
Google’s latest AI chip matches Nvidia B200, specifically designed for inference models, with the highest configuration capable of performing 42.5 quintillion floating-point operations per second.
Google’s First AI Inference-Specialized TPU Chip is Here, Tailored for Deep-Thinking Models.

Code-named Ironwood, also known as TPU v7, it has a peak FP8 computing power of 4,614 TFlops. Its performance is 3,600 times that of the second-generation TPU in 2017 and 10 times that of the fifth-generation TPU in 2023.
The seventh-generation TPU also features high scalability. The highest-performing cluster can be equipped with 9,216 liquid-cooled chips, with a peak performance of 42.5 ExaFlops, which means it can perform 42,500,000,000,000,000,000 calculations per second.
It is 24 times as powerful as EL Capitan, the world’s most powerful supercomputer at present.
Google said that AI is transitioning from being responsive (providing real-time information for human interpretation) to being able to autonomously generate insights and interpretations.
In the era of reasoning, Agents will actively retrieve and generate data to provide insights and answers in a collaborative manner, rather than just data.
To achieve this, chips that can simultaneously meet huge computing and communication demands, as well as software-hardware collaborative design, are needed.
The software-hardware collaboration of Google AI chips
The reasoning models for deep thinking, represented by Google’s Gemini Thinking and DeepSeek-R1, currently both adopt the MoE (Mixture of Experts) architecture.
