3DTown – Columbia University, in collaboration with Cybever AI and others, has launched a framework for generating 3D town scenes from single – view images
What is 3DTown?
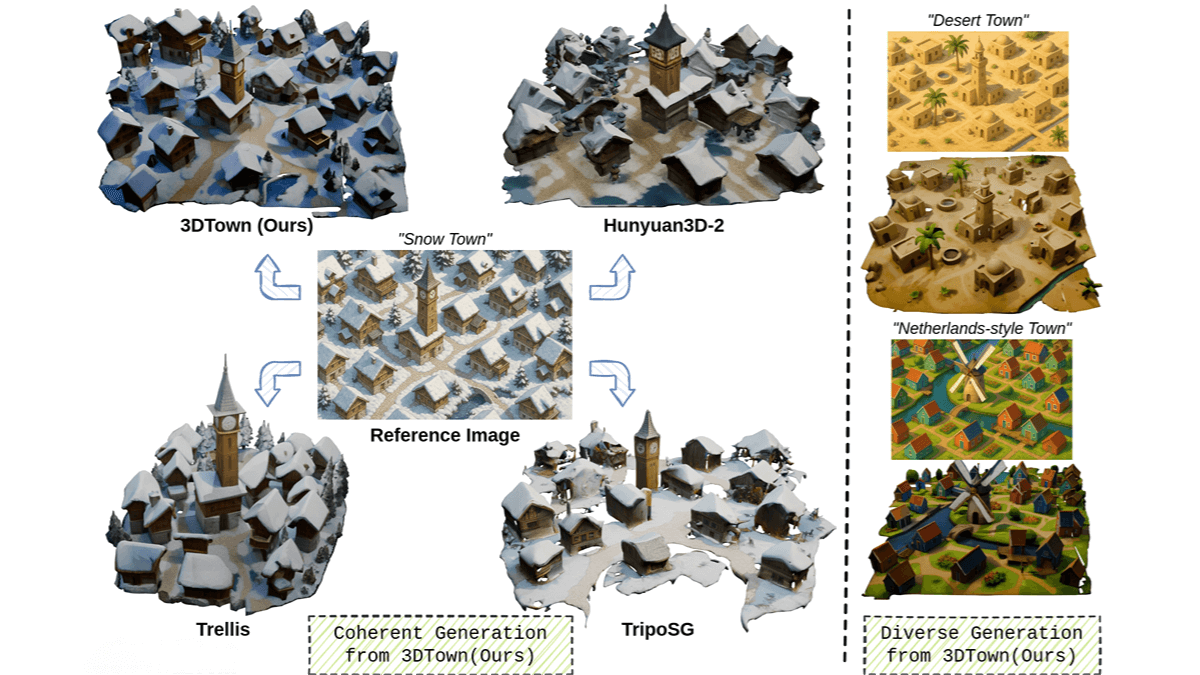
3DTown is a framework developed by Columbia University in collaboration with Cybever AI and other institutions, designed to generate 3D town scenes from a single top-down image. The framework utilizes region-based generation and spatially-aware 3D inpainting techniques. It divides the input image into overlapping regions, generates 3D content for each region using a pre-trained 3D object generator, and applies a masked rectified flow-based inpainting process to fill in missing geometry while preserving structural continuity. 3DTown supports the creation of coherent 3D scenes with high geometric quality and texture fidelity, outperforming existing state-of-the-art methods across diverse scene styles.
Key Features of 3DTown
-
Diverse 3D Scene Generation: Supports the creation of scenes in various styles and layouts, such as “snow towns” or “desert villages.”
-
Consistency in Geometry and Texture: The generated 3D scenes maintain high fidelity in both geometric structure and texture compared to the input image.
-
Efficient Handling of Complex Scenes: Capable of processing complex environments while avoiding geometric distortions and layout artifacts.
Technical Overview of 3DTown
-
Region-Based Generation: The input image is divided into overlapping regions. Each region is independently processed to generate 3D content using a pre-trained 3D object generator. These regions are then fused together into a coherent global 3D scene, improving local alignment and resolution.
-
Spatially-Aware 3D Inpainting: The initial 3D structure is approximated using monocular depth estimation and landmark detection. The Masked Rectified Flow (MRF) technique is used to fill in missing geometry while maintaining continuity with known areas. A two-stage MRF pipeline generates sparse structures and structured latent representations to ensure global consistency.
-
Structured Latent Representation: Builds 3D scenes using structured latent representations, including position indices and latent feature vectors. These are progressively generated using a sparse structure generator and structured latent generator.
-
Modular Design: Adopts a modular approach by decomposing the complex task of 3D scene generation into multiple sub-tasks, which are solved independently and then integrated.
Project Links
-
Official Website: https://eric-ai-lab.github.io/3dtown.github.io/
-
arXiv Paper: https://arxiv.org/pdf/2505.15765
Application Scenarios for 3DTown
-
Virtual World Building: Quickly generate virtual towns or environments for use in Virtual Reality (VR) and Augmented Reality (AR) applications.
-
Game Development: Provides game designers with a powerful tool to generate complex 3D scenes from simple top-down views, saving time and reducing development costs.
-
Robotics Simulation: Creates realistic 3D environments for training robots, enhancing their navigation and interaction capabilities in complex settings.
-
Digital Content Creation: Helps artists and designers rapidly prototype 3D scenes, accelerating the creative process and improving productivity.
-
Architecture and Urban Planning: Converts conceptual sketches into 3D architectural models and city layouts, aiding in planning, presentation, and evaluation of design proposals.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts


No comments yet...