SmolVLA – A lightweight robotics model open-sourced by Hugging Face
What is SmolVLA?
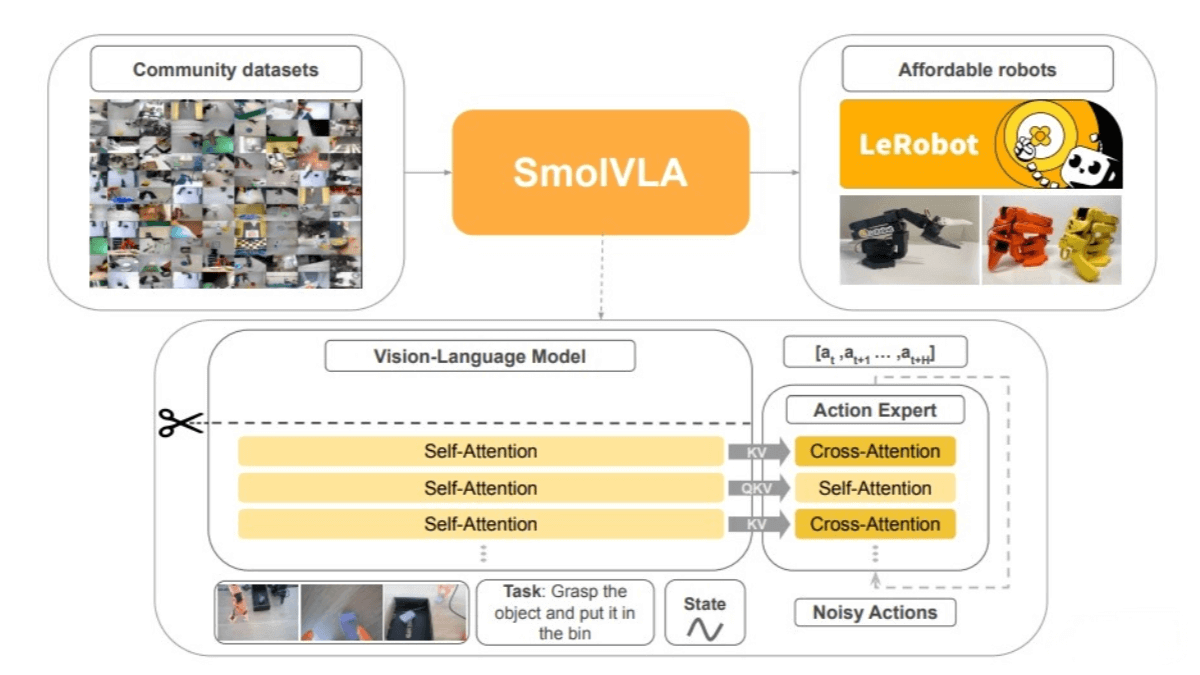
SmolVLA is an open-source lightweight Vision-Language-Action (VLA) model developed by Hugging Face, designed for cost-efficient robotics. With just 450 million parameters, the model is compact, capable of running on CPUs, trainable on a single consumer-grade GPU, and even deployable on a MacBook. SmolVLA is trained entirely on open-source datasets labeled as “lerobot.”
Key Features of SmolVLA
Multimodal Input Processing:
SmolVLA can handle various inputs, including multiple images, language instructions, and robot state information. It extracts visual features using a vision encoder, tokenizes language instructions for input into a decoder, and projects proprioceptive state data through a linear layer into a token aligned with the language model’s token dimension.
Action Sequence Generation:
The model includes an “action expert” module—a lightweight Transformer—that generates future robot action sequences based on outputs from the Vision-Language Model (VLM). It is trained using a flow matching technique, guiding noisy samples to regress toward the true data distribution, enabling precise real-time control.
Efficient Inference and Asynchronous Execution:
SmolVLA introduces an asynchronous inference stack that separates action execution from perception and prediction. This allows for faster and more responsive control, enabling robots to react quickly in dynamic environments, improving response time and task throughput.
Technical Principles of SmolVLA
Vision-Language Model (VLM):
SmolVLA uses SmolVLM2 as its core VLM, optimized for multi-image input. It consists of a SigLIP vision encoder and a SmolLM2 language decoder. Visual tokens are extracted via the encoder, language instructions are tokenized and input directly to the decoder, and state information is projected to match the decoder’s token dimension. The decoder processes the concatenated image, language, and state tokens to produce features passed to the action expert.
Action Expert:
This is a lightweight Transformer with around 100 million parameters. It generates future robot action sequences based on VLM outputs. Trained using flow matching, it enables precise real-time control by learning to regress from noisy samples to the true data distribution.
Visual Token Reduction:
To improve efficiency, SmolVLA limits the number of visual tokens per frame to 64, significantly reducing processing overhead.
Layer Skipping for Faster Inference:
SmolVLA accelerates inference by skipping half of the layers in the VLM during computation, effectively halving computational costs while maintaining strong performance.
Interleaved Attention Layers:
Unlike traditional VLA architectures, SmolVLA alternates between Cross-Attention (CA) and Self-Attention (SA) layers. This improves multimodal information integration and speeds up inference.
Asynchronous Inference:
SmolVLA allows the robot’s “hands” and “eyes” to work independently. Under this strategy, the robot can execute current actions while simultaneously processing new observations and predicting the next actions, eliminating inference latency and increasing control frequency.
Project Links for SmolVLA
-
Hugging Face Model Hub: https://huggingface.co/lerobot/smolvla_base
-
arXiv Technical Paper: https://arxiv.org/pdf/2506.01844
Application Scenarios for SmolVLA
Object Grasping and Placement:
SmolVLA can control robotic arms to perform complex grasping and placement tasks. For example, on an industrial production line, a robot can use visual input and language commands to accurately pick up parts and place them in designated locations.
Household Tasks:
SmolVLA can be used in home service robots to help with various household chores. For instance, a robot can follow natural language instructions to identify and clean up clutter or place items in specified areas.
Goods Handling:
In logistics warehouses, SmolVLA can control robots to handle cargo. Robots can identify the position and shape of goods through visual input, combine this with language commands, and generate optimal handling paths and action sequences to improve efficiency and accuracy.
Robotics Education:
SmolVLA can serve as an educational tool for robotics, helping students and researchers better understand and develop robotic technologies.
© Copyright Notice
The copyright of the article belongs to the author. Please do not reprint without permission.
Related Posts




No comments yet...