Although the number of activated parameters is relatively small, the total number of parameters is enormous. This requires large-scale parallel processing and efficient memory access, and the computational demand far exceeds the capacity of any single chip.
The o1 model is widely speculated to be a Mixture of Experts (MoE) as well, but since OpenAI isn’t exactly “open” (transparent), there’s no definitive conclusion.
The design concept of Google TPU v7 is to perform large-scale tensor operations while minimizing data movement and latency on the chip.
Compared with the previous generation TPU v6, the high-bandwidth memory (HBM) capacity of TPU v7 is 192 GB, six times that of the previous generation. Meanwhile, the single-chip memory bandwidth is increased to 7.2 TBps, 4.5 times that of the previous generation.
The TPU v7 system also features a low-latency, high-bandwidth ICI (Inter-Chip Interconnect) network, supporting fully cluster-scale coordinated synchronous communication. The bidirectional bandwidth has been increased to 1.2 Tbps, which is 1.5 times that of the previous generation.
In terms of energy efficiency, the performance per watt of TPU v7 is also twice that of the previous generation.
After the hardware introduction, let’s move on to the hardware-software collaboration part.
The TPU v7 is equipped with an enhanced SparseCore, which is a dataflow processor designed to handle large embeddings commonly found in advanced sorting and recommendation workloads.
