UniversalRAG: A Retrieval-Augmented Generation Framework for Multimodal Knowledge Integration
🧠 What is UniversalRAG?
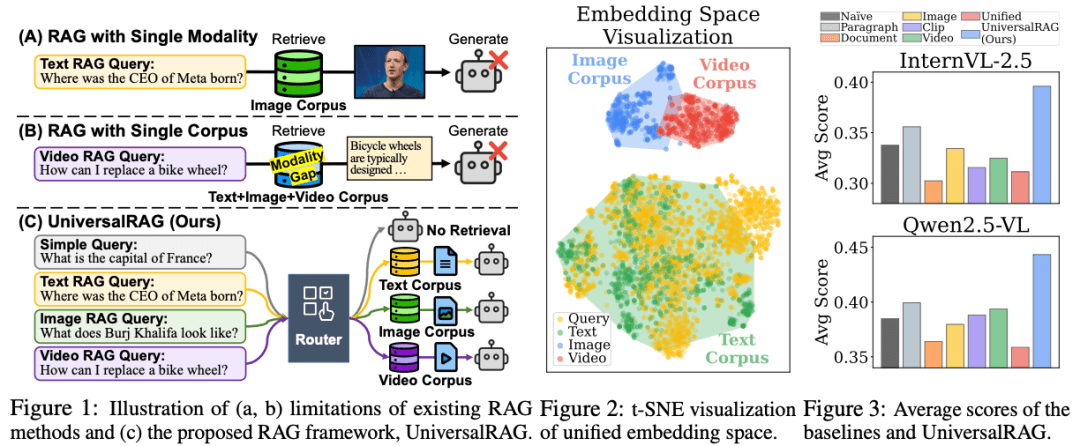
UniversalRAG is an innovative retrieval-augmented generation framework that introduces a modality-aware routing mechanism to dynamically retrieve information from the most appropriate modality-specific corpus. This framework not only accounts for modality differences but also organizes each modality into multiple granular levels, allowing the retrieval process to be fine-tuned according to the complexity and scope of the query, resulting in more precise information integration.
⚙️ Key Features and Advantages
-
Modality-Aware Routing Mechanism: Dynamically selects the most suitable modality-specific corpus for retrieval based on the characteristics of the query, effectively reducing modality gaps.
-
Multigranularity Retrieval: Organizes each modality into multiple granular levels, enabling the retrieval process to be adjusted based on the query’s complexity and scope.
-
Cross-Modal Knowledge Integration: Retrieves information from text, images, videos, and other modality-specific knowledge sources, enabling cross-modal knowledge integration.
-
Efficient Generation: Enhances the accuracy of generated content while maintaining an efficient generation process.
🧬 Technical Principles
The core of UniversalRAG lies in its modality-aware routing mechanism, which dynamically selects the most appropriate modality-specific corpus for retrieval based on the input query’s characteristics. Additionally, the framework organizes each modality into multiple granular levels, allowing the retrieval process to be fine-tuned according to the complexity and scope of the query. This multimodal, multigranular retrieval-augmented generation approach overcomes the limitations of traditional RAG methods in handling diverse queries.
🔗 Project URL
For more information about UniversalRAG, visit the following links:
👉 https://arxiv.org/abs/2504.20734
👉 https://universalrag.github.io/
🚀 Use Cases
-
Multimodal Question Answering Systems: Capable of handling complex queries involving text, images, videos, and other modalities, providing accurate answers.
-
Cross-Modal Information Retrieval: Retrieves information from different modality-specific knowledge bases, enabling cross-modal information integration.
-
Multimodal Content Generation: Generates content based on information from multiple modalities, such as creating reports that combine text and images or video scripts.
-
Intelligent Assistants: Implements multimodal knowledge integration and generation in intelligent assistants, improving the user experience.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts

No comments yet...