
An AI Document Processing Tool That Requires No Complex Text Extraction: No OCR
🧠 What is No OCR?
No OCR is an AI-powered document exploration tool that enables users to upload PDF files and perform search or Q&A across document collections—without extracting plain text manually. Leveraging modern embedding techniques, it supports both textual and visual queries, making it ideal for processing documents that include complex visuals and data.
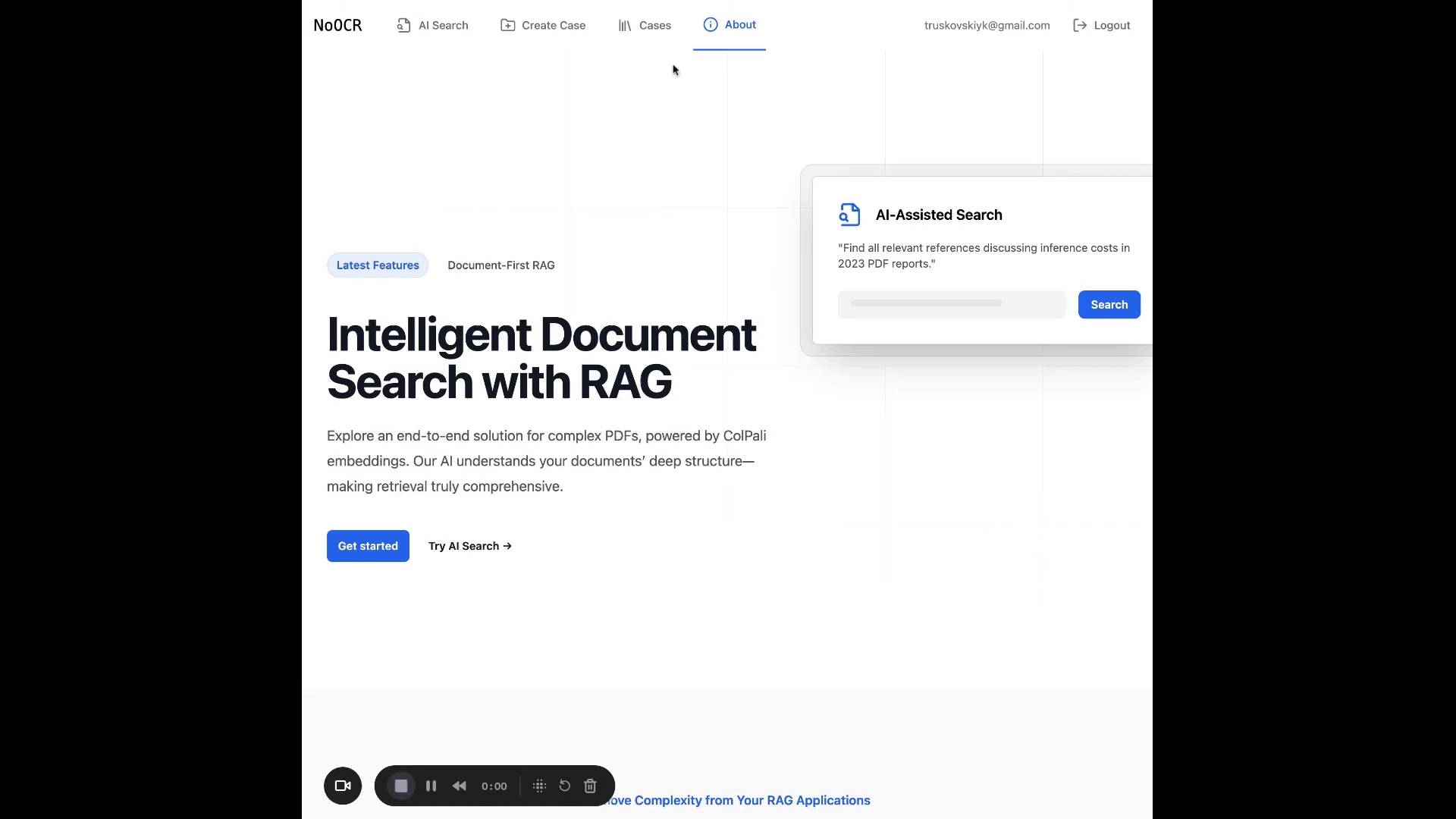
🔧 Key Features
-
Document Collection Management:
Organize and manage sets of PDFs with ease. -
Automated Dataset Construction:
Automatically converts PDFs into Hugging Face-style datasets for seamless processing. -
Vector-Based Search:
Uses LanceDB for fast, embedding-based search across documents, including related visuals. -
Visual Question Answering (VQA):
Integrates with open-source vision-language models like Qwen2-VL to handle advanced image-based queries. -
Docker Support:
Fully containerized with Python backend and React frontend, enabling smooth deployment across environments.
🧪 How It Works
No OCR operates through a streamlined multi-step process:
-
Case Creation:
-
The user uploads a PDF and provides a case name.
-
The system stores the PDF locally and triggers background processing.
-
The PDF is converted into a dataset in Hugging Face format.
-
The dataset is ingested into LanceDB, where collections and datapoints are created.
-
The case is marked as complete, and a success message is displayed.
-
-
Search Flow:
-
The user enters a query and selects a case.
-
The system queries the LanceDB collection using text embeddings.
-
Results are retrieved and linked to the dataset.
-
Visual content is processed using VLLM (Vision-Language Large Models), and answers are returned to the user.
-
This process ensures a seamless, fast, and intelligent interaction with documents of all kinds.
🌐 Project Links
- Project Website: https://no-ocr.com/about
-
GitHub Repository: https://github.com/kyryl-opens-ml/no-ocr
🚀 Application Scenarios
-
Legal Document Analysis:
Extract insights from legal PDFs that include tables, figures, and complex formatting. -
Academic Research:
Explore research papers with embedded diagrams and charts, streamlining literature reviews. -
Enterprise Document Management:
Improve internal documentation search and access efficiency across teams and departments. -
Educational Resource Discovery:
Organize and interact with course materials and references more effectively.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...