OmniGen2 — A Creative Leap in Multimodal AI from VectorSpaceLab
What is OmniGen2?
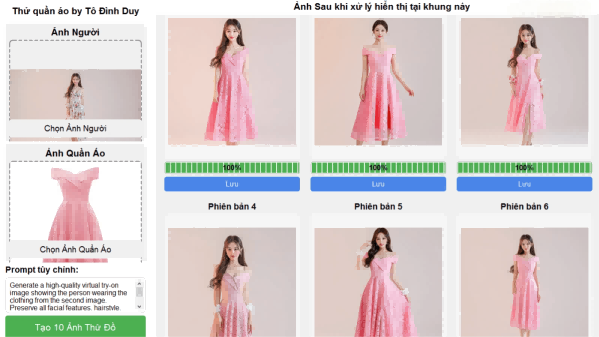
OmniGen2 is an open-source, advanced multimodal generation framework developed by VectorSpaceLab. As the successor to the original OmniGen, it significantly improves both visual understanding and image generation through a unified architecture. The model introduces dual-path processing for text and images, a decoupled image tokenizer, and a groundbreaking “multimodal reflection” mechanism that allows it to evaluate and refine its own outputs. Designed for flexibility and precision, OmniGen2 supports text-to-image generation, instruction-guided image editing, and in-context generation, all within a single framework.

Key Features of OmniGen2
-
Text-to-Image Generation: Generate high-quality, semantically aligned images from textual prompts with high compositional accuracy.
-
Instruction-Based Image Editing: Precisely edit images using natural language instructions—modify objects, styles, scenes, or layouts with simple prompts.
-
In-Context Generation: Seamlessly integrate elements from reference images (e.g., people, objects) into new visual contexts while preserving identity and spatial coherence.
-
Multimodal Reflection: Employs a self-assessment loop to evaluate and improve its own outputs, leading to enhanced realism and controllability.
-
Visual Comprehension: Retains strong image understanding capabilities inherited from Qwen-VL-2.5, enabling tasks like VQA, captioning, and grounding.
Technical Foundations
-
Dual-Path Architecture: Text and image inputs are processed through independent pathways—text via a transformer encoder and frozen vision-language model, and images via a VAE and diffusion decoder—allowing specialized handling of each modality.
-
Omni-RoPE Positional Encoding: Embeds modality, sequence, and spatial coordinate information to support precise region-level editing and compositional understanding.
-
Reflection Mechanism: A loop powered by an LLM critiques the model’s output, identifies errors or inconsistencies, and refines the generation iteratively.
-
Custom Instruction Datasets: Includes specialized datasets for instruction-following, in-context composition, and multimodal self-reflection, improving generalization and user control.
Project Links
-
GitHub Repository: https://github.com/VectorSpaceLab/OmniGen2
-
Project Homepage/Demo: https://vectorspacelab.github.io/OmniGen2/
-
Technical Paper (arXiv): https://arxiv.org/abs/2506.18871
Application Scenarios
-
Creative Image Generation: Produce illustrations, concept art, marketing visuals, or storybook scenes from rich text prompts.
-
Precise Image Editing: Make localized and style-consistent edits with natural language, such as “replace the tree with a fountain” or “turn daytime into sunset.”
-
Character and Object Consistency: Maintain subject identity across multiple images or scenes, ideal for animation, storytelling, and digital avatars.
-
Design Prototyping with Iterative Feedback: Use self-refinement to generate and improve visual content over multiple iterations.
-
AI Research and Evaluation: Includes the OmniContext benchmark to assess compositional alignment and in-context generation accuracy.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts



No comments yet...