
What is FastVLM?
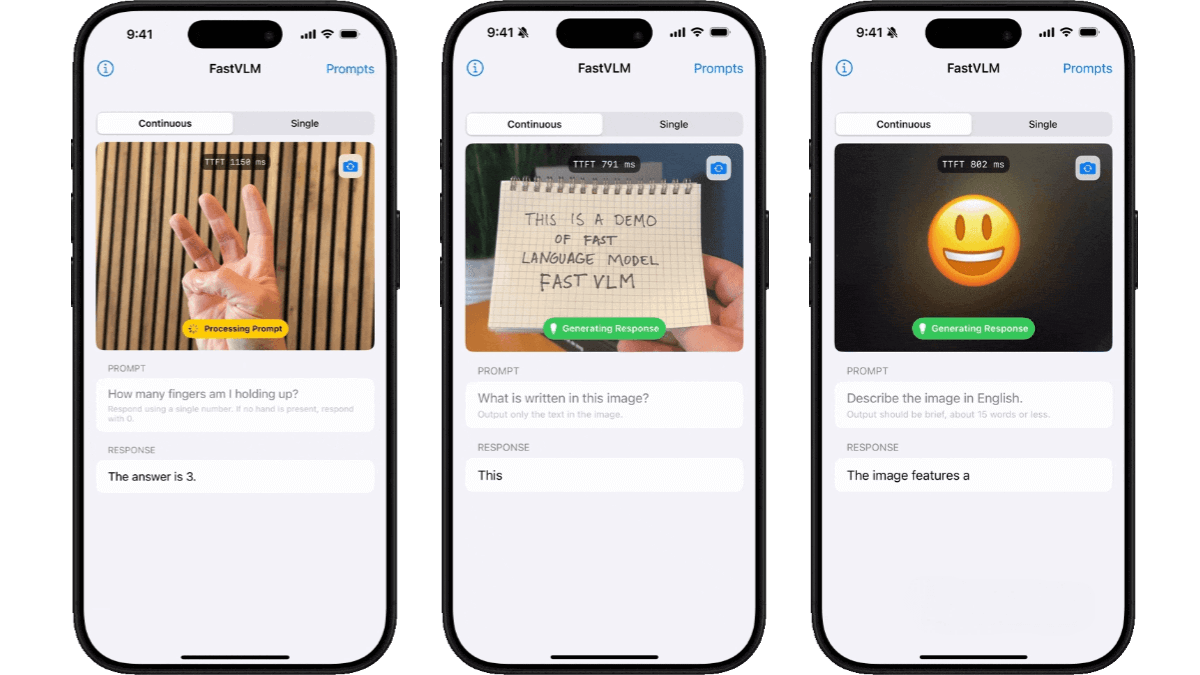
FastVLM is an efficient vision-language model (VLM) developed by Apple, designed to enhance the performance and speed of high-resolution image processing. The model introduces FastViTHD, a novel hybrid vision encoder that significantly reduces the number of visual tokens and encoding time. While maintaining performance comparable to existing VLMs, FastVLM greatly accelerates processing—for example, under LLaVA-1.5 settings, it reduces the Time-To-First-Token (TTFT) by 3.2x compared to other models. FastVLM demonstrates strong results across multiple VLM benchmarks with a smaller model size and less training data, showcasing its efficiency and practicality in multimodal understanding tasks.
Key Features of FastVLM
-
Efficient High-Resolution Image Encoding: Quickly transforms high-resolution images into visual tokens, reducing both encoding time and token count.
-
Enhanced VLM Performance: Significantly shortens time-to-first-token (TTFT) while maintaining comparable performance to state-of-the-art models.
-
Simplified Model Design: Eliminates the need for additional token pruning steps, streamlining the visual encoder architecture.
Technical Principles of FastVLM
-
Hybrid Vision Encoder (FastViTHD):
At the core of FastVLM, FastViTHD combines the strengths of convolutional layers and Transformer blocks. The convolutional layers efficiently handle high-resolution images by downsampling early, reducing the token count. Transformer blocks then extract high-quality visual features for large language models (LLMs). The FastViTHD architecture is staged with varying depths and embedding dimensions, e.g., depth = [2, 12, 24, 4, 2] and embed dims = [96, 192, 384, 768, 1536]. -
Optimized Architecture Design:
FastVLM includes an extra stage that downsamples tensors before they reach the self-attention layers, unlike simply scaling up traditional FastViT. As a result, self-attention only operates on already downsampled tensors—e.g., while typical hybrid models downsample by a factor of 16, FastVLM achieves a 64x downsampling for the widest MLP layer, dramatically reducing visual encoding latency. -
Collaboration with LLMs:
FastVLM connects the visual encoder to an LLM using a projection layer (or connector module). Visual tokens from the encoder are transformed into a format suitable for the LLM, which then integrates both visual tokens and textual inputs to generate outputs. This collaborative design ensures effective fusion of vision and language for multimodal tasks.
Project Resources for FastVLM
-
GitHub Repository: https://github.com/apple/ml-fastvlm
-
arXiv Technical Paper: https://www.arxiv.org/pdf/2412.13303
Application Scenarios for FastVLM
-
Visual Question Answering (VQA): Quickly interprets images to answer related questions.
-
Image-Text Matching: Assesses the consistency between an image and its textual description.
-
Document Understanding: Parses and comprehends text content within images.
-
Image Captioning: Automatically generates descriptive text for images.
-
Multimodal Recommendation: Delivers accurate recommendations by combining image and text information.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts



No comments yet...