This innovation has increased training efficiency by approximately 10 times compared to the previous generation.
Llama 4 Scout and Llama 4 Maverick are now available for download. Address:
- llama.com: https://www.llama.com/llama-downloads/
- Hugging Face address: https://huggingface.co/meta-llama
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...