OpenF5-TTS: A Lightweight Engine for Commercial-Grade Open Source Speech Synthesis
🔍 What is OpenF5-TTS?
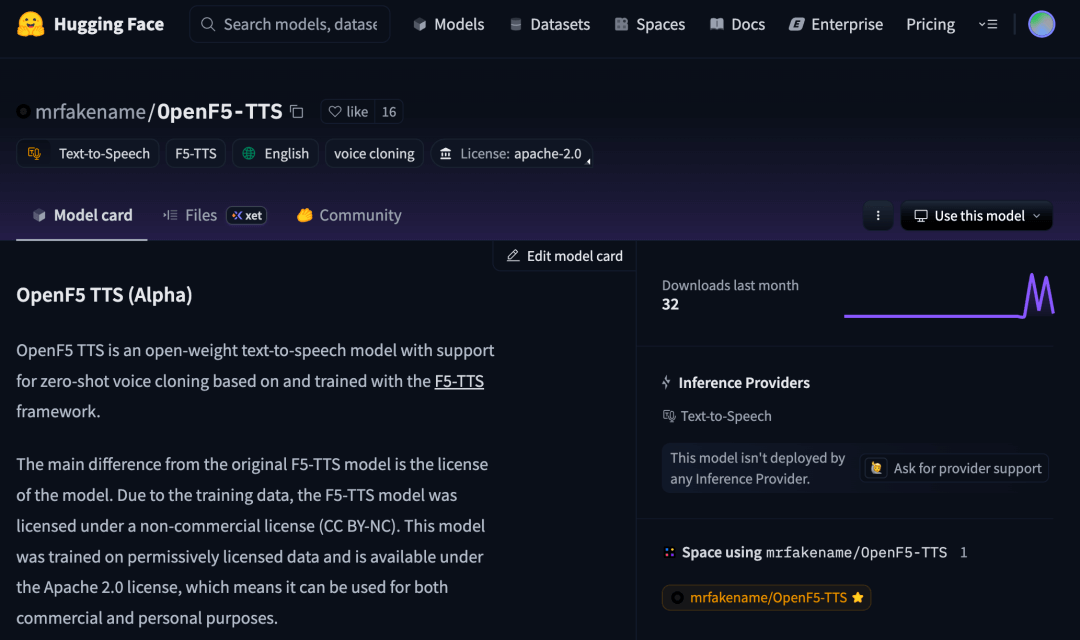
OpenF5-TTS is a community-trained version of Shanghai Jiao Tong University’s open-source F5-TTS model, hosted on Hugging Face by the developer mrfakename. Unlike the original F5-TTS, which uses non-commercial datasets, OpenF5-TTS is trained on data that allows commercial use and is released under the Apache 2.0 license.
Although it is still in the Alpha stage, this version serves as a solid foundation for future fine-tuning and custom model development. While it may not yet match the performance of the original F5-TTS on all fronts, its open and permissive nature makes it ideal for further experimentation and deployment.
⚙️ Key Features
-
Zero-shot voice cloning: Imitate any voice without needing personalized training data.
-
Emotional speech synthesis: Generate expressive speech with a range of emotions and intonations.
-
Controllable speaking speed: Adjust the speed of the synthesized speech based on user preferences.
-
Multilingual potential: Currently trained in English, but the model architecture supports future multilingual extensions.
-
Commercial usability: Licensed under Apache 2.0, making it safe for integration into commercial products and services.
🧠 Technical Foundations
OpenF5-TTS builds upon the architecture of F5-TTS and integrates several advanced technologies:
-
Flow Matching: Transforms a simple probability distribution (like Gaussian) into complex speech distributions for more natural synthesis.
-
Diffusion Transformer (DiT): Serves as the model’s backbone, denoising sequences progressively to generate clear, high-quality speech.
-
ConvNeXt V2: Refines the text embeddings, improving alignment with the speech output and enhancing synthesis quality.
-
Sway Sampling: A flow-based sampling strategy that applies non-uniform sampling during inference to better capture voice characteristics, especially at the start of generation.
The current version was trained on the Emilia-YODAS dataset for 1 million steps, focusing on English-language synthesis. Future versions are expected to bring substantial improvements in voice realism and emotional depth.
🔗 Project Links
-
Hugging Face Model Page: https://huggingface.co/mrfakename/OpenF5-TTS
-
GitHub (F5-TTS original repo): https://github.com/SWivid/F5-TTS
-
Online Demo (Spaces): https://huggingface.co/spaces/mrfakename/E2-F5-TTS
-
arXiv Paper: https://arxiv.org/abs/2410.06885
🎯 Use Cases
-
Voice assistants & chatbots: Provide responsive, natural-sounding voice feedback for smart devices and web services.
-
Audiobooks & podcasts: Convert written content into engaging audio, ideal for visually impaired users or on-the-go listeners.
-
Language learning & education: Help learners practice pronunciation and listening skills using synthesized native-like speech.
-
Media & journalism: Automate the production of audio versions of news articles for online distribution or radio.
-
Customer service automation: Enable real-time voice responses in service platforms to enhance customer interactions.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...