Maya1 — an open-source speech generation model developed by the Maya Research team
What is Maya1?
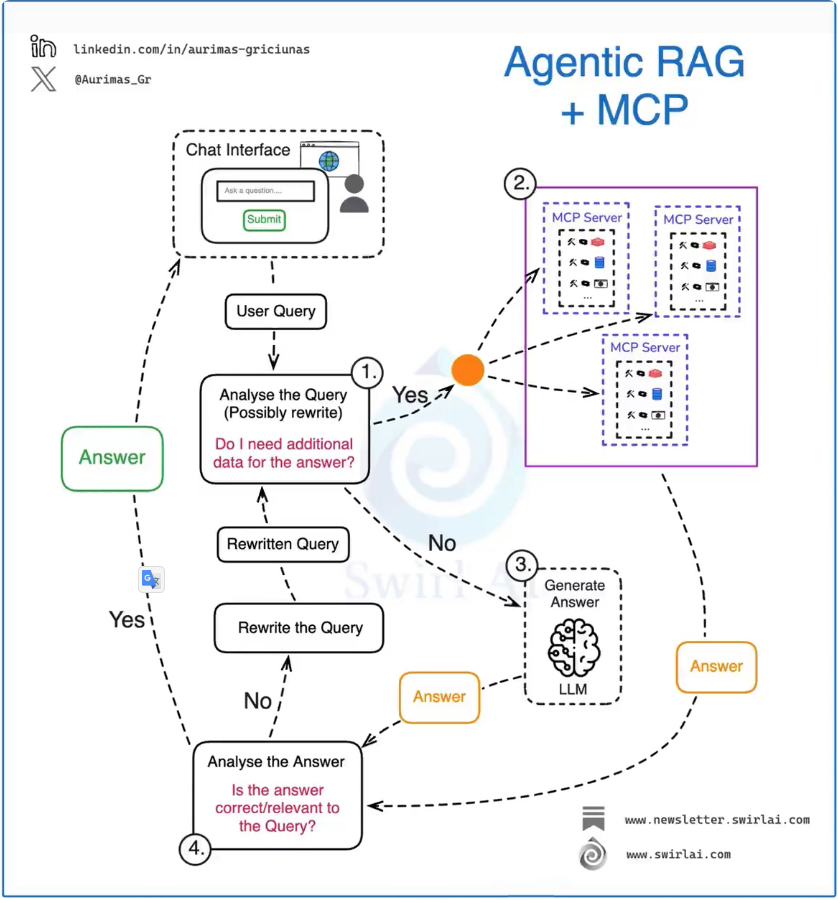
Maya1 is an open-source speech model developed by the Maya Research team, designed specifically for generating emotionally rich voices. The model allows users to design voices through natural language descriptions and supports more than 20 emotional expressions, including laughter, crying, sighing, and more. It can stream audio in real time. Built on a 3-billion-parameter Transformer and the SNAC neural codec, it outputs 24 kHz audio with high quality and low latency. Maya1 is suitable for gaming voiceovers, podcast production, voice assistant development, and other scenarios that require human-like and expressive AI speech.

Key Features of Maya1
-
Natural-language voice design:
Users can define vocal characteristics using simple descriptions (e.g., “a gentle, sincere 30-year-old American woman”) without complex parameter tuning. -
Rich emotional expressions:
Supports 20+ emotions such as <laugh>, <cry>, <sigh>, and more, enabling precise emotional control through text tags. -
Real-time streaming:
Powered by the SNAC neural codec, Maya1 supports ~100 ms latency real-time audio generation, making it ideal for voice assistants and interactive game dialogues. -
Efficient deployment:
The lightweight 3B-parameter Transformer runs on a single GPU and supports the vLLM inference framework, making it suitable for high-concurrency applications.
Technical Principles of Maya1
-
Architecture:
Maya1 uses a 3B-parameter Transformer architecture (similar to Llama) that generates audio token sequences for the SNAC codec, rather than producing raw waveforms directly. -
SNAC codec:
With multi-scale hierarchical compression (≈12 Hz / 23 Hz / 47 Hz), SNAC encodes audio into efficient 7-token frames, achieving high-quality output at a low bitrate (~0.98 kbps). -
Training:
Pretrained on large-scale English speech datasets covering diverse accents and speaking speeds. Studio-grade samples were annotated with 20+ emotion labels and speaker identity tags. -
Voice description:
Uses XML-style attribute descriptions (e.g.,<description="...">) to prevent the model from reading the description text aloud. -
Inference optimization:
Integrates with the vLLM engine and uses Automatic Prefix Caching (APC) to reduce redundant computation. Fully compatible with WebAudio ring buffers for smooth browser-side playback.
Project Repository
HuggingFace Model Hub:
https://huggingface.co/maya-research/maya1
Application Scenarios for Maya1
-
Game development:
Generate emotionally expressive dialogue for NPCs—such as subtle chuckles or anger—improving immersion. -
Podcasts & audiobooks:
Automated narration with multi-character emotional performance, reducing reliance on professional voice actors. -
AI voice assistants:
Build natural and emotionally aware conversational agents capable of expressing empathy, joy, and more. -
Short-form video creation:
Quickly create expressive voiceovers that enhance storytelling and viewer engagement. -
Accessibility:
Provide more human-like screen readers using warm, natural-sounding speech to improve the experience for visually impaired users.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts



No comments yet...