TPU v7 also supports Pathways, a machine learning runtime developed by Google DeepMind, enabling efficient distributed computing across multiple TPU chips.
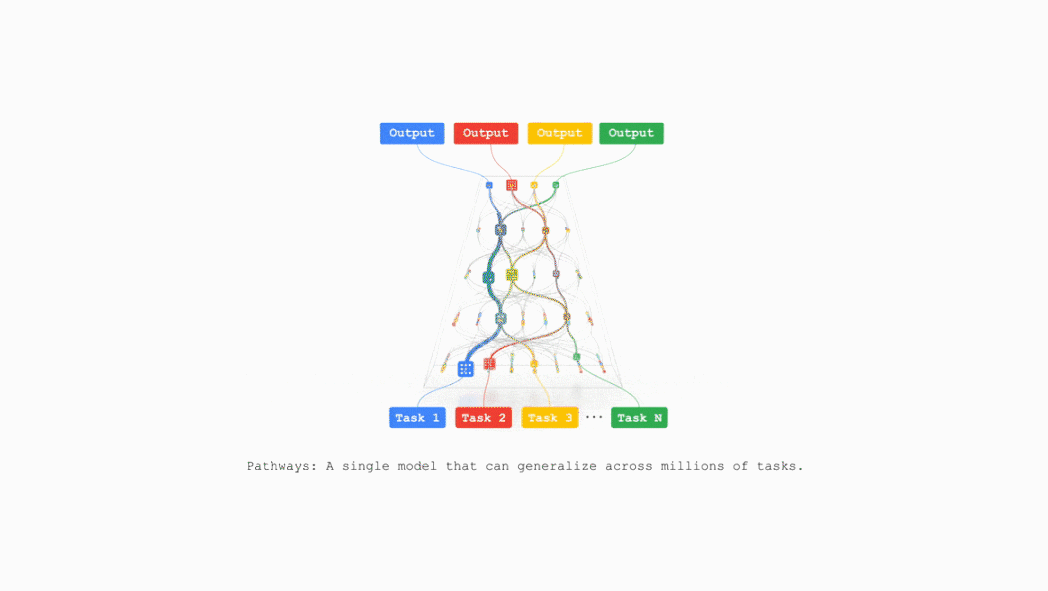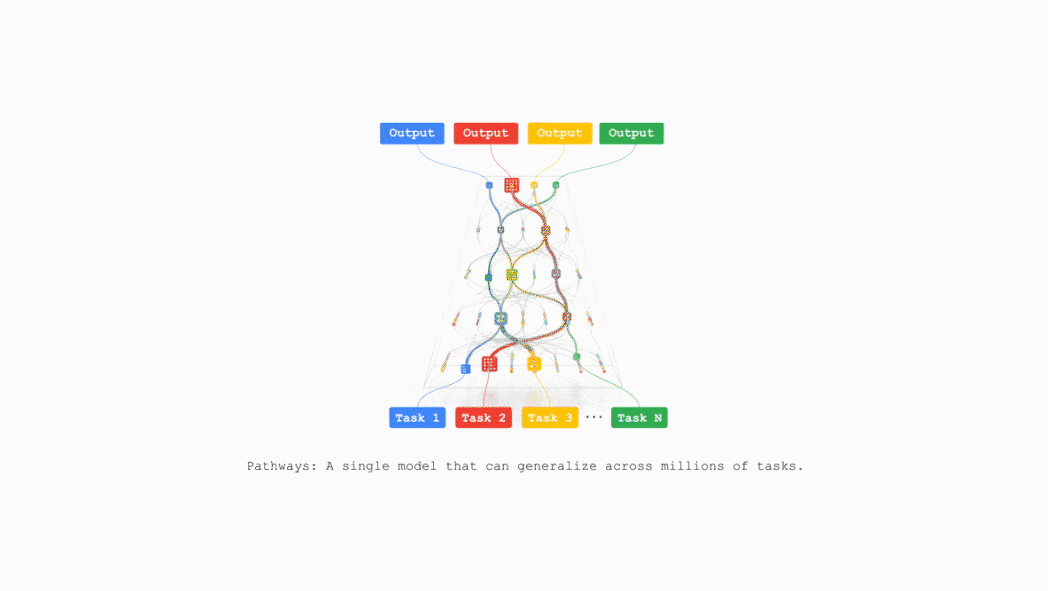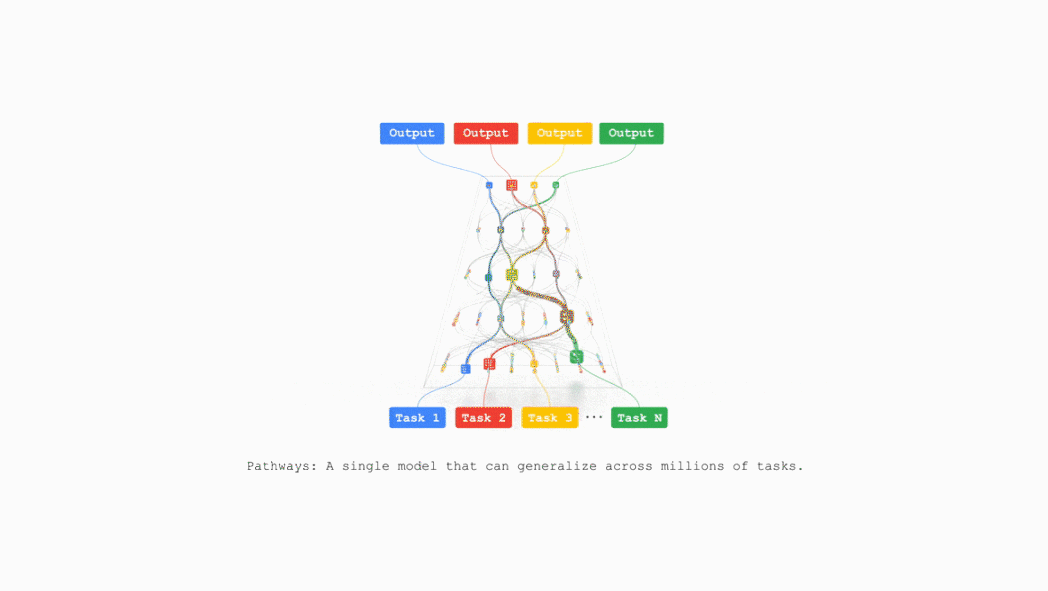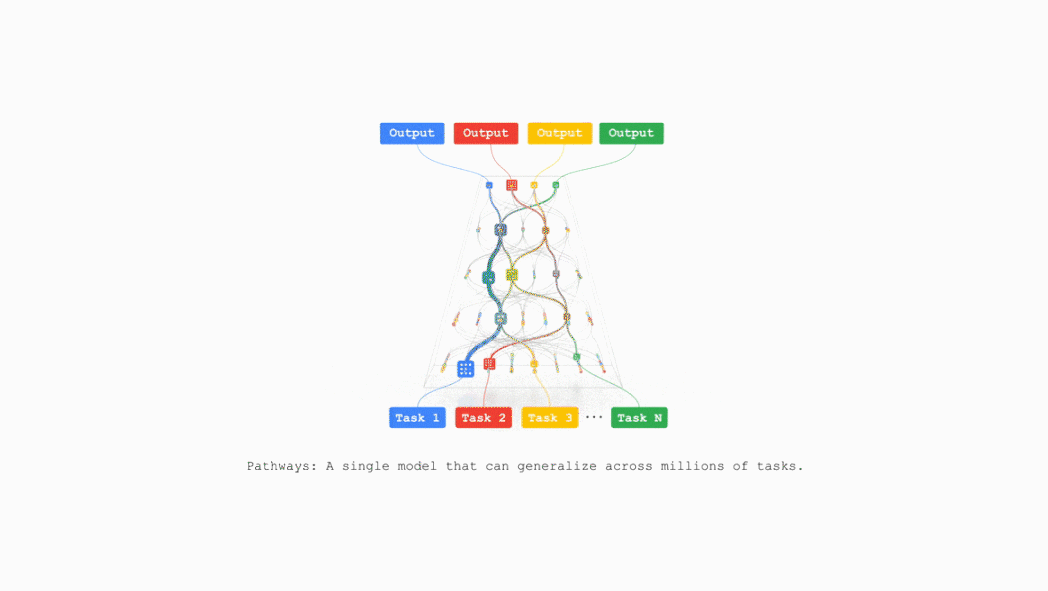
Google plans to integrate TPU v7 into Google Cloud AI supercomputing in the near future, supporting businesses including recommendation algorithms, the Gemini model, and AlphaFold.
Netizens: Nvidia is under great pressure.
After seeing Google’s latest TPU release, netizens in the comments section have been @NVIDIA one after another.
Some people claim that if Google can provide AI model inference services at a lower price, Nvidia’s profits will be severely threatened.
Some people even directly @ various AI robots, asking how this chip compares to Nvidia’s B200.

Let’s make a simple comparison. The FP8 computing power of TPU v7 is 4,614 TFlops, which is slightly higher than the nominal 4.5 PFlops (=4,500 TFlops) of B200. Its memory bandwidth is 7.2 TBps, slightly lower than the 8 TBps of NVIDIA B200. Overall, these two products are basically comparable.
In fact, apart from Google, there are two other major cloud computing companies that are also developing their own inference chips.
Amazon’s Trainium, Inferentia, and Graviton chips are already relatively well-known to everyone, and Microsoft’s MAIA 100 chip can also be accessed through Azure Cloud.

The competition in AI chips is getting fiercer.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts

No comments yet...