
ZeroSearch – An open-source large model search engine framework by Alibaba Tongyi
What is ZeroSearch?
ZeroSearch is an innovative open-source large model search engine framework developed by Alibaba Tongyi Lab. It enhances the search capabilities of large models using reinforcement learning, without the need to interact with real search engines. The framework is based on the pre-trained knowledge of large models, which is transformed into a retrieval module. This module generates relevant or noisy documents based on queries, dynamically controlling the quality of the generated documents. ZeroSearch outperforms Google Search on several question-answer datasets, significantly reducing training costs (by over 80%). Through lightweight supervised fine-tuning and a curriculum learning mechanism, ZeroSearch gradually enhances the model’s inference abilities. It supports various reinforcement learning algorithms and is highly scalable and versatile.
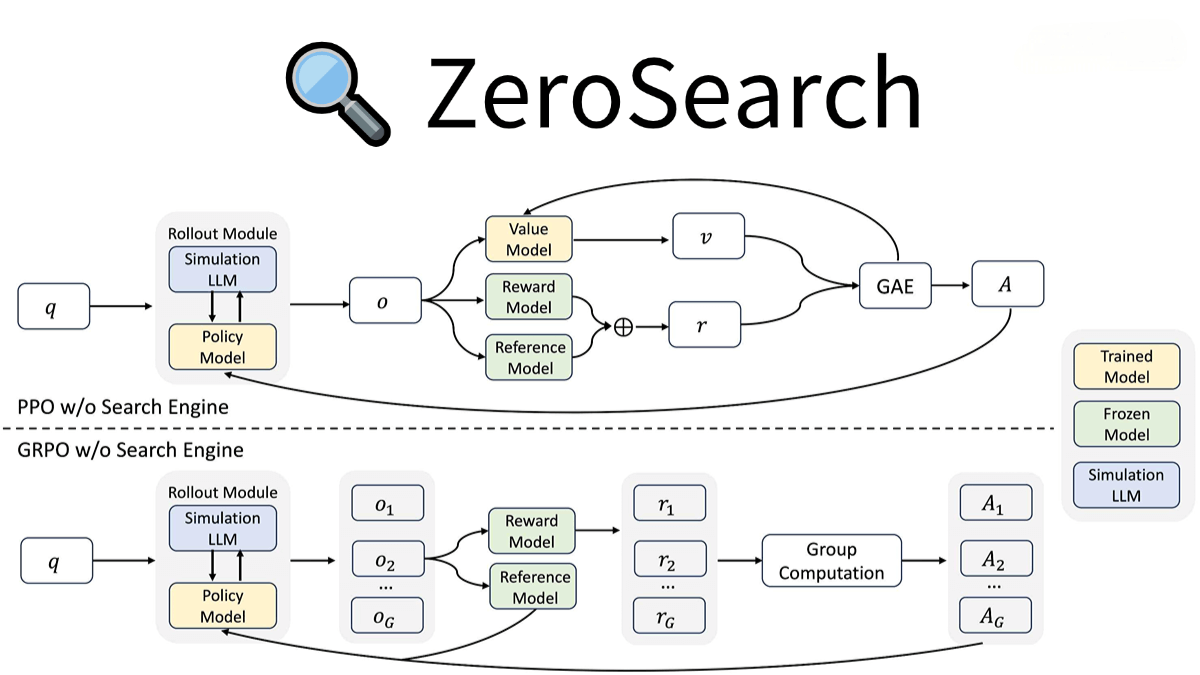
Main Features of ZeroSearch
-
No Need for Real Search Engine Interaction: Simulates a search engine to enhance the search capabilities of large models, avoiding interactions with real search engines (such as Google), thus reducing costs and uncontrollable factors.
-
Dynamic Control of Document Quality: Supports the generation of relevant or noisy documents. By adjusting keywords in the prompts, it flexibly controls the quality of generated documents, providing diverse retrieval scenarios for training.
-
Cost Reduction: Compared to reinforcement learning training using real search engines, ZeroSearch significantly reduces training costs (by more than 80%), making large-scale training more feasible.
-
Supports Various Models and Algorithms: Compatible with large models of different parameter scales (e.g., 3B, 7B, 14B) and supports various reinforcement learning algorithms (such as PPO, GRPO).
Technical Principles of ZeroSearch
-
Simulated Search Engine: Transforms the large model’s pre-trained knowledge into a simulated search engine, generating relevant or noisy documents based on queries, replacing real search engines.
-
Lightweight Supervised Fine-Tuning: Fine-tunes large models with a small amount of labeled data to generate high- or low-quality documents, adapting to different training needs.
-
Curriculum Learning Mechanism: Gradually increases the noise level of documents during training, allowing the model to start with simpler scenarios and gradually adapt to more challenging tasks, improving inference capabilities.
-
F1 Score-Based Reward Mechanism: Uses the F1 score as a reward signal, focusing on answer accuracy, ensuring that the generated answers match the real answers as closely as possible.
-
Multi-Round Interaction Templates: Defines clear reasoning, search, and answering phases, guiding the model step-by-step with structured labels (such as <think>, <search>, <answer>) to complete tasks.
Project Links
-
Official Website: https://alibaba-nlp.github.io/ZeroSearch/
-
GitHub Repository: https://github.com/Alibaba-nlp/ZeroSearch
-
HuggingFace Model Repository: https://huggingface.co/collections/sunhaonlp/zerosearch
-
arXiv Technical Paper: https://arxiv.org/pdf/2505.04588
Application Scenarios of ZeroSearch
-
Intelligent Question-Answering Systems: Quickly and accurately answering user queries, suitable for intelligent customer service and virtual assistants.
-
Content Creation: Assists creators in gathering information, generating drafts, or providing inspiration, applicable to news, copywriting, and academic writing.
-
Education and Learning: Provides instant answers to students, supporting online education and intelligent tutoring.
-
Enterprise Knowledge Management: Helps employees quickly retrieve internal company resources, improving work efficiency.
-
Research and Development: Provides researchers with the latest research findings, accelerating the research process.